
Si vous utilisez jMeter et que vous souhaitez vous en servir pour vos tests de charge Kafka, cet article est fait pour vous !
Il existe de nombreuses façons d’envoyer de gros volumes de messages dans un topic kafka à des fins de tests de montée en charge des applications qui exploitent la technologie :
- en exploitant le script kafka-producer-perf-test.sh
- en utilisant des clients comme Conduktor qui permettent d’envoyer des messages en masses
- en s’appuyant sur des outils de tests de performance
- etc
N’importe laquelle de ces alternatives fera l’affaire si vous cherchez à envoyer uniquement des contenus de messages aléatoires en masse.
Par contre, si le contenu de vos messages est soumis à des contraintes fonctionnelles (voir techniques), le choix de l’outil deviendra bien plus restreint.
Mon use-case de test
L’application que je souhaite stresser est une application Java / Spring Boot / Kafka, qui, à la réception d’un message, déclenche un traitement assez complexe et des appels à diverses APIs.
Je n’ai donc besoin que de produire de la donnée.
Si la donnée du message en entrée n’est pas cohérence (certaines règles de mes traitements valident par exemple que la valeur du champ A est connue du système), le traitement sera avorté avant d’avoir pu stresser l’intégralité de la chaine d’appels ;
Le but ce test de performances est de valider :
- que le système tient la charge s’il est bombardé de messages en quelques secondes
- que les mécanismes de scaling fonctionnent comme attendus
- que les applications sollicitées ont le bon sizing (utilisations CPU et mémoire par exemple)
- etc
Laissez-moi vous exposer mes contraintes projets, qui ont écarté la majorité des alternatives :
- Mes messages Kafka contiennent des headers, des clés et des payloads
- Le format des données est basé sur Avro, et une schema registry (propriétaire)
- Cette donnée est fonctionnelle : elle doit être connue et pertinente pour que le traitement de mes consommateurs (que je souhaite éprouver) aille au bout
- Les plateformes blazemeter et/ou Octoperf (basées sur jMeter) doivent assumer la charge des tirs de perfs
La seule possibilité viable, compte tenu de ces contraintes, est l’utilisation de jMeter avec un plugin permettant d’effectuer du publish/subscribe Kafka: kLoadGen
Les autres plugins OSS ne supportaient pas une des fonctionnalités de Kafka requises pour mes tests (gestion des headers, ou de AVRO, ou d’une schema registry par exemple)
KLoadGen à la rescousse
Ce dépôt Github vous met à disposition la solution de ce tutoriel.
La documentation de KLoadGen, présente sur son dépôt Github, est perfectible, mais permet néanmoins de commencer rapidement à envoyer des messages Kafka via jMeter.
L’installation de KLoadGen s’effectue
- en téléchargeant la version du jar voulue sur la registry Maven
- en copiant le jar téléchargé dans le répertoire
lib/extde jMeter
Si votre installation est correcte, vous devriez avoir accès à de nouveaux éléments de configuration dans jMeter :
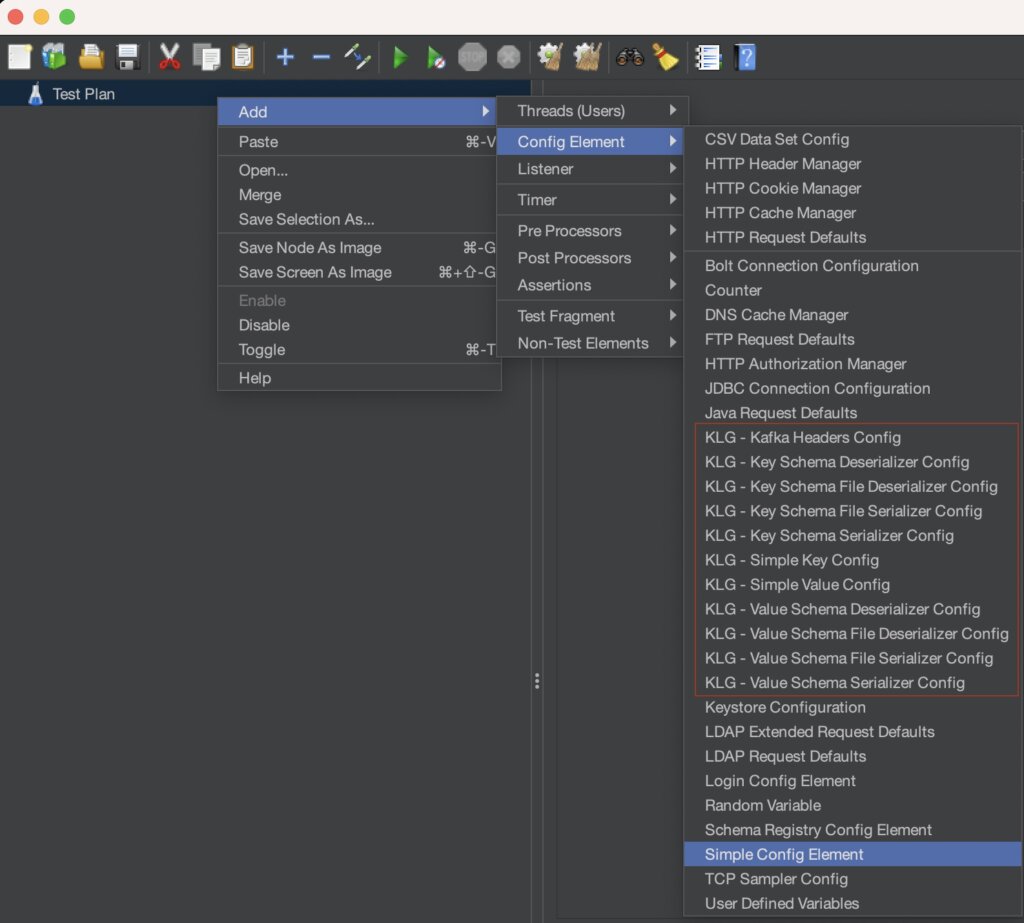
Implémentation d’un scénario basé sur un use-case simple
Je vous propose dans ce chapitre de configurer un scenario KLoadGen simple, basé sur la Streetlights Kafka API; et plus précisément un envoi en masse de messages sur le channel smartylighting.streetlights.1.0.action.{streetlightId}.turn.on. (afin de stresser le comportement de l’équipement si nous lui envoyons en masse des demandes)

Si vous consultez cet article, c’est que vous avez vraisemblablement un broker Kafka à disposition ; le seul prérequis si vous voulez tester cette procédure sera de créer un topic smartylighting.streetlights.1.0.action.test.turn.on.
Si pas, vous pouvez démarrer un kafka localement par exemple.
Schema registry et publication du schéma requis
KLoadGen a besoin d’une schema registry Kafka pour fonctionner, c’est d’ailleurs ce qui le différencie de PepperBox.
Afin de faire fonctionner le tutoriel (et si vous n’avez pas de schema registry), vous pouvez:
- Démarrer apicurio-registry via Docker
- Publier le schema Avro
turnOnOffPayloaddans la registry via
curl --location --request POST 'http://localhost:8080/apis/registry/v2/groups/my-group/artifacts' \
--header 'Content-Type: application/json; artifactType=AVRO' \
--header 'X-Registry-ArtifactId: turnOnOffPayload' \
--data-raw '{
"type": "record",
"name": "turnOnOffPayload",
"namespace": "com.ineat.kloadgen.example",
"fields": [
{
"docs": "Whether to turn on or off the light.",
"name": "command",
"type": {"name": "CommandOpts", "type": "enum", "symbols": ["on", "off"]}
},
{"name": "sentAt",
"type" : {
"type" : "long",
"logicalType" : "timestamp-millis"
},
"docs": "Date and time when the message was sent."}
]
}
'
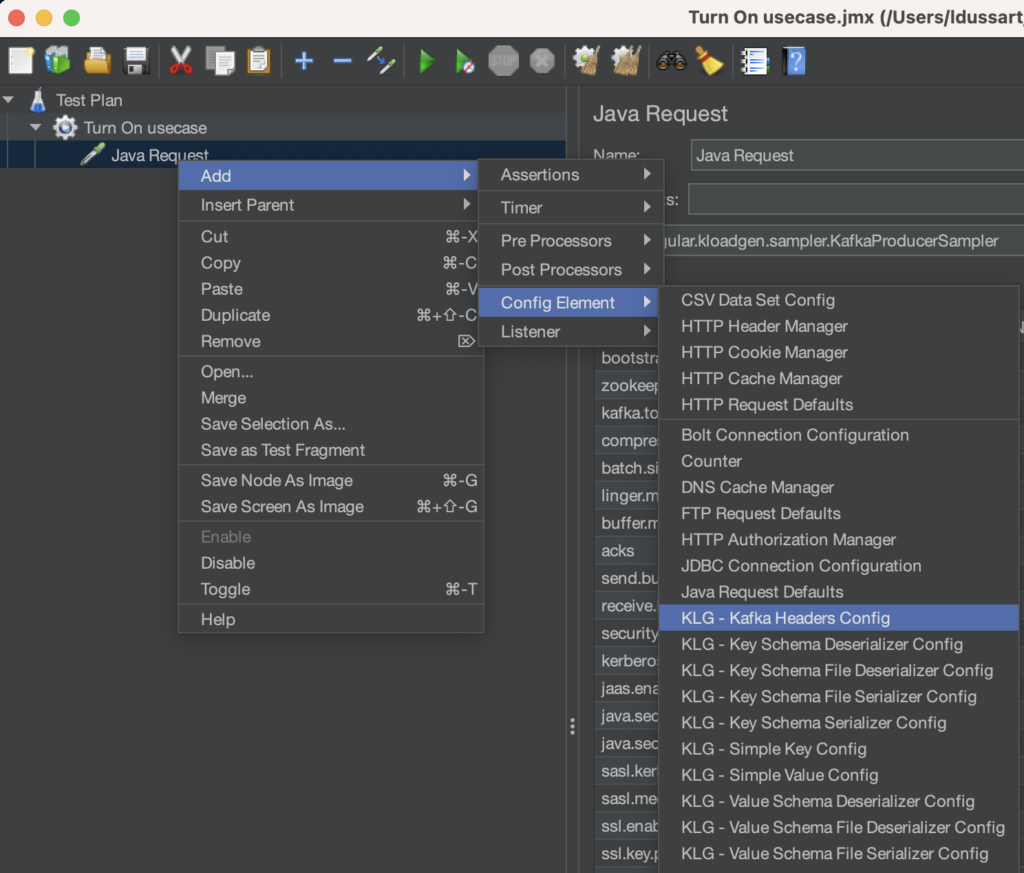
Créer un Thread Group avec un Java Request
La première chose à faire est d’initier votre scénario dans jMeter en ajoutant un Thread Group à votre Test Plan (donnez-lui un joli petit nom)
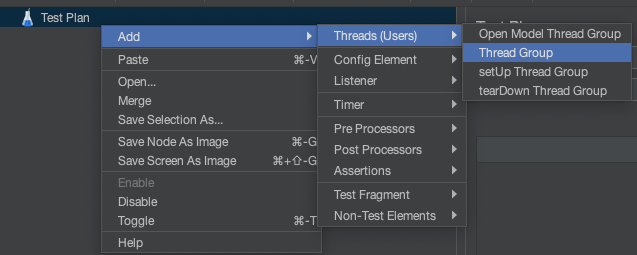
- Puis ajoutez un
Java Requestqui vous met à disposition lesproduceretconsumerde KLoadGen.
- Choisissez
com.sngular.kloadgen.sampler.KafkaProducerSamplerqui correspond au producer kafka

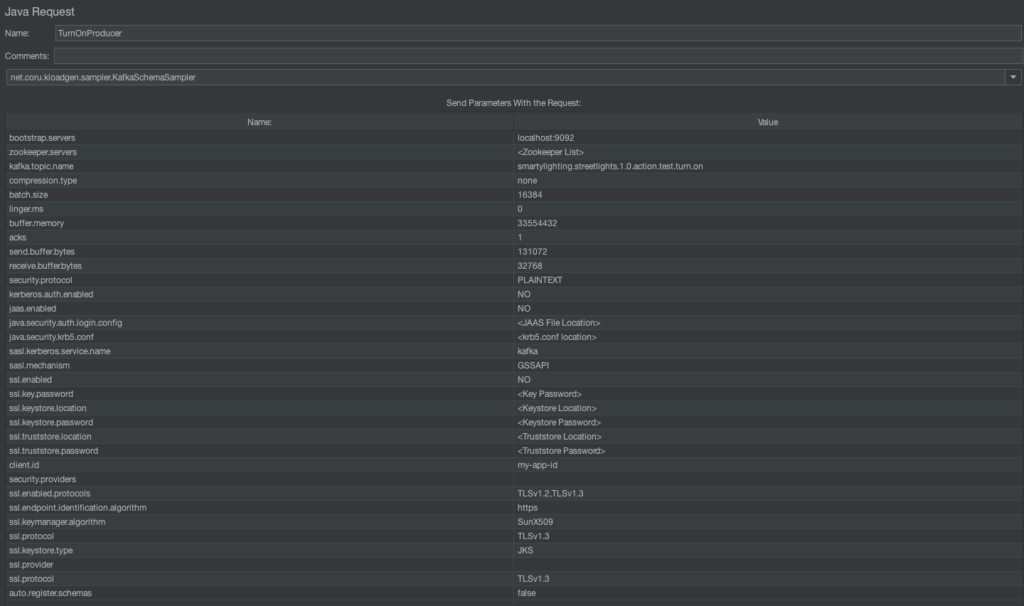
Ce KafkaProducerSampler
bootstrap.servers(localhost:9092 par exemple)kafka.topic.name: le nom du topic où produire les messages, icismartylighting.streetlights.1.0.action.test.turn.onclient.id: si l’on en croit la documentation AsyncAPI, la valeur doit êtremy-app-id
Configurer la schema registry
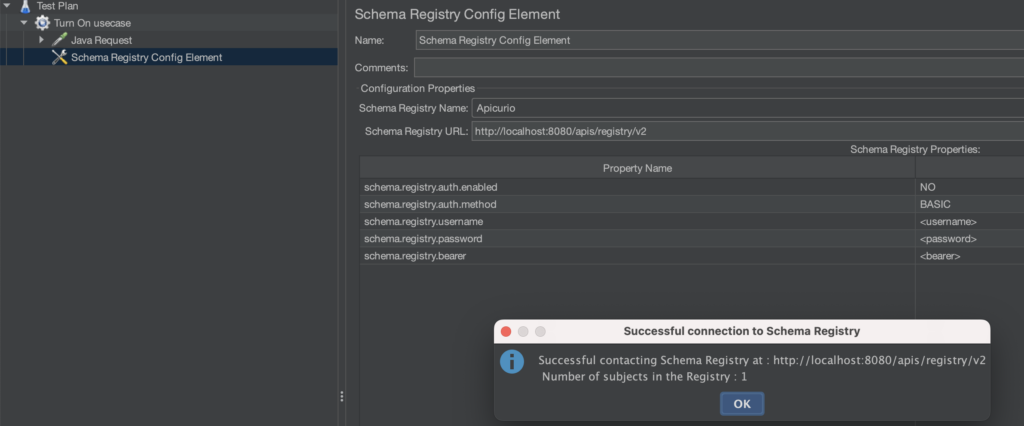
La configuration de la schema registry s’effectue via le Schema Registry Config Element
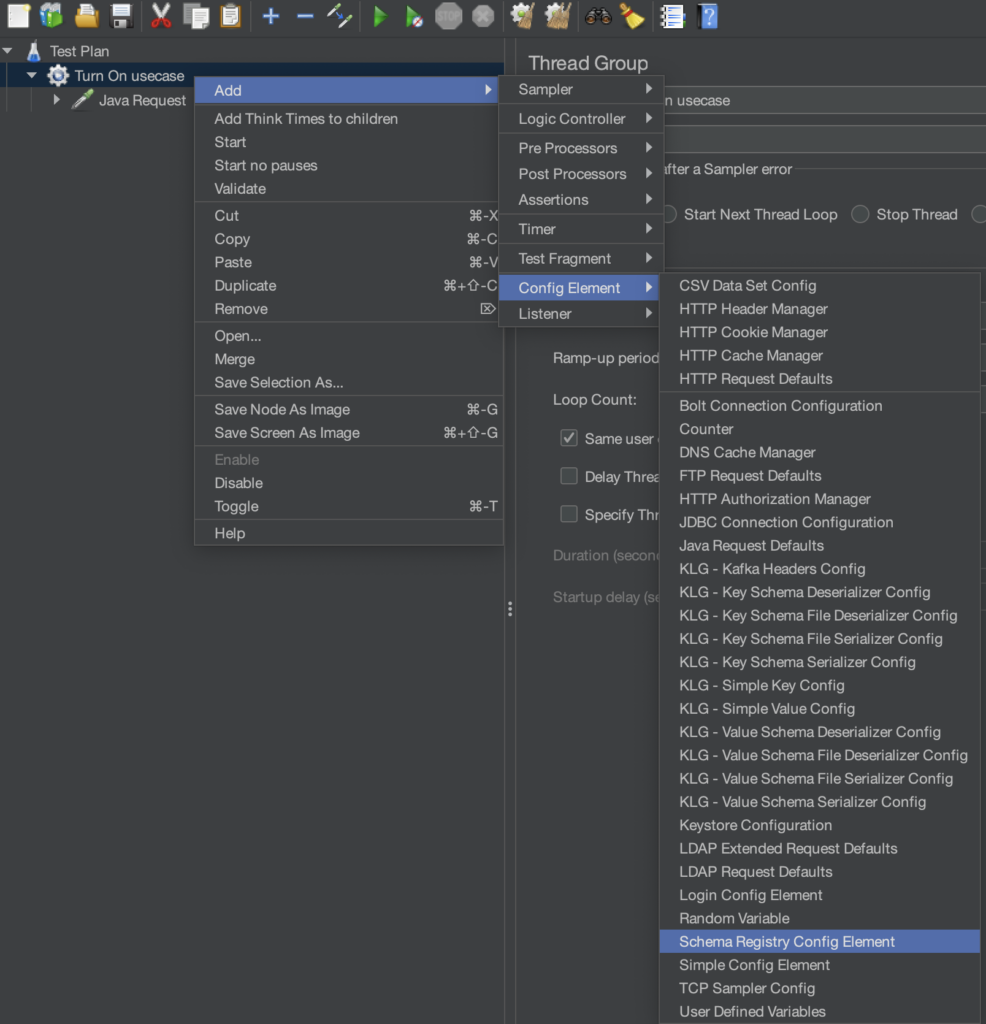
- Choisissez le type de votre registry (Apicurio ou Confluent)
- Saisissez l’url de la registry (http://localhost:8080/apis/registry/v2 en local par exemple)
- Définissez-les identifiants de connexion si besoin
- Cliquez sur Test Registry pour valider le bon fonctionnement (1 schéma devrait être enregistré si vous avez effectué les étapes du chapitre précédent)
Définir le contenu du message
Maintenant que votre producer est configuré, vous allez pouvoir définir le contenu du message à envoyer dans le topic.
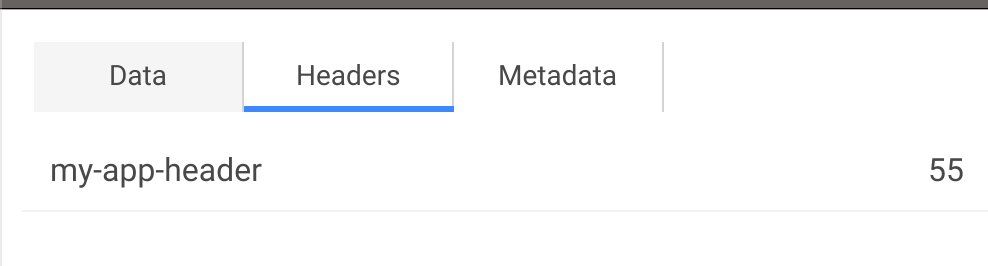
- Pour gérer les headers, utilisez le
KLG - Kafka Headers Config - Ajoutez donc le header
my-app-header, mentionné par la spécification AsyncAPI avec une valeur comprise entre 0 et 100.
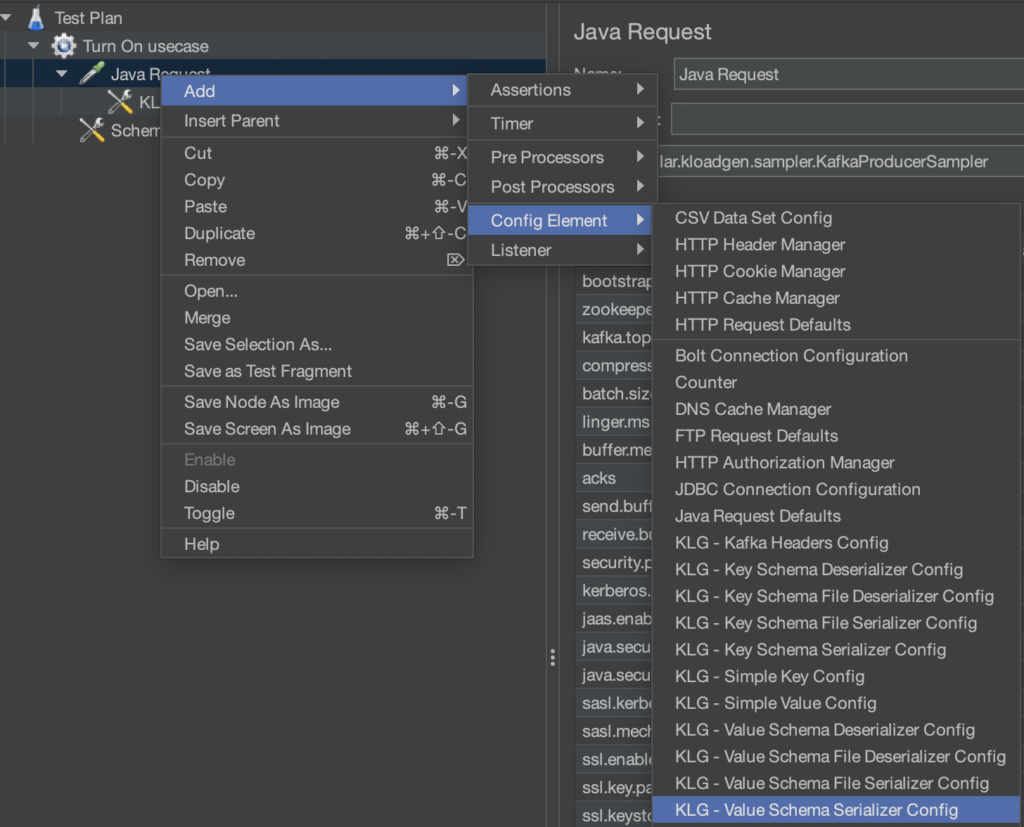
Pour gérer le payload, nous allons nous appuyer sur la schema registry précédemment configurée :
- Ajoutez un
KLG - Value Schema Serializer Configà votreJava Request - Choisissez la stratégie
io.confluent.kafka.serializers.subject.RecordNameStrategypour les besoins du tutoriel - Choisissez le serializer
com.sngular.kloadgen.serializer.GenericAvroRecordSerializer - Puis choisissez votre AVRO depuis le
Value Subject Name(turnOnOffPayload) - Puis cliquez sur
Load Subject
KLoadGen a normalement su récupérer le schéma et a généré le mapping fields/values pour vous (ce qui est très pratique lorsque vous chargez des AVRO beaucoup plus volumineux) :
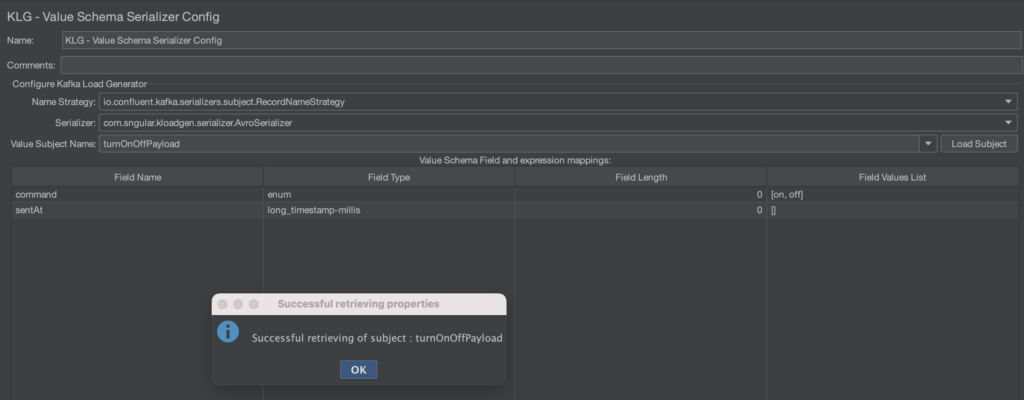
Remarquez par exemple qu’il s’est appuyé sur l’enum de l’AVRO pour vous générer la liste de valeur [on, off].
Pour les valeurs définies avec [], KLoadGen s’appuiera sur le type du champ pour générer une valeur aléatoire
En l’état, et si votre environnement kafka est disponible et que le topic smartylighting.streetlights.1.0.action.test.turn.on existe, vous pouvez générer un premier message !
Générer vos premiers messages
Tentez de cliquer sur le bouton Start (▶︎) et consultez les logs de jMeter afin de contrôler que tout est ok
Vous devriez voir arriver votre premier message publié par jMeter.

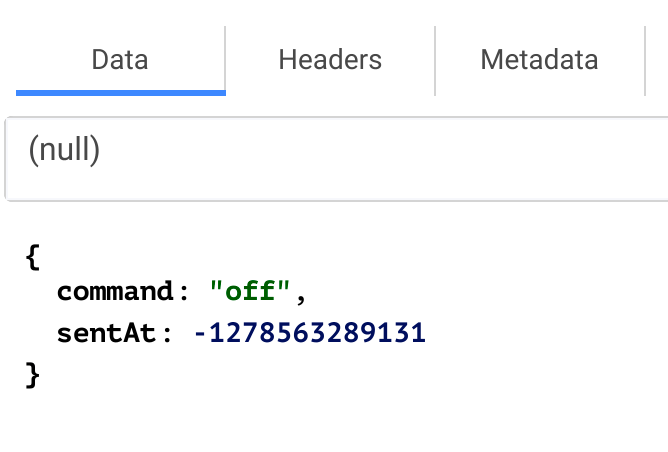
C’est le cas ?
Bien, vous pouvez à présent envoyer une salve de messages dans le topic, ce qui permettra de stresser une API qui écoute l’arrivée de la donnée dans ce topic par exemple.
La configuration du tir s’effectue au niveau de l’item Thread Group de votre scénario :
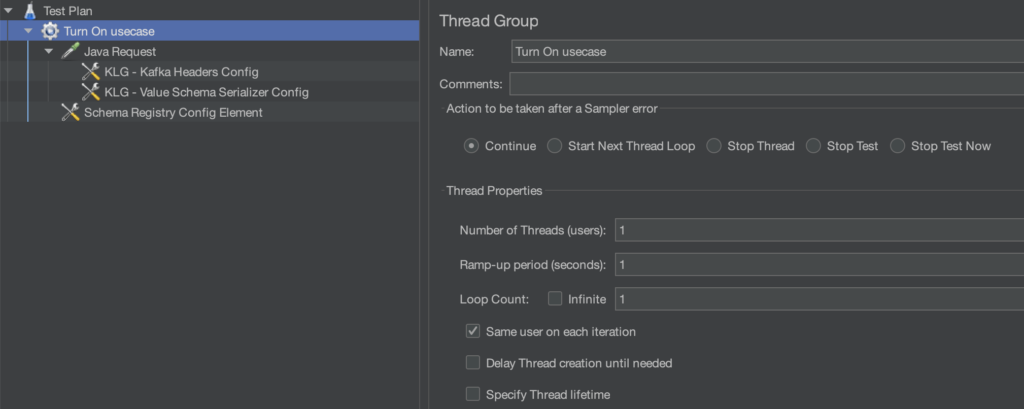
Vous pouvez jouer sur les Thread Properties afin d’exploiter les pleines capacités de votre système pour paralléliser les envois pour générer massivement des messages.
Par exemple, si vous définissez un Loop Count de 100, jMeter enverra 100 messages !
Essayez !
Vous l’avez compris, l’intérêt pour vous est de définir un combo entre ces trois attributs pour générer énormément de messages.
Par exemple, envoyer 100 messages par user, pour 10 users, pendant 60 secondes, devrait générer 60 000 messages.
Attention cependant, votre machine locale montrera ses limites si vous chargez trop. Il faudra alors switcher sur des plateformes SaaS prévues pour cela tel qu’Octoperf.
Et ensuite ?
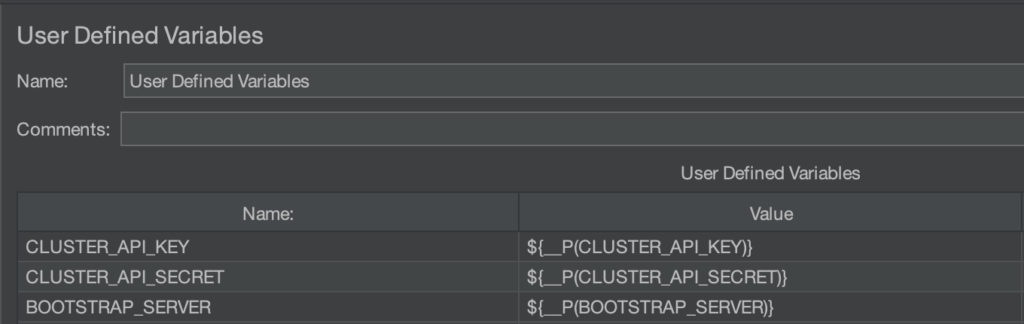
- Si vous souhaitez déployer vos scénarios sur une plateforme, envisagez d’utiliser les
User Defined Variablesafin d’externaliser les valeurs des informations de connexions à votre broker Kafka
Utilisez la syntaxe ${__P(<clé>)} conjointement avec des arguments de lancement de jmeter:
jmeter -JBOOTSTRAP_SERVER=<broker_url>
Ces variables peuvent ensuite être utilisées dans vos valeurs d’éléments de scénario. (exemple : ${BOOTSTRAP_SERVER})
- Partant de cette base de scenario, vous pouvez constituer des jeux de données qui répondront à vos contraintes (règles de gestions, données hard codées, etc)
- Vous pouvez utiliser les
CSV Data Set Configde jMeter pour injecter des valeurs en se basant sur un fichier CSV issue d’un export de données métier. - Si votre fichier AVRO contient des champs de type tableaux, vous pouvez définir le nombre d’itérations à générer via la syntaxe
VotreChamps[5](ce qui générera 5 éléments dans le tableau)
- Vous pouvez utiliser les
Les fonctionnalités de jMeter couplées aux capacités de KLoadGen vous permettrons de répondre, je pense, à l’intégralité de vos besoins, si vous avez le courage de fouiller dans la documentation de ces 2 outils !
