
Certains projets gèrent un volume de données conséquent. Pour analyser ces données, une API de recherche est parfois nécessaire.
Techniquement, implémenter des web services pour chaque variante de recherche est possible. Mais il reste essentiel de prendre en compte les critères fondamentaux telles que la qualité du code ou la maintenabilité des programmes.
L’objectif de cet article est de découvrir comment concevoir une API de recherche optimisée tout en respectant le principe de développement DRY (Don’t Repeat Yourself) et KISS (Keep It Simple, Stupid) .
Prérequis
- une connaissance de l’architecture REST API et de ses normes.
- une connaissance du framework Spring Boot.
Un peu de théorie
Un certain contrôle sur la façon d’extraire des enregistrements issus de la base de données est assuré par l’ajout des fonctionnalités suivantes :
- Filtrage : utile pour affiner les résultats de la requête par des paramètres spécifiques.
GET /cars?country=USA GET /cars?creation_date=2019–11–11
- Tri : permet essentiellement de trier les résultats par ordre croissant ou décroissant, selon un ou plusieurs paramètres choisis.
GET /cars?sort=creation_date,asc GET /cars?sort=creation_date,desc
- Pagination : utilise
sizepour réduire le nombre de résultats affichés à un nombre spécifique etoffsetpour spécifier la partie du résultat à afficher.
GET /cars?size=100&offset=2
Ce qui donnerai :
GET /cars?country=USA&sort=creation_date:desc&limit=100&offset=2
Cette requête retourne une liste de 100 voitures américaines, triée par date de création dans l’ordre décroissant. Ici nous ne récupérons que la deuxième partie du résultat, ce qui ce traduit par les lignes de 101 à 200 du résultat de filtrage globale.
Cas d’utilisation
Supposons que nous sommes invités à maintenir un projet Spring Boot : une API REST de gestion d’un parc de voitures. Le principe du code existant définit les actions CRUD de base : création, lecture/récupération, mise à jour et suppression.
Nous voulons pouvoir récupérer les voitures par fabricant et modèle ainsi que leur type; Tout en prenant en compte des filtres facultatifs.
Avec Spring Data, il est simple de créer un repository avec des méthodes de recherche personnalisées. Ensuite, nous pouvons utiliser ce repository dans le contrôleur. Nous devons gérer manuellement les paramètres de requête pour déterminer la méthode de repository appropriée.
Bien que ce ne soit pas un gros problème pour un seul paramètre de requête, cette approche devient verbeuse lorsqu’il y a plus de variables (5 attributs dans la classe Car.java par exemple). Ce n’est donc pas une approche optimale.
package com.mak.springbootefficientsearchapi.entity;
import lombok.AllArgsConstructor;
import lombok.Getter;
import lombok.NoArgsConstructor;
import lombok.Setter;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import javax.validation.constraints.NotNull;
import java.time.LocalDate;
@Getter
@Setter
@Entity
@NoArgsConstructor
@AllArgsConstructor
public class Car {
@Id
@Column(name = "id", nullable = false)
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer id;
@NotNull
@Column(nullable = false)
private String manufacturer;
@NotNull
@Column(nullable = false)
private String model;
@NotNull
@Column(nullable = false)
private String type;
@NotNull
@Column(nullable = false)
private String country;
@NotNull
@Column(nullable = false)
private LocalDate createDate;
}
Don’t work hard, work smarter
La solution à cette problématique repose sur les trois éléments suivants : les annotations, Spring Data et une librairie Specification Argument Resolver.
Nous pouvons tirer un avantage considérable de ces composants :
Tout d’abord, nous n’avons pas à deviner toutes les méthodes possibles dans le repository. C’est à Spring Data de déduire quel prédicat est sélectionné grâce à son interface Specification et aux annotations.
D’un autre côté, nous n’avons pas besoin de vérifier les paramètres de chaque requête manuellement. Pour cela Spécification Argument Resolver, comme son nom l’indique, extrait les paramètres et les valeurs associées à partir de l’URI.
En conséquence, nous réduisons la complexité du code (pas d’explosion de méthode de repository, pas de code fastidieux dans le contrôleur, etc)
specification-arg-resolver
Ajoutons la dépendance suivante:
<dependency>
<groupId>net.kaczmarzyk</groupId>
<artifactId>specification-arg-resolver</artifactId>
<version>2.1.1</version>
</dependency>
Cette bibliothèque génère des spécifications à la volée, basées sur des annotations.
Ensuite, surchargeons la méthode addArgumentResolvers qui implémente l’interface WebMvcConfigurer.
package com.mak.springbootefficientsearchapi.configuration;
import net.kaczmarzyk.spring.data.jpa.web.SpecificationArgumentResolver;
import org.springframework.context.annotation.Configuration;
import org.springframework.transaction.annotation.EnableTransactionManagement;
import org.springframework.web.method.support.HandlerMethodArgumentResolver;
import org.springframework.web.servlet.config.annotation.WebMvcConfigurer;
import java.util.List;
@Configuration
@EnableTransactionManagement
public class JpaConfiguration implements WebMvcConfigurer {
@Override
public void addArgumentResolvers(List<HandlerMethodArgumentResolver> argumentResolvers) {
argumentResolvers.add(new SpecificationArgumentResolver());
}
}
Grâce à cet ArgumentResolver, nous n’avons pas besoin d’écrire d’implémentation de spécifications. Elles seront générées au moment de l’exécution, sur la base de quelques annotations que nous devons ajouter au contrôleur:
@Transactional
@GetMapping(value = "", produces = MediaType.APPLICATION_JSON_VALUE)
@ResponseStatus(HttpStatus.OK)
public ResponseEntity<List<Car>> get(
@And({
@Spec(path = "manufacturer", params = "manufacturer", spec = Like.class),
@Spec(path = "model", params = "model", spec = Like.class),
@Spec(path = "country", params = "country", spec = In.class),
@Spec(path = "type", params = "type", spec = Like.class),
@Spec(path = "createDate", params = "createDate", spec = Equal.class),
@Spec(path = "createDate", params = {"createDateGt", "createDateLt"}, spec = Between.class)
}) Specification<Car> spec,
Sort sort,
@RequestHeader HttpHeaders headers) {
final PagingResponse response = carService.get(spec, headers, sort);
return new ResponseEntity<>(response.getElements(), returnHttpHeaders(response), HttpStatus.OK);
}
Maintenant, implémentons le service associé :
/**
* get element using Criteria.
*
* @param spec *
* @param headers pagination data
* @param sort sort criteria
* @return retrieve elements with pagination
*/
public PagingResponse get(Specification<Car> spec, HttpHeaders headers, Sort sort) {
if (isRequestPaged(headers)) {
return get(spec, buildPageRequest(headers, sort));
} else {
final List<Car> entities = get(spec, sort);
return new PagingResponse((long) entities.size(), 0L, 0L, 0L, 0L, entities);
}
}
Comme vous le constatez, le service dispatche ces données au repository pour assurer le tri et la pagination.
Voici maintenant à quoi ressemble notre repository :
import com.mak.springbootefficientsearchapi.entity.Car;
import org.springframework.data.jpa.repository.JpaSpecificationExecutor;
import org.springframework.data.repository.PagingAndSortingRepository;
import org.springframework.stereotype.Repository;
@Repository
public interface CarRepository extends PagingAndSortingRepository<Car, Integer>, JpaSpecificationExecutor<Car> {
}
Spring Data nous fournie deux interfaces generiques :
JpaSpecificationExecutorpermet d’exécuter les spécifications générées précédemment.PagingAndSortingRepositorypermet de paginer et de trier les ressources obtenus.
Le code source du projet est disponible ici. Vous y trouverez un fichier d’init des voitures ainsi qu’un export de la collection Postman utilisée ci-dessous.
Exemples d’utilisation de l’API
Notez qu’avec une seule méthode, nous pouvons couvrir plusieurs cas :
Obtenir la liste totale des voitures
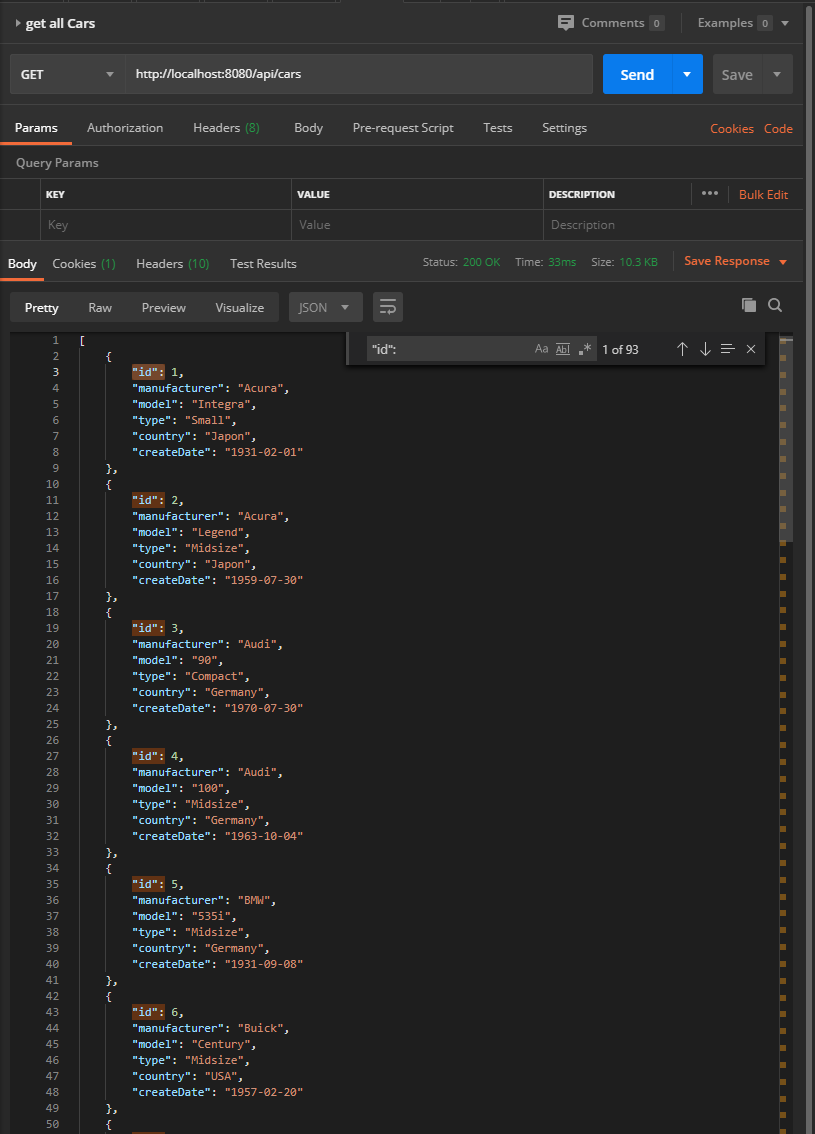
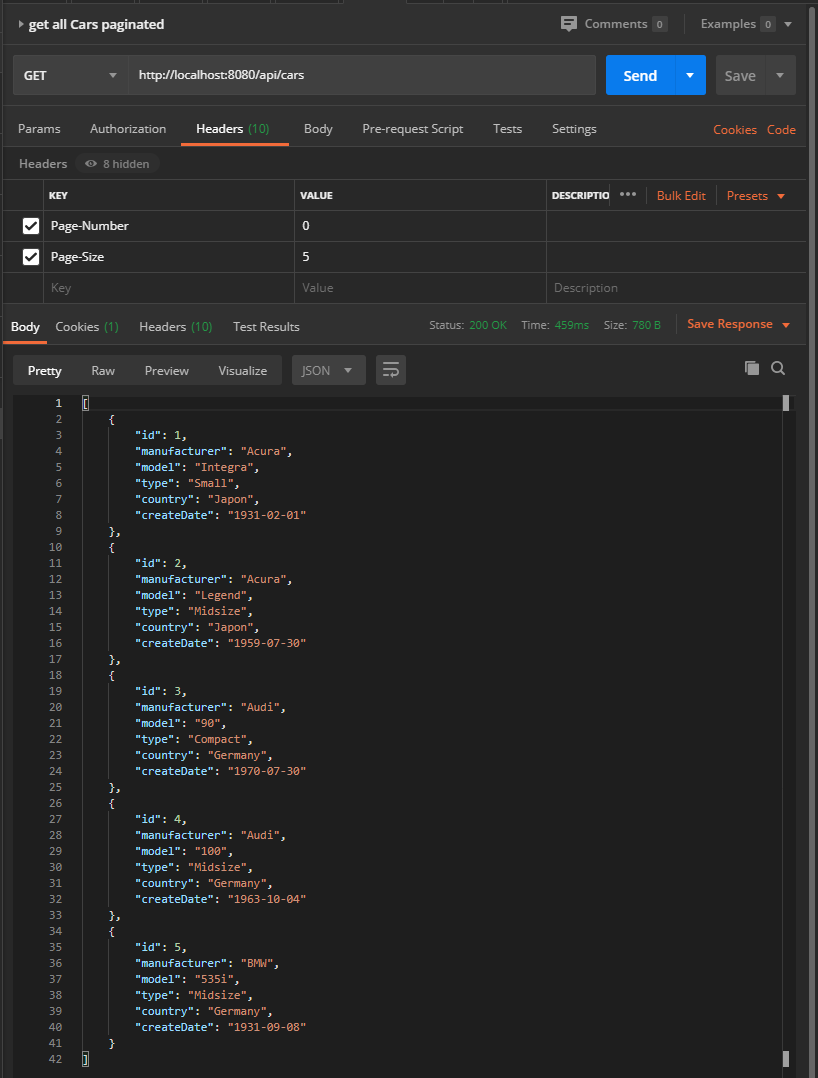
Obtenir la liste paginée des voitures
Nous fixons dans l’entête de la requête deux paramètres : le page-number à 0 et page-size à 5. Nous récupérons donc la page 0 contenant 5 éléments :
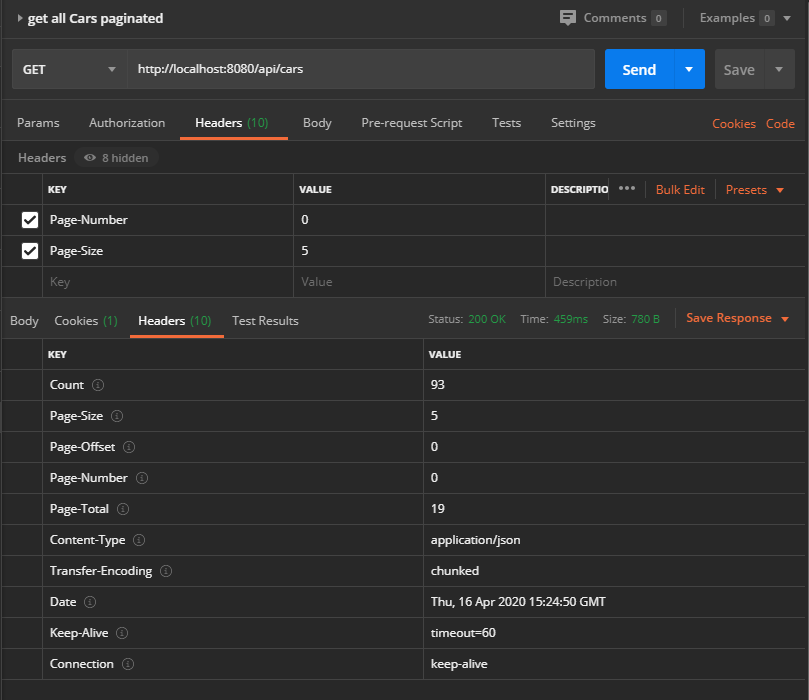
Dans l’en-tête de la réponse, nous avons le nombre total de pages qui est de 19 (où chaque page a 5 éléments) :
Obtenir la liste triée des voitures
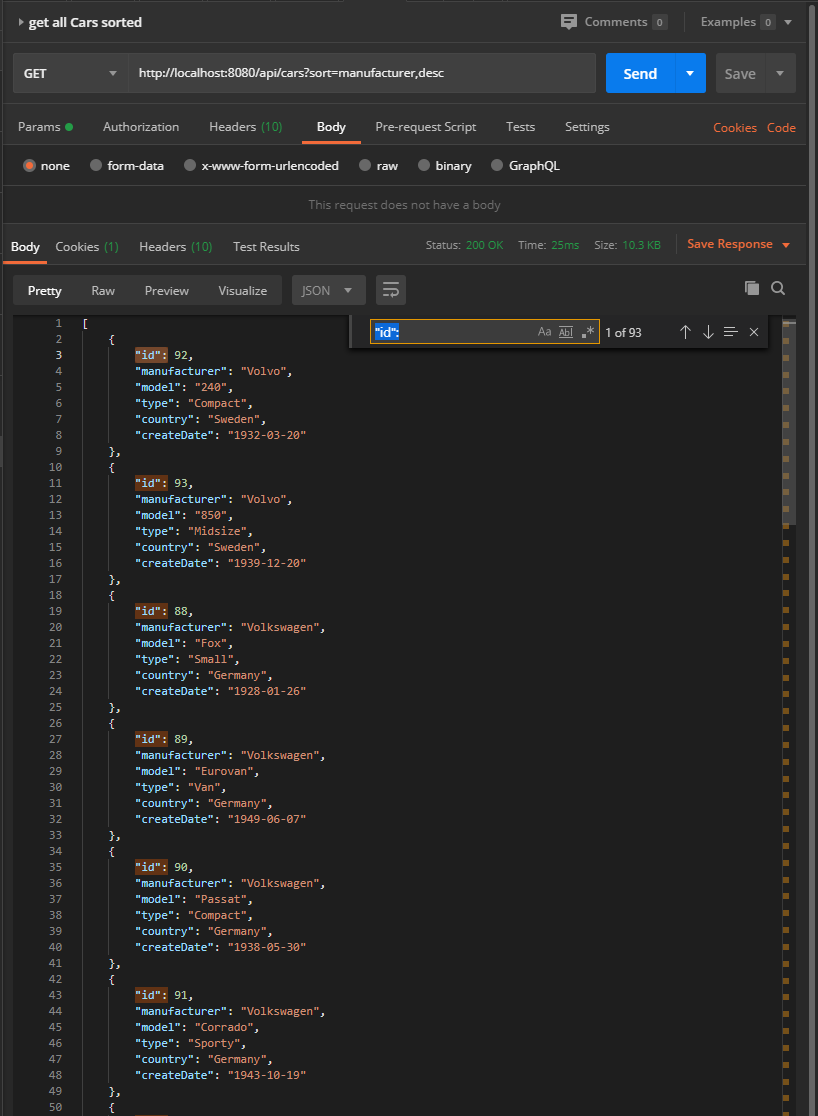
Ici nous récupérons toutes les voitures triées par fabricant dans un ordre décroissant.
Obtenir une liste filtrée des voitures
Et si nous cherchons les voitures américaines :

Obtenir la liste filtrée et paginée des voitures
Si nous recherchons les voitures allemandes par page de 5 éléments:
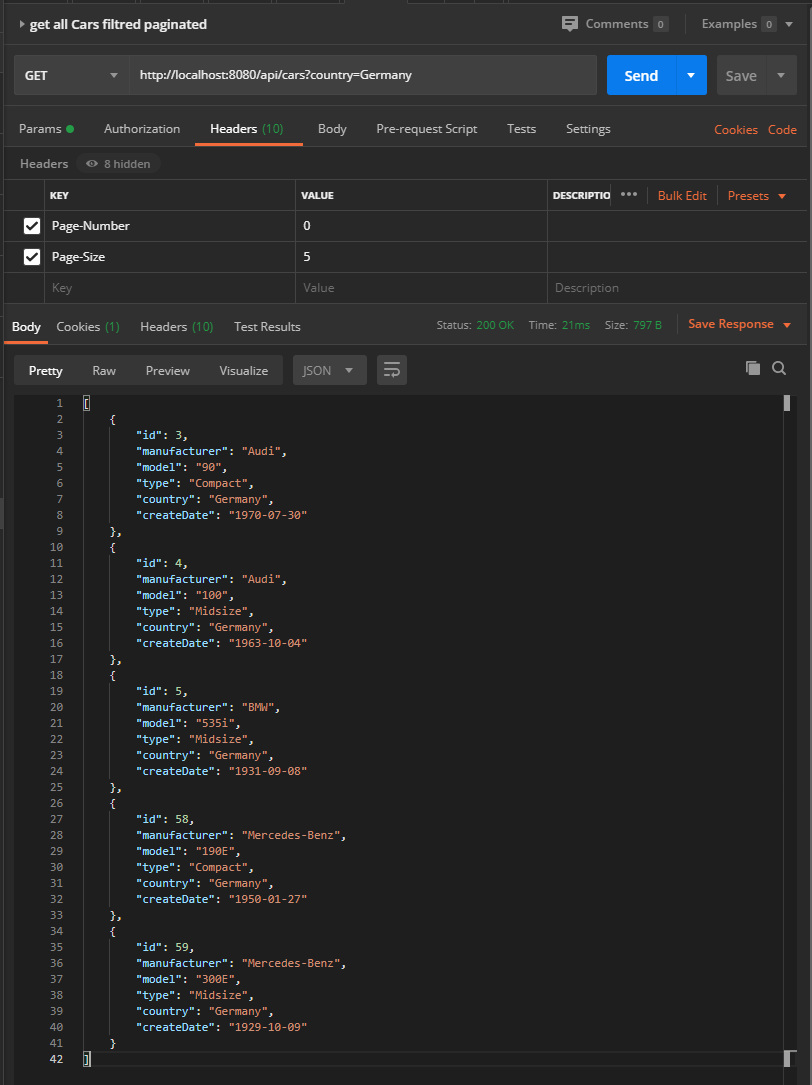
Globalement, il y a 9 voitures allemandes en 2 pages.
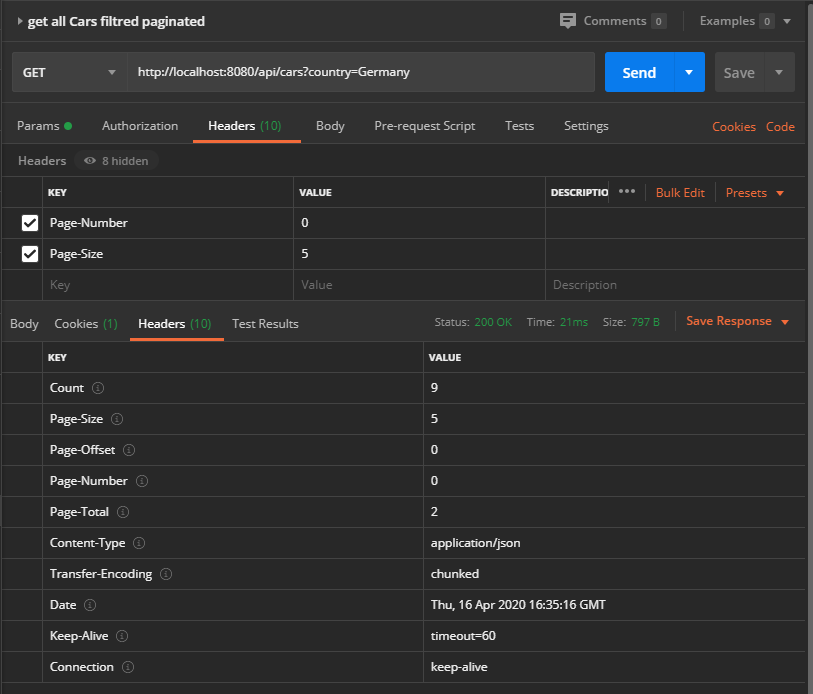
Obtenir une liste filtrée et triée des voitures
Avant de terminer, supposons que nous souhaitons rechercher des voitures japonaises créées entre le 30/07/1959 et le 1/11/1966 et afficher le résultat dans l’ordre croissant.
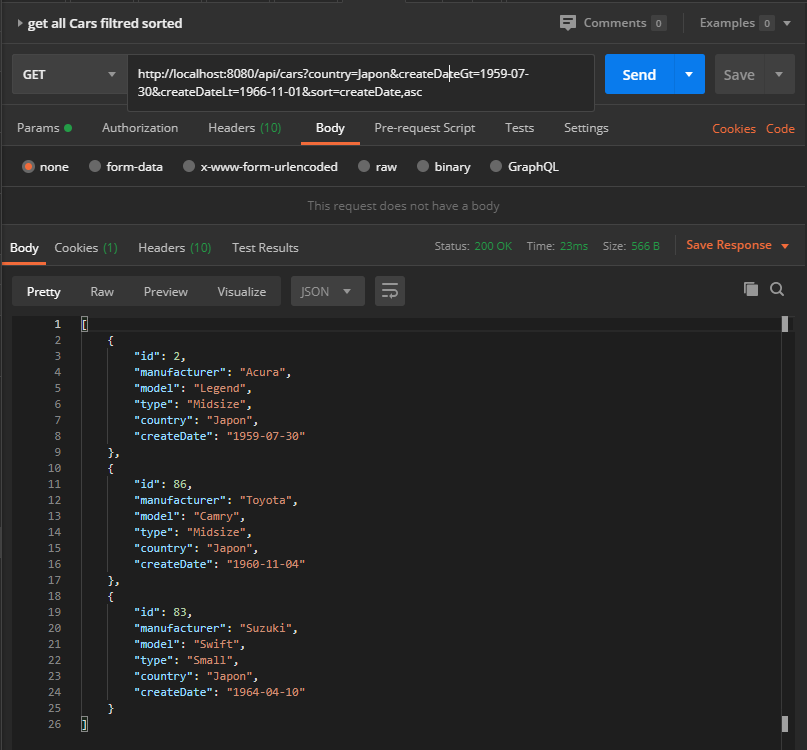
Obtenir une liste filtrée, triée et paginée des voitures
Finalement, recherchons des voitures américaines de type petit triées par date de création dans l’ordre décroissant.
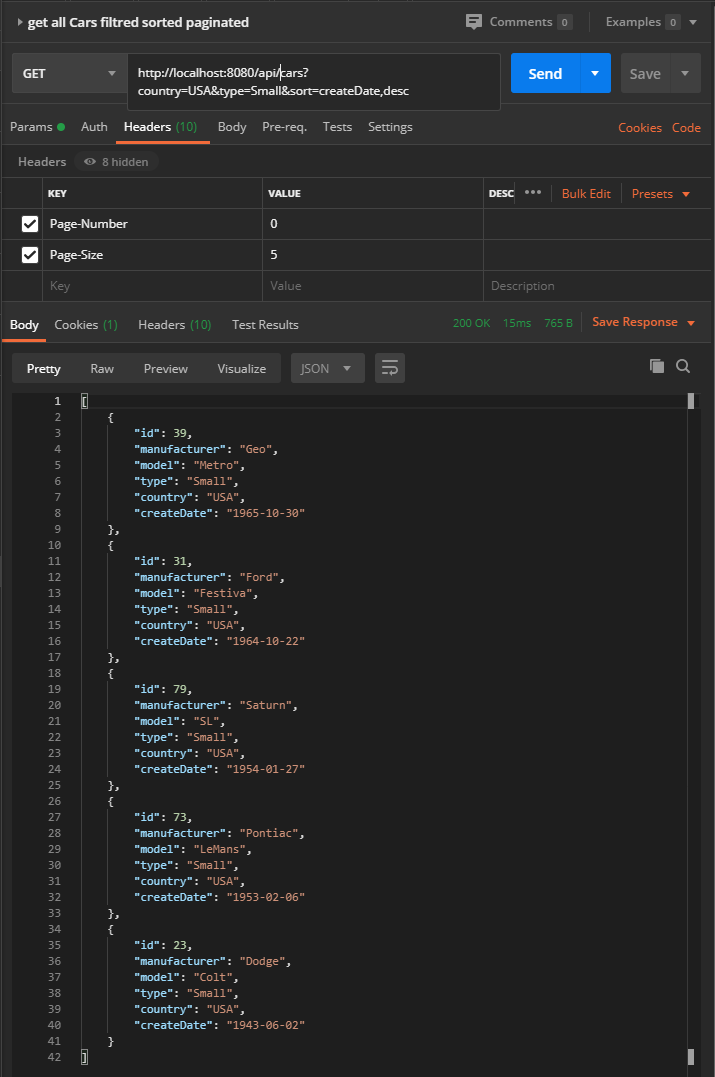
Nous trouvons 8 voitures dans 2 pages de taille 5.

Conclusion
Dans cet article nous avons vu comment créer une API REST de recherche optimisée, sans efforts : nous évitons d’une part l’explosion de méthode dans le repository, et d’autre part nous n’avons pas de code fastidieux avec la logique if-else monstrueuse à maintenir.
Nous répondons à une panoplie de cas d’usage : pagination, tri, et filtrage sur les différents attributs; en seul endpoint.
