Qu’il s’agisse de systèmes gérant les stocks d’une enseigne de distribution ou la mise à jour en temps réel de données clients dans le milieu bancaire, nos choix se tournent de plus en plus vers des architectures asynchrones et basées sur l’échange de messages. Ces architectures reposent souvent sur des Message-Oriented Middleware, ou “MoM” pour les intimes. Citons à titre d’exemple Apache Kafka, RabbitMQ, ou encore dans une moindre mesure Mosquitto (ce dernier reposant sur le protocole MQTT et étant plutôt un broker orienté IOT). Tous ont des avantages, et tous sont aujourd’hui très utilisés. Cependant je vous propose, au travers de cet article, d’en découvrir un autre, un peu moins connu mais qui a su se faire une place sur le landscape de la CNCF !
Découvrez NATS, le petit MoM qui a tout ou presque pour devenir grand !
Informations générales
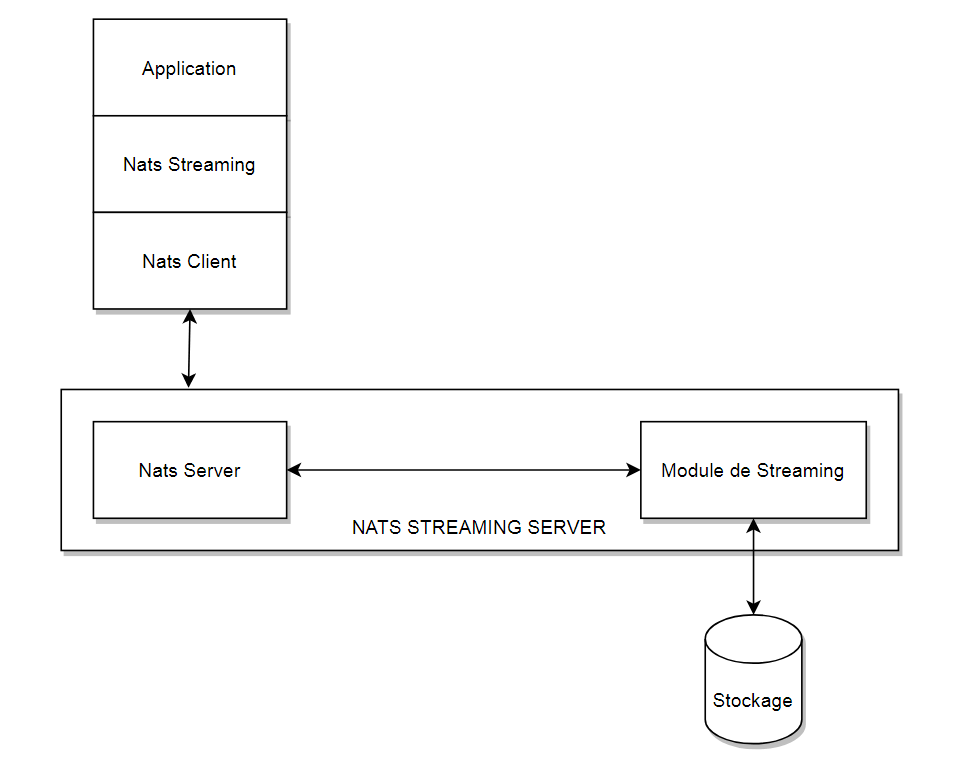
NATS est une solution open source développée et maintenue par Synadia, sortie en première version en 2011, et créée à l’origine par Derek Collison (le fondateur de Synadia) pour assurer l’échange de messages au sein de la plateforme Cloud Foundry. Développé en Golang et faisant partie des projets les plus cotés de la CNCF, le projet NATS est en réalité constitué de trois parties :
- NATS Server : le cœur de NATS, utilisé lors des publish / subscriptions.
- NATS Streaming : une surcouche de persistance et de re-jeu d’envoi de messages, ajoutée à NATS.
- Librairies client : plusieurs librairies disponibles pour utiliser NATS (Go, JS, Java, C#, mais aussi Rust et Python).
L’une de ces librairies a notamment été employée pour développer l’un des outils que nous utiliserons dans la partie “…à la pratique” . Mais avant de jouer avec NATS et de coder nos premiers échanges de messages, quelques explications s’imposent : la récréation vient toujours après la leçon !
De la théorie…
Leçon numéro 1 : les concepts de bases
De base, NATS est très différent d’Apache Kafka dans sa façon de traiter les messages. En effet ceux-ci ne sont pas “persistés” comme sur Kafka. En outre, si un subscriber tombe, et est remonté quelques temps après, les messages publiés sur le subject écouté seront perdus. NATS est donc plus proche de MQTT (notamment dans la façon dont sont hiérarchisés les subjects) et n’est donc pas destiné à conserver les messages sur le long terme (cependant les performances offertes en font un bon candidat dans le domaine de l’IOT).
A l’instar des autres solutions de MoM, NATS traite des messages publiés sur des canaux de communication appelés subjects (équivalent des topics Kafka). Ces messages, envoyés par des publishers, sont consommés par des subscribers abonnés à tel ou tel subject. Chaque subject est représenté par une chaine de caractères, contenant des tokens séparés par des “.” . Cette approche, qui sera familière pour les utilisateurs de Mosquitto, permet de hiérarchiser facilement les subjects.
Des wildcards peuvent être utilisés lors de l’abonnement d’un subscriber. De cette façon, le subscriber peut écouter plusieurs subjects simultanément.
Deux types de wilcard peuvent ainsi être utilisés :
- * qui peut être utilisé pour remplacer un (et un seul) token / niveau de la hiérarchie.
- > qui peut être utilisé pour remplacer plusieurs tokens / niveaux de la hierarchie.
Pour que ces explications soient plus claires, voyons quelques exemples.
- un subscriber s’abonnant à eu.*.nord recevra les messages issus du subject eu.fr.nord ainsi que ceux publiés sur eu.it.nord. En revanche il ne recevra pas les messages de eu.fr.nord.lille
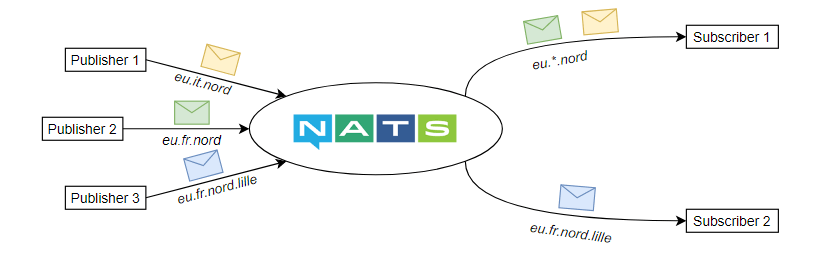
- un subscriber abonné à eu.fr.> recevra les messages de eu.fr.nord, eu.fr.nord.lille et eu.fr.nord.douai.

Les wilcards peuvent également être associés : un subscriber s’abonnant à *.*.centre.> recevra les messages publiés sur eu.fr.centre.paris.8em, eu.fr.centre.paris, eu.fr.centre.paris.3em, us.maine.centre.brownville, …
Mais au delà des wildcards, NATS fournit divers modèles de communication pour assurer l’acheminement des messages.
Leçon numéro 2 : les modèles de communication
Pub/Sub
Il s’agit du mode de communication le plus simple : un publisher envoie un message sur un subject et un ou plusieurs subscribers le consomme. Ici chaque subscriber va recevoir le message s’ils sont abonnés au même subject.
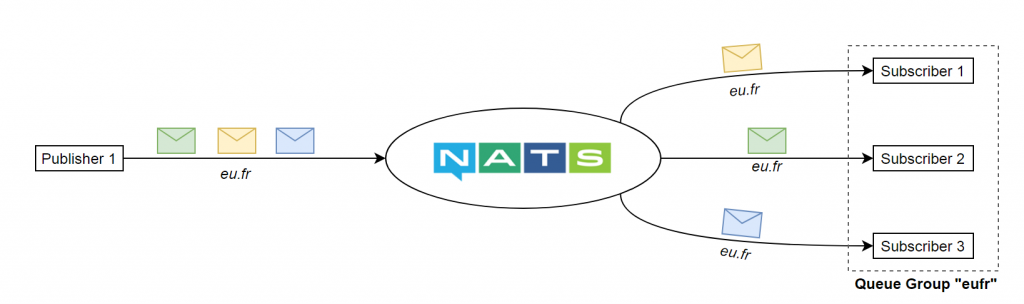
Queue groups
On retrouve ici un concept assez similaire au “consumer groups” de Kafka. En outre, si plusieurs subscribers sont abonnés au même subject, et que ceux-ci font partie du même groupe, alors chaque message publié sur ce subject sera traité par un et un seul subscriber du groupe. Cette approche est intéressante dans le cas où nous souhaiterions, par exemple, “scaler” un subscriber pour faire face à des pics de charge (load balancing) : en liant chaque instance de ce subscriber à un même groupe on garantit qu’un même message ne sera pas traité en doublon.
Request / Reply
Il s’agit d’un mode reposant sur le même modèle que Pub / Sub, si ce n’est qu’ici les requêtes envoyées par un publisher font l’objet de réponses de la part du subscriber (si vous connaissez RabbitMQ vous reconnaitrez le principe de Remote Procedure Call). Pour cela, avant l’envoi du message, le publisher s’abonne à un subject spécifique, appelé “Inbox”, sur lequel les réponses sont publiées. Une fois cette réponse reçue, le publisher se désabonne du subject en question.
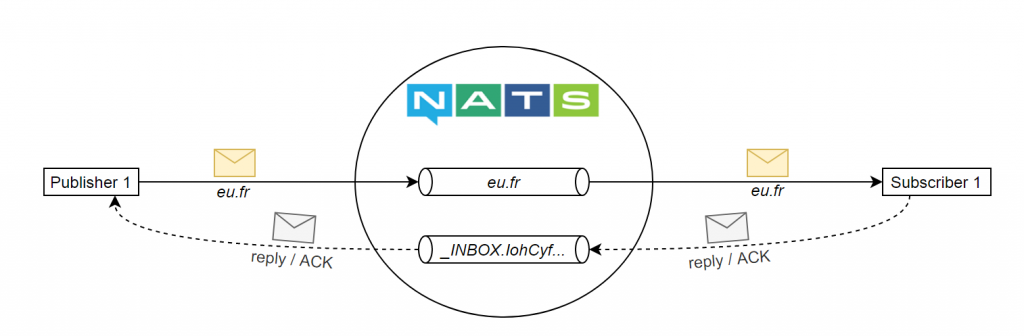
Dans certains cas des messages peuvent se perdre, Nats reposant sur un système “at-most-once“.
L’approche Request / Reply est donc intéressante pour mettre en place un pattern de retry si un message n’a pas été délivré (en somme si le publisher n’a pas reçu de ACK au bout d’un certain temps, le message sera de nouveau publié). Ces contrôles et le retry devront donc être implémentés côté publisher.
Leçon numéro 3 : NATS Streaming
Bien que le coeur de NATS ne propose pas de persistance des messages, cela ne signifie pas qu’il est impossible de la mettre en place. NATS Streaming, qui peut être vu comme une surcouche de NATS, permet en effet de configurer cette persistance. Dès lors il devient possible de conserver les messages en mémoire, au sein de fichiers plats voire en base de données. Une API permet d’ailleurs aux contributeurs du projet de créer leurs propres implémentations (pour proposer un connecteur pour tel ou tel SGBD par exemple). Mais NATS Streaming ne se limite pas à cela, et fournit d’autres fonctionnalités très intéressantes. Citons notamment :
- At-least-once-delivery, ou “livraison au moins une fois”, via un mécanisme d’accusé de réception publisher / serveur, et serveur / subscriber. Le serveur conserve les messages sur le système de stockage configuré (mémoire, fichier plat, …) et redistribue aux clients abonnés si nécessaire.
- Possibilité de relire les messages historisés par subject. Cette fonction, qui fait d’ailleurs la force de Kafka, est disponible via NATS Streaming. Ainsi les nouveaux subscribers s’abonnant à tel ou tel subject pourront préciser une position de départ dans le flux pour la relecture des messages. Ce point de départ peut être le premier message enregistré pour un subject donné, le dernier message publié, mais aussi un identifiant unique de message ou encore une date / heure spécifique.
- Limitation du flux issu du publisher, via une option appelé “MaxPubAcksInFlight” précisée lors de la connexion. Celle-ci permet de limiter le nombre de messages non acquittés que peut envoyer un publisher. Une fois le seuil atteint, les autres publications seront bloquées jusqu’à ce que le nombre de messages non acquittés tombe sous la limite paramétrée.
- De la même manière, une option “MaxInFlight” permet de limiter le nombre de messages délivrés à un subscriber donné. En outre, cette option désigne le nombre maximum de messages délivrés mais non acquittés (soit le nombre d’ACK en suspens).
- La conservation d’une correspondance entre un nom (désignant un abonnement spécifique) et un numéro de séquence reconnu pour un client. Ce mécanisme, appelé souscription persistante, permet au serveur, de reprendre la remise des messages en cas de redémarrage d’un client si ce dernier réutilise le même ID. En d’autres termes le serveur va ré-émettre tous les messages en commençant par délivrer le premier non acquitté.
Précisions que toutes ces fonctionnalités, qui faisaient défaut à NATS, permettront d’assurer la résilience de vos applications et leur capacité à reprendre une activité normale après une panne par exemple.
Un bémol cependant : les subjects utilisés sur NATS Streaming (appelé channels) ne permettent pas l’usage de wildcard lors des souscriptions.
Sachez enfin que NATS Streaming implémente son propre format de message à l’aide des Protocols Buffers, et bien entendu un serveur spécifique est nécessaire pour utiliser NATS Streaming.
… à la pratique
Trêve de blabla, passons aux travaux pratiques. Nous avons vu dans la partie précédente que NATS Streaming offrait plusieurs fonctionnalités intéressantes pour assurer la résilience de nos systèmes. Nous allons à présent illustrer certains de ces concepts en créant notre propre cluster NATS Streaming : les messages seront publiés sur ce cluster et persistés dans une base PostgreSQL. Ce premier exercice vous permettra également de découvrir quelques modes de fonctionnement de NATS Streaming (notamment le cluster mode et le partitionnement) mais également de poser les bases d’un prochain article qui démontrera comment mettre en œuvre NATS au sein d’une application écrite en GoLang.
Cluster… vous avez dit Cluster ?
Le mode cluster
Ce mode de fonctionnement (qui repose sur l’algorithme de consensus Raft) offre une certaine protection en cas de défaillance d’un des nœuds du cluster, en assurant une réplication des données. En d’autres termes, un nœud master, prédéfini ou élu par l’ensemble des nœuds composant le cluster, assure la réception/envoi de messages. Ces messages sont persistés au sein de son propre store (fichier ou base de données), mais également enregistrés par les autres nœuds. Le nœud principal assurant seul la distribution des messages, le dimensionnement horizontal est donc limité.
Le partitionnement
Autre mode de fonctionnement, qu’on ne peut malheureusement pas associer au mode cluster, le partitionnement permet de limiter le nombre de channels qu’un serveur aura à gérer (voyons une partition comme un groupe de channels). Cela a donc deux avantages :
- La charge peut être répartie entre plusieurs serveurs NATS exécutés avec le même “cluster ID”.
- On évite la création automatique de channels indésirables.
Point intéressant : comme nous le soulignons un peu plus haut, contrairement aux subjects, les channels de NATS Streaming ne supportent pas l’utilisation de wildcards lors de la souscription. Mais il est tout à fait possible d’utiliser les wildcards pour définir la partition qu’un serveur peut gérer.
Nous vous disions également qu’il n’était pas possible de coupler le partitionnement avec le cluster mode. Alors comment nous assurer de la haute disponibilité de notre système ? Réponse avec un troisième mode de fonctionnement, qui lui peut être associé au partitionnement !
Fault Tolerance
Avec un partitionnement basique, si le serveur assurant l’envoi et la réception des messages vient à tomber, les messages seront perdus. Un troisième mode appelé Fault tolerance permet de prévenir ce type d’effet indésirable. Ce mode de fonctionnement consiste à créer plusieurs serveurs qui évolueront au sein d’un même groupe et partageant le même store de messages. Un seul serveur sera chargé d’acheminer les messages. Si celui-ci vient à défaillir, alors un autre serveur du même groupe prendra le relais.
En outre, il est tout à fait possible de combiner le Fault Tolerance avec un partitionnement de façon à avoir un serveur de backup sur chaque nœud du cluster. C’est ce que montre le schéma suivant :
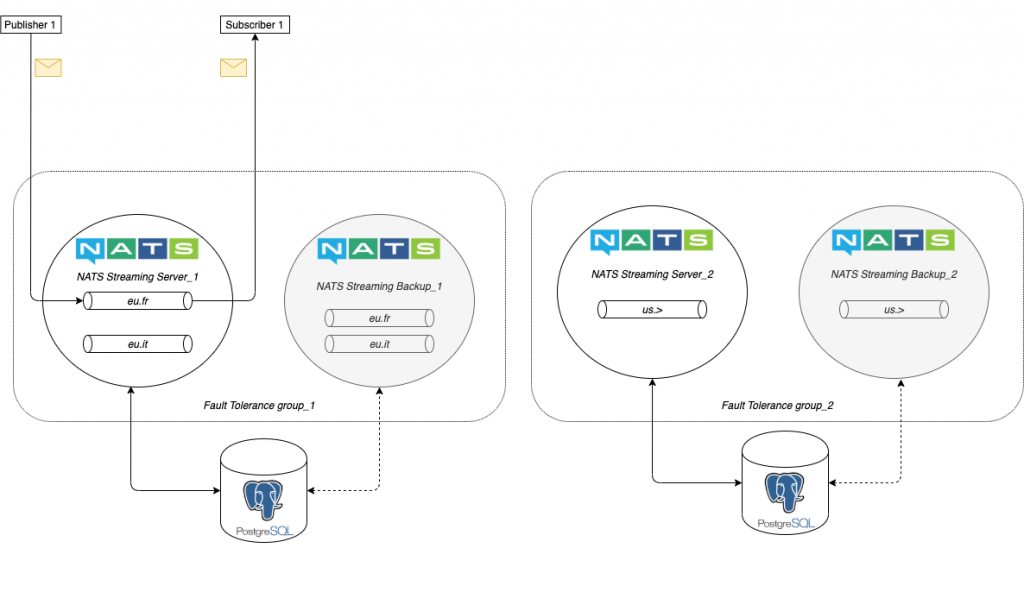
Nous avons ici un cluster composé de deux noeuds, chacun ayant une partition composée de:
- deux channels pour le noeud NATS Streaming Server_1
- un channel dans le cas de NATS Streaming Server_2
Si l’un des nœuds du cluster tombe, le backup prend le relais en redistribuant les messages au subscriber 1. Ces messages étant conservés sur un store commun, une base PostgreSQL dans notre cas d’utilisation, il n’y aura aucune perte d’information.
Démarrage avec docker-compose
Voyons à présent comment mettre en oeuvre un cluster NATS Streaming, avec des channels répartis entre deux serveurs et tolérant à la panne… le tout avec docker-compose !
version: '3.5'
services:
postgres:
container_name: postgres
image: postgres
environment:
POSTGRES_USER: postgres
POSTGRES_PASSWORD: postgres
volumes:
- ./initdb.sql:/docker-entrypoint-initdb.d/postgres.sql
- ./postgres:/var/lib/postgresql/data
ports:
- "5432:5432"
networks:
- nats
nats-streaming-twitter-server:
container_name: nats-streaming-twitter-server
image: nats-streaming
volumes:
- ./twitter.conf:/twitter.conf
ports:
- "4222:4222"
- "8222:8222"
command: --ft_group twitter -sc twitter.conf --cluster nats://0.0.0.0:6222 --store SQL --sql_driver postgres --routes nats://nats-streaming-twitter-backup:6222 --sql_source postgres://postgres:postgres@postgres?sslmode=disable
restart: always
depends_on:
- postgres
networks:
- nats
nats-streaming-twitter-backup:
container_name: nats-streaming-twitter-backup
image: nats-streaming
volumes:
- ./twitter.conf:/twitter.conf
ports:
- "4223:4222"
- "8223:8222"
command: --ft_group twitter -sc twitter.conf --cluster nats://0.0.0.0:6222 --store SQL --sql_driver postgres --routes nats://nats-streaming-twitter-server:6222 --sql_source postgres://postgres:postgres@postgres?sslmode=disable
restart: always
depends_on:
- postgres
- nats-streaming-twitter-server
networks:
- nats
...
networks:
nats:
driver: bridge
ipam:
config:
- subnet: 172.30.255.0/24
driver: default
Dans le fichier docker-compose précédent, nous commençons par créer un conteneur qui exposera la base de données. Nous l’utiliserons comme store (un fichier SQL est utilisé pour initialiser la base), puis nous utiliserons un serveur NATS Streaming, suivi d’un second qui fera office de backup. Au démarrage du conteneur, une commande est utilisée pour initialiser l’instance de NATS Streaming. Ci-dessous les principales options utilisées :
- L’option –ft_group est utilisée pour préciser le nom du groupe dans lequel le serveur courant va évoluer, en cas de défaillance, un autre serveur du même groupe prendra le relais (les routes assurant la liaison avec les autres instances de NATS Streaming étant déclarées via –routes).
- –store, –store_driver et –sql_source sont utilisées pour spécifier le type de store, le driver, ainsi que l’URL de la base PostgreSQL à utiliser.
- -sc permet de spécifier le fichier de configuration à utiliser pour créer un partitionnement constitué de deux channels, ce dernier ayant le contenu suivant :
partitioning: true
store_limits: {
channels: {
ineat: {},
ilab: {}
}
}
Pour démarrer notre stack, un simple docker-compose up suffit.
Vous devriez normalement obtenir le résultat suivant dans votre console :

Test du cluster et dernières vérifications
Pour simplifier les tests, inutile de vous lancer dans la production de code Java ou Golang, les outils “tout fait” pullulent sur Internet ! Commencez par installer nats-streaming-cli, un outil en ligne de commande qui permettra de tester l’envoi et la réception de messages via notre cluster.
npm install -g nats-streaming-cli
Démarrons un subscriber qui écoutera le channel ilab :
subscribe-to-nats-streaming-channel ilab
… puis envoyons un message via la commande suivante :
echo 'a new message' | publish-to-nats-streaming-channel ilab
Le subscriber reçoit bien le message. Avec votre client SQL préféré, connectez-vous au store, et lister le contenu de la table messages, les hash des messages précédemment envoyés devraient y figurer.
Démarrez à présent un second subscriber écoutant un channel arbitraire (“test” par exemple) et testez un envoi de messages sur ce même channel. Le subscriber ne devrait rien recevoir. En effet, le channel “test” ne figure pas dans la liste des channels du partitionnement que nous avons créé !
En attendant la prochaine leçon…
Dans cet article nous avons soulevé le capot pour voir comment NATS fonctionnait. La mise en pratique aura permis d’avoir un aperçu concret des concepts abordés en première partie. Dans le prochain article nous verrons un cas d’utilisation complet : la création d’un agrégateur de news, conservant un top 10 des news les mieux notées. Le tout développé en Golang, l’occasion de voir comment fonctionnent les librairies client officielles. En attendant la suite, quelques ressources documentaires pour patienter, de quoi réviser pendant les vacances !
- Site officiel de NATS – https://nats.io/
- La documentation officielle – https://docs.nats.io/
- Fonctionnement du Raft Concensus – https://raft.github.io/

