
Actuellement, disposer d’une donnée en temps réel (ou quasi réel) est devenue d’une importance capitale. Que ce soit pour de l’observabilité ou pour de l’analyse business, la réactivité dépend entièrement de la fraicheur et de la qualité des données exploitées.
Dans ce contexte, Confluent et Elasticsearch ont mis en place un partenariat afin d’offrir à leurs utilisateurs un système fiable et scalable d’ingestion de données couplé à un outil de restitution tout aussi fiable, scalable et puissant en termes d’indexation, de reporting et d’analyse.
Confluent Kafka pour l’ingestion
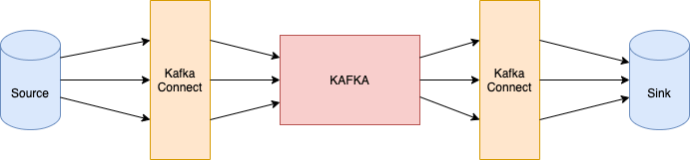
L’utilisation d’Apache Kafka, dont la réputation n’est plus à faire, permet de fluidifier l’ingestion de la donnée ou d’événements. Il est possible d’ingérer rapidement tout type de donnée dans Kafka. Plusieurs solutions s’offrent à vous :
Integration
- Utilisation de Kafka Connect (facilité d’utilisation)
- Composant scalable de l’écosystème Kafka permettant d’instancier des “connecteurs” de façon simple (via configuration).

- Les connecteurs peuvent être de type source ou sink (respectivement vers Kafka et depuis Kafka).
- Il existe de nombreux connecteurs disponibles, indexés dans le Hub de Confluent :
- 90 connecteurs « Confluent supported »
- 63 connecteurs « Partner supported »
- Composant scalable de l’écosystème Kafka permettant d’instancier des “connecteurs” de façon simple (via configuration).
- Implémenter ses propres connecteurs
- Il est possible d’implémenter ses propres producers / consumers Kafka qui pourront injecter/consommer la donnée dans/depuis des topics. (Nécessite du développement, mais permet souvent plus d’agilité que l’utilisation des connecteurs). Kafka Connect repose sur les APIs Producers et Consumer de Kafka.
- Utilisation de composants qui publient nativement dans Kafka :
Processing
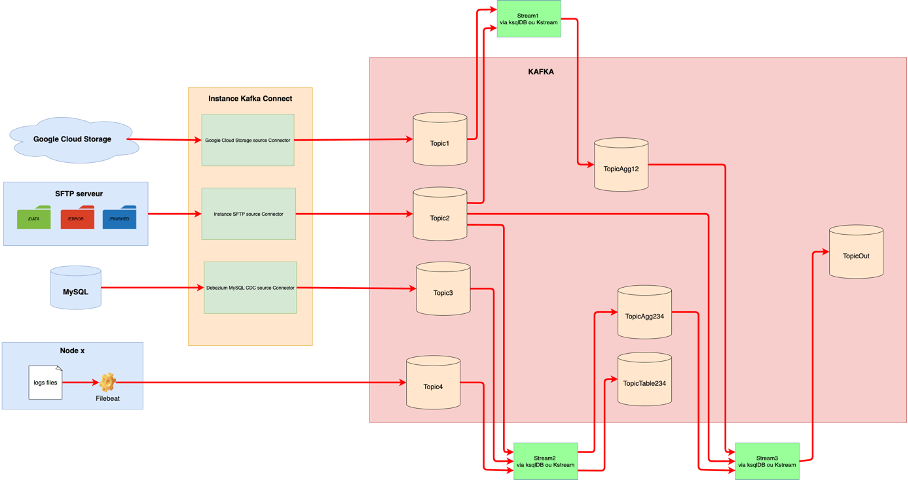
Une fois ces éléments en place, vous pourrez récupérer tout type de donnée dans Kafka (logs, événements, données métiers, …).
Ensuite, afin de nettoyer, de traiter et/ou d’agréger des données provenant de différentes sources, (différents topics), vous avez, encore une fois, plusieurs possibilités :
- Utilisation de ksqlDB
- Outils de l’écosystème Confluent
- Nécessite l’instanciation d’un serveur KsqlDB (qui peut être gourmand)
- Permet, assez facilement, de créer des streams et des tables via un langage très proche du SQL
- Facilité d’implémentation
- Exemple de requête :
-- Register the CUSTOMER data as a KSQL table,
-- sourced from the re-partitioned topic
CREATE TABLE CUSTOMERS WITH \
(KAFKA_TOPIC='CUSTOMERS_SRC_REKEY', VALUE_FORMAT ='AVRO', KEY='ID');
-- Register the RATINGS data as a KSQL stream, sourced from the ratings topic
CREATE STREAM RATINGS WITH (KAFKA_TOPIC='ratings',VALUE_FORMAT='AVRO');
-- Perform the join, writing to a new topic - note that the topic
-- name is explicitly set. If the KAFKA_TOPIC argument is omitted the target
-- topic will take the name of the stream or table being created.
CREATE STREAM RATINGS_ENRICHED WITH \
(KAFKA_TOPIC='ratings-with-customer-data', PARTITIONS=1) AS \
SELECT R.RATING_ID, R.CHANNEL, R.STARS, R.MESSAGE, \
C.ID, C.CLUB_STATUS, C.EMAIL, \
C.FIRST_NAME, C.LAST_NAME \
FROM RATINGS R \
LEFT JOIN CUSTOMERS C \
ON R.USER_ID = C.ID \
WHERE C.FIRST_NAME IS NOT NULL ;
- Utilisation de Kstream
- Nécessite du développement :
- Utilisation de l’API Stream DSL
- Et/ou utilisation de l’API Processor
- Ces implémentation se basent aussi sur les consumers/ producers Kafka
- Permet, comme pour le Ksql, de créer des streams et des tables
- Nécessite du développement :
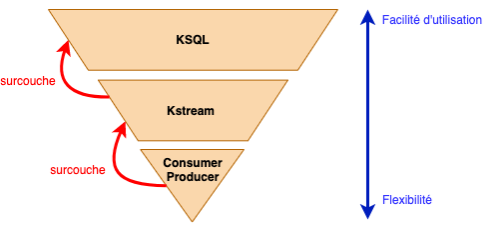
On privilégiera par exemple l’utilisation de KsqlDB afin de tester des agrégations et des comportements facilement, puis ces derniers pourront être implémentés via des Kstream qui permettent plus de possibilités (le code que vous souhaitez).
Exemple d’ingestion et de processing:
Exploitation de la donnée
Une fois la donnée propre et correctement agrégée, il est possible d’utiliser à nouveau la plateforme Kafka Connect avec le connecteur sink Elasticsearch (l’un des premiers connecteurs existant).
Ce connecteur permet de récupérer les données de topics Kafka pour les injecter dans Elasticsearch (encore une fois, via configuration et API).
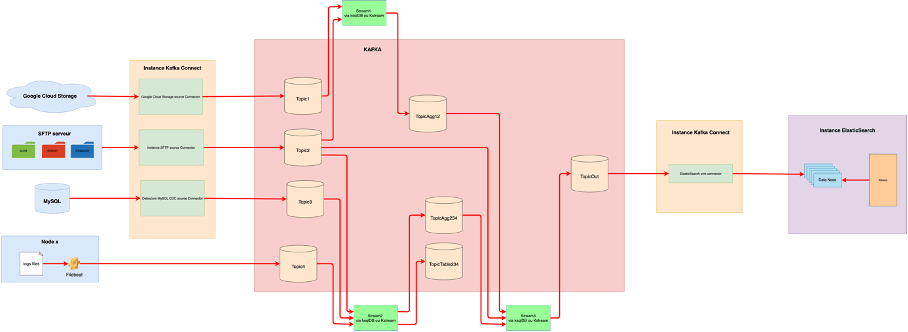
Restitution et analyse de la donnée
À partir de là, vous pouvez profiter de la puissance d’indexation et d’analyse d’Elasticsearch pour créer des dashboard pertinents via Kibana.
De base, dans l’outil d’exploration de Kibana, vous aurez la répartition des valeurs et grâce à l’outil Lens, vous pourrez rapidement et facilement (“drag and drop”) visualiser vos données, créer des facettes, afficher les informations de façon pertinente et créer vos propres dashboards.
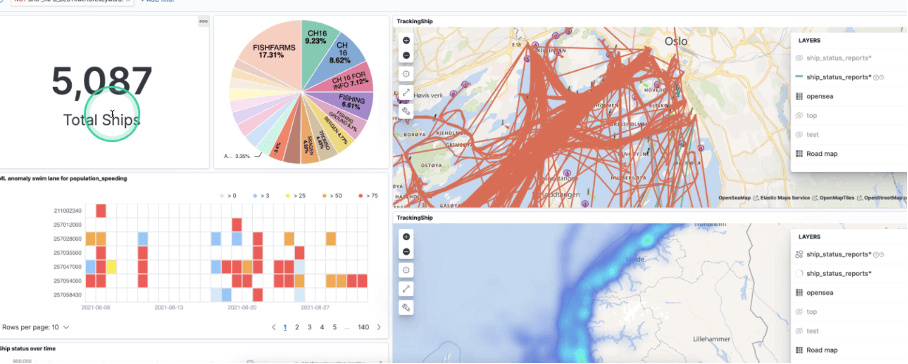
De plus, vous pouvez également profiter de la puissance du machine learning d’Elasticsearch pour faire de la détection d’anomalies, d’aberrations, de comportements anormaux, de faire de la prévision de donnée et de créer des alertes. (L’accès au machine learning est disponible dans la version payante d’Elasticsearch)
Un peu de gouvernance
Pour faire qu’un projet de ce type soit un succès, il est nécessaire d’y ajouter un peu de gouvernance 🙂 En effet, il serait dommageable de pousser tout et n’importe quoi dans Kafka et dans Elasticsearch.
Pour mettre des gardes fous sur ces systèmes, l’écosystème Kafka permet d’utiliser le schema registry, afin de définir des schémas pour chacun de vos topics. Ces schémas doivent être validés par les équipes métiers / architectes d’entreprise dans le but d’échanger les données sur des schémas connus et validés.
L’intégration du schéma dans Elasticsearch, se traduit par la création d’un mapping pour un index. Celui-ci utilise le mapping par défaut d’Elasticsearch. Ce dernier peut souvent convenir, mais dans le cas contraire, il est possible (et souvent nécessaire) d’utiliser les mappings dynamiques afin de les spécifier plus précisément. Rappelons ici l’importance de maitriser ses schémas et ses mappings !!
Dans leur roadmap, Confluent et Elasticsearch prévoient de travailler pour intégrer les données dans Elasticsearch (via le connecteur Kafka) directement dans le format ECS (Elastic Common Schema) et très certainement en OpenTelemetry dans un avenir proche. Cela permettra des corrélations encore plus simples avec les données de sécurité, de log et d’APM.
ElasticSearch Confluent Connector vs logstash
Actuellement, beaucoup de projets utilisent logstash qui, fonctionnellement, permet de faire la même chose que le connecteur. Il est en effet possible d’avoir une entrée Kafka dans la configuration d’un agent Logstash et de pousser les données dans Elasticsearch. Il existe cependant des différences assez importantes.
- Logstash n’est pas proposé dans le cloud
- Installation on premise obligatoirement et au plus près de vos sources ou sink de données.
- Logstash n’a pas de haute disponibilité native.
- Logstash possède plus de possibilité de traitement de la donnée là où le connecteur va se reposer sur le travail fait en amont par les Kstream.
L’investissement d’Elasticsearch dans la transformation de la donnée est plus importante sur les nœuds d’ingestion Elasticsearch que sur Logstash (qui continu d’être maintenu, de par sa forte présence dans les SI).
Pour être clair sur les transformations :
- Si vous utilisez déjà et maitrisez Logstash alors continuez ! L’important est d’avoir les données dans Elasticsearch afin de pouvoir les exploiter.
- Si vous démarrez “from scratch”, sans legacy important, optez plutôt pour un connecteur
- Elasticsearch.
Pour conclure, ce partenariat annonce bien des promesses et la roadmap définit devrait permettre de concurrencer encore plus d’autres solutions d’observabilités / supervision.
A noter que les plateformes cloud Confluent (https://confluent.cloud/) et Elasticsearch (https://cloud.elastic.co) permettent d’instancier très rapidement ces environnements et donc de démarrer très rapidement.
Un des autres objectifs de ce partenariat est de créer des solutions packagées et étendable pour répondre à des use case métiers récurrents… A suivre 🙂
Sources
- https://videos.confluent.io/watch/yQQHjjPfpYXNb98qASKnbv
- https://docs.confluent.io/platform/current/connect/index.html
- https://www.confluent.io/hub/
- https://kafka.apache.org/
- https://www.confluent.io
- https://www.elastic.co/guide/index.html
- https://www.elastic.co/fr/kibana/
- https://www.elastic.co/guide/en/kibana/current/xpack-ml.html

