Etant concerné par les problématiques d’hypervision et de traitements complexes d’évènements techniques, je m’intéresse à plusieurs solutions et notamment StackStorm. Ce produit permet d’exécuter des actions ou des workflows d’actions sur des événements entrants émis par des capteurs et permet donc d’automatiser des processus sur l’arrivée de ces événements.
Introduction
Cet outil est open source et est développé en Python. La première version du produit (v0.8.0) est sortie en mars 2015 et nous sommes actuellement à la version v3.3.0. La communauté est assez active.

Quelques exemples d’utilisation (non-exhaustif) :
- Facilite le troubleshooting : Déclenchement sur des problèmes systèmes détectés par Sensu, New Relic et autres systèmes de monitoring, exécution d’une série de checks sur les serveurs, instances et/ou composants applicatifs puis publication des résultats sur Slack ou Jira par exemple.
- MCO automatique : Identifie et vérifie les problèmes sur les noeuds, blackliste les noeuds défaillants du cluster et envoie des emails aux administrateurs.
- Déploiement continu : Build et test avec Jenkins, provision d’un cluster dans le cloud, ouverture du trafic sur le load balancer et roll-forward ou roll-back en fonction de métriques de performance (par exemple).
- Cloud autoscaling :
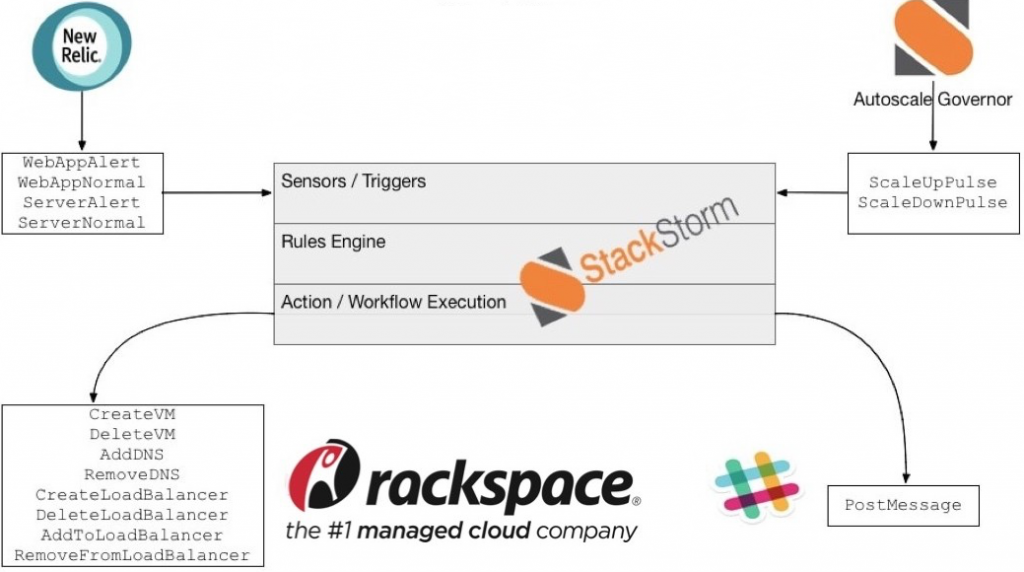
Dans ce cas d’usage, les événements proviennent, via des sensors, de New Relic. Ces événements permettent de savoir quels composants sont impactés par un problème ainsi que la gravité du problème. En fonction des règles implémentées, les actions / workflow déclenchés permettent de créer / supprimer des VMs, créer / supprimer des loadBalancer, ajouter / supprimer des applications des loadBalancer, ajouter / supprimer des DNS…
De cette façon, le scaling des applications peut être géré via les événements de monitoring.
- Exemple Netflix :
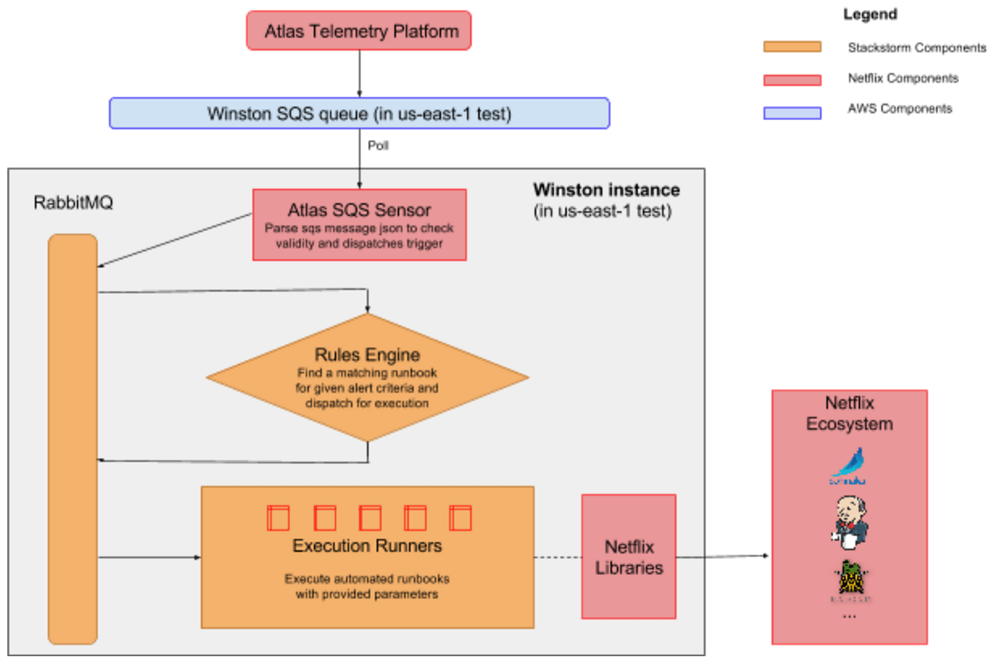
Ici, des événements provenant d’Atlas Telemetry sont postés sur le RabbitMQ de StackStorm. Ces messages déclenchent des triggers qui eux même matchent des règles métiers. Ces règles, à leur tour, déclenchent des actions / workflow afin d’exécuter des actions dans l’environnement Netflix.
- Autre exemple :
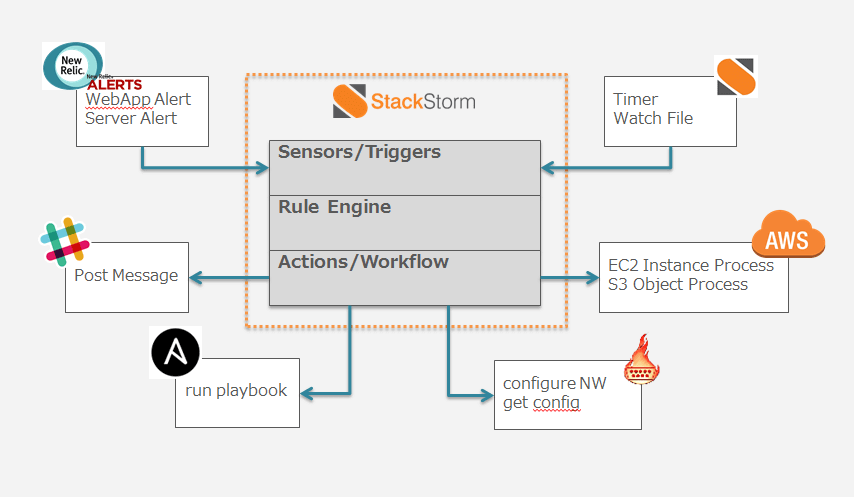
Dans cet exemple, les événements proviennent (encore) du monitoring (NewRelic). Les règles métiers implémentées permettent d’activer des actions / workflows afin de commissionner / décommisionner des instances AWS (EC2, S3,…), exécuter des playbook Ansible, de notifier les équipes en publiant des messages sur Slack, …
Principes
Architecture stackstorm
Comme précisé en préambule, des capteurs génèrent des événements, ces derniers déclenchent des triggers. Les triggers sont liés à des règles permettant d’éventuellement filtrer les données et de définir une action ou un workflow d’actions à exécuter.
Voici un schéma d’architecture “classique” de la solution StackStorm :

Voyons ensemble les composants qui définissent cette architecture.
Les capteurs
Les capteurs sont le moyen d’intégrer des systèmes et des événements externes. Pour faire cela, ils déclenchent des triggers, qui peuvent être mis en correspondance par des règles à l’exécution potentielles d’actions et/ou workflow (via RabbitMQ).
Si vous souhaitez plus d’information sur les développements de sensor, c’est ici.
Les règles
StackStorm utilise des règles pour capturer les événements des triggers.
Une règle est déclenchée par un et un seul trigger.
Ces règles déclenchent une action ou un workflow.
Les triggers
Les triggers sont des composants StackStorm qui identifient les événements entrants.
Les règles sont écrites pour être déclenchées par ces triggers.
Les capteurs enregistrent généralement des triggers bien que cela ne soit pas obligatoire. (Par exemple, le trigger webhooks générique ne nécessite pas de capteur) .
Les workflows
Les workflow permettent de gérer un enchainement d’actions. Stackstorm supporte Orquesta et ActionChain
- Orquesta → pour les nouveaux process.
- ActionChain → pour les workflows “legacy” simples.
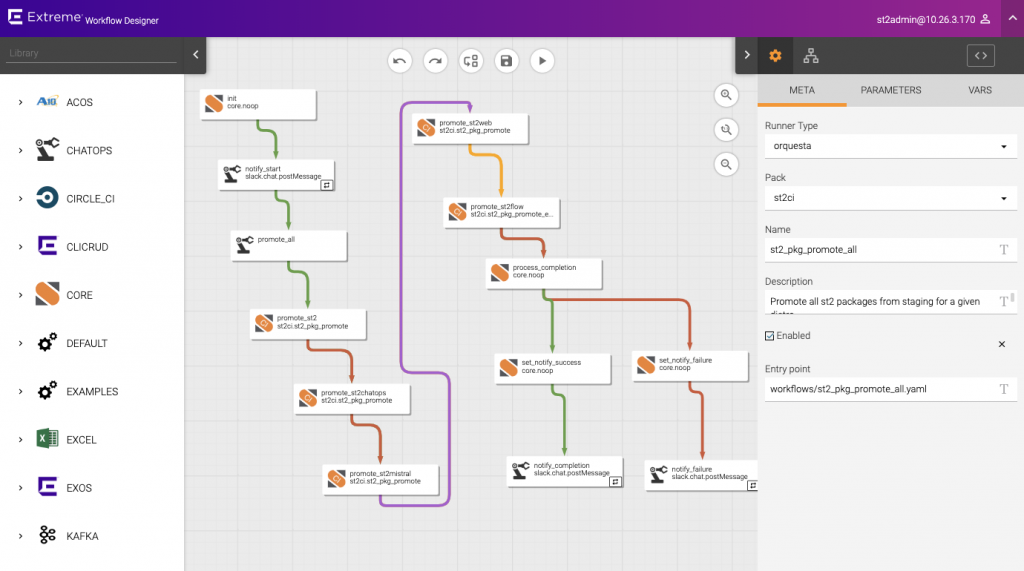
Les worflows sont définis via un fichier YAML. Il existe une interface web permettant de créer ces workflows :
Les actions
Les actions peuvent effectuer, par exemple, des tâches d’automatisation ou de correction dans l’environnement.
Une action est composée de deux parties :
- Un fichier de métadonnées YAML qui décrit l’action et ses entrées.
- Un fichier script qui implémente la logique d’action.
Le script d’action peut être écrit dans n’importe quel langage de programmation (on trouve beaucoup d’exemples en Python), à condition qu’il respecte ces critères :
- Il doit renvoyer zéro en cas de succès et différent de zéro en cas d’erreur.
- Tous les logs doivent être envoyés sur la sortie d’erreur standard.
Voici quelques exemples d’actions (non exhaustif) :
- redémarrer un service sur un serveur
- créer un nouveau serveur dans le cloud
- acquitter des alertes
- envoyer une notification / alerte par mail / SMS / channel IRC…
- poster un message sur slack
- démarrer un conteneur Docker
- réaliser un snapshot d’une VM
- exécuter un check Nagios
- …
Si vous souhaitez plus d’information sur les développements d’action, c’est ici.
Fonctionnement
Voyons a présent le fonctionnement interne de l’outils. Ci dessous un schéma représentatif de ce fonctionnement.

- Un événement est capter par un capteur
- Le capteur déclanche un trigger
- Le trigger matche (ou pas) une / des règle(s) via des critères
- L’éxecution d’une action / d’un workflow est planifié
- L’action / Le worflow est exécuté
Test de Stackstorm sous Docker
Afin de tester “rapidement”, j’ai décidé de monter la plateforme via docker-compose.
Voici les principales images montées par le docker-compose :
- stackstorm/st2api:3.3.0
- stackstorm/st2sensorcontainer:3.3.0
- stackstorm/st2rulesengine:3.3.0
- stackstorm/st2actionrunner:3.3.0
- stackstorm/st2workflowengine:3.3.0
- stackstorm/st2scheduler:3.3.0
- mongo:4.0
- rabbitmq:3.8
- redis:6.0
Ce docker-compose aura pour effet de monter une infrastructure de ce type (hors ngnix et hubot):
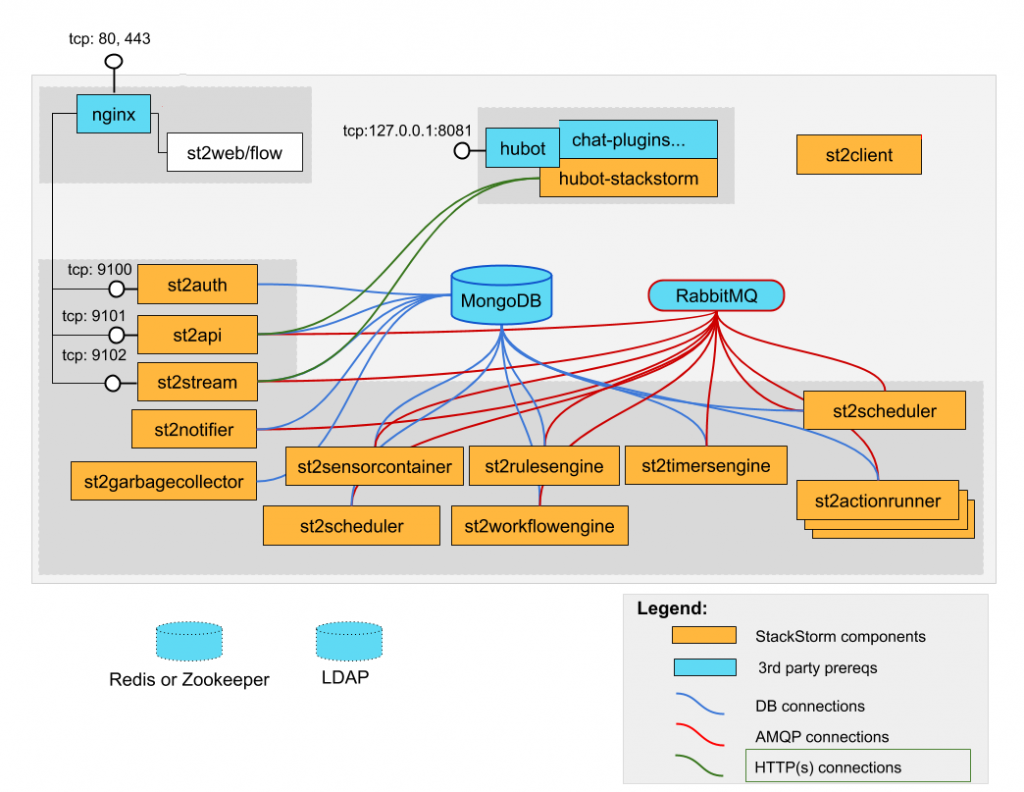
Afin d’interagir avec la plateforme, il y a plusieurs possibilités:
- L’interface web
- Le CLI
- L’API
L’interface web et le CLI utilise l’API.
Notre environnement de test est à présent démarré et fonctionnel, détaillons quelques petits scénarios pour tester et éprouver l’outil.
Scenario 1 – Webhook (exemple de la documentation)
Trigger :
- core.st2.webhook, déclanché sur l’url /ineat
Critères
- si le champ name du body vaut “test”
Action
- core.local, création d’un fichier local contenant l’ensemble du body
sample2_rule_with_webhook.yaml :
{
"tags": [],
"uid": "rule:ineat:sample_rule_with_webhook",
"metadata_file": "",
"name": "sample_rule_with_webhook",
"ref": "ineat.sample_rule_with_webhook",
"description": "Sample rule dumping webhook payload to a file.",
"pack": "ineat",
"type": {
"ref": "standard",
"parameters": {}
},
"trigger": {
"type": "core.st2.webhook",
"parameters": {
"url": "ineat"
},
"ref": "core.504f5fc7-72b7-4a6b-8759-3805c0a4296b",
"description": "Trigger type for registering webhooks that can consume arbitrary payload."
},
"criteria": {
"trigger.body.name": {
"pattern": "test",
"type": "equals"
}
},
"action": {
"ref": "core.local",
"parameters": {
"cmd": "echo \"{{trigger.body}}\" >> /tmp/ineat.webhook_sample.out ; sync",
"sudo_password": "Ch@ngeMe"
},
"description": "Action that executes an arbitrary Linux command on the localhost."
},
"context": {
"user": "st2admin"
},
"enabled": true,
"id": "5fa3b7abefbface9864e1fb7"
}Création de la règle via le CLI:
st2 rule create /tmp/sample2_rule_with_webhook.yaml Test
HTTP POST sur l’url:
curl -k http://localhos/api/v1/webhooks/ineat -d '{"foo": "bar", "name": "test"}' -H 'Content-Type: application/json' -H 'X-Auth-Token: <oauth_token>'Vérification de la bonne exécution, le paramètre “-n” et sa valeur “1” permettent d’afficher uniquement la dernière exécution :
st2 execution list -n 1Vérification de la création du fichier :
sudo tail /tmp/ineat.webhook_sample.outScenario 2 – CronLike
Trigger
core.st2.IntervalTimer, déclenché toutes les 5 secondes
Critères
- pas de critères
Action
core.local, création d’un fichier horodaté
sample_rule_with_cron.yaml :
{
"tags": [],
"uid": "rule:ineat:sample_rule_with_cron",
"metadata_file": "",
"name": "sample_rule_with_cron",
"ref": "ineat.sample_rule_with_cron",
"description": "Sample rule dumping cron payload to a file.",
"pack": "ineat",
"type": {
"ref": "standard",
"parameters": {}
},
"trigger": {
"type": "core.st2.IntervalTimer",
"parameters": {
"unit": "seconds",
"delta": 5
},
"ref": "core.8106636c-3128-42a7-b7ae-ea9ddd957550",
"description": "Triggers on specified intervals. e.g. every 30s, 1week etc."
},
"criteria": {},
"action": {
"ref": "core.local",
"parameters": {
"cmd": "echo \"trigger.body\" >> /tmp/cron_sample.%Y%M%d%h%m.out ; sync",
"sudo_password": "Ch@ngeMe"
},
"description": "Action that executes an arbitrary Linux command on the localhost."
},
"context": {
"user": "st2admin"
},
"enabled": false,
"id": "5fa3ff21b4ddaf557eb117ff"
}Scenario 3 – ElasticSearch
- Installation du pack ElasticSearch
Afin de faire ce scénario, j’ai installé le pack ElasticSearch (il est possible de le faire via le CLI mais aussi via l’interface web). Attention, lors de l’installation du sensor, le répertoire du pack (/opt/stackstorm/virtualenvs/<pack name>) ne se trouve pas sur le conteneur st2client mais sur l’instance st2sensorcontainer (docker).
- Réglage des hosts entre les containers
Dans le fichier “st2.user.conf” (fichier monté dans les instances Docker), j’ai modifié les hosts pour MongoDB et RabbitMQ afin que la communication puisse se faire correctement.
- Configuration du pack
Dans le fichier /opt/stackstorm/configs/elasticsearch.yaml
root@e15096e2b17c:/opt/stackstorm# more configs/elasticsearch.yaml
host: "192.168.43.53"
port: 9210
query_window: 30 #Size in seconds of rolling window
query_string: "{\"match\":{\"name\":\"testing\"}}" #ES DSL bool must
cooldown_multiplier: 1 #Multiple of query window to cooldown after successful hit
count_threshold: 5 #Minimum number of hits before emitting trigger
index: "test*"
Cette requête remonte les documents dont l'attribut "name" vaut "testing" sur les 30 dernières secondesLes documents Elasticsearch doivent avoir un attribut @timestamp
Ce pack ne comporte qu’un seul trigger sans paramètre déclaré. La configuration est donc unique pour le sensor. On ne peut paramétrer qu’une seule requête sur un pattern d’index.
Trigger :
elasticsearch.count_event. Ce trigger se déclenche quand la requête exécutée par le sensor remonte plus de X éléments (porté par la configuration du sensor)
Critères :
- pas de critères
Action :
elasticsearch.indices.create_index. Création d’un autre index (ssz-%Y.%m.%d.%h)
{
"tags": [],
"uid": "rule:ineat:sample2_rule_with_es",
"metadata_file": "",
"name": "sample2_rule_with_es",
"ref": "ineat.sample2_rule_with_es",
"description": "Sample rule ES.",
"pack": "ineat",
"type": {
"ref": "standard",
"parameters": {}
},
"trigger": {
"type": "elasticsearch.count_event",
"parameters": {
"query": "{\"match\":\"testing\"}"
},
"ref": "elasticsearch.74e3eea3-69ad-4a31-bed9-f8a41da24730",
"description": "Trigger which represents the exceeded count threshold"
},
"criteria": {},
"action": {
"ref": "elasticsearch.indices.create_index",
"parameters": {
"log_level": "WARNING",
"host": "192.168.43.53",
"port": "9200",
"name": "ssz-%Y.%m.%d"
},
"description": "Create index"
},
"context": {
"user": "st2admin"
},
"enabled": true,
"id": "5fa427ae339287a605cf5ed8"
}Dans cette exemple, quand nous aurons plus de cinq documents ayant l’attribut “name” à “testing” dans les index matchant le pattern “test*” dans les trente dernières secondes, nous créerons un nouvel index horodaté.
L’interface web
Une fois démarrée, la plateforme expose une interface web que nous allons rapidement détailler
History

Dans la partie historique, il est possible de visualiser :
- Les actions qui se sont déroulées
- L’origine des actions (règle, manuel)
- L’état des actions (OK, KO, en cours)
- Les erreurs
Il est également possible de rejouer les actions (KO/OK) :

- Les paramètres dépendent du type d’action
Actions
Dans cette partie, nous pouvons:
- Visualiser l’ensemble des actions disponibles (dans les packs installés, ici : Chatops, Core, Docker, ElasticSearch, Email, Linux, Packs et Twitter)
- Tester les actions
- Visualiser l’history pour l’action sélectionnée

Rules
Dans cette partie, il est possible de :
- Visualiser les règles existantes (ici sample2_rule_with_es dans le pack ineat)
- Activer/désactiver une règle
- Supprimer une règle
- Editer une règle
Sur une règle, on visualise :
- Le trigger (déclenché par un sensor) ici elasticsearch.count_event
- Les critères quand il y en a (optionnels)
- Les actions / workflow
- Le json généré par la règle

Créer de nouvelles règles
- On appréciera les listes déroulantes sur les triggers, les paramètres des triggers, les actions… La saisie est relativement simple.
- Les paramètres dépendent du trigger choisi (certains n’ont pas de paramètres) et des actions choisis.

Packs
Dans cette partie, il est possible de :
- Visualiser les packs installés (ici Chatops, core, Docker, Elasticsearch, email, Linux, packs et Twitter)
Un pack se compose potentiellement de :
- Actions
- Rules
- Sensors / triggers
- Tests

- Installer un nouveau pack :

- Liste des packs disponible : https://exchange.stackstorm.org/
Triggers
Dans cette partie, nous pouvons visualiser:
- Les triggers disponibles dans les packages.
- Les paramètres disponibles au niveau du trigger.
- Les informations disponibles à la sortie du trigger et pouvant être manipulées dans les critères.

- L’historique des instances passées du trigger.

Inquiries
Cette partie permet de mettre en pause un workflow afin d’attendre de plus amples informations. Plus de détails.
CLI
Je vais présenter ici quelques commandes du CLI. Je ne mets volontairement pas le retour des commandes, cela serait trop verbeux dans l’article.
Packs
#Lister les packs installés
st2 pack list
#Afficher le détail d'un pack
st2 pack get elasticsearch
#Installation d'un pack (activedirectory par exemple)
st2 pack install activedirectoryLors de l’installation de pack, si vous êtes sous Docker, il faut savoir :
- Si vous utilisez le conteneur st2client pour lancer ces commandes (comme recommandé), le répertoire du pack ne se trouvera pas sur ce container mais dans le container st2sensorcontainer (/opt/stackstorm/virtualenvs/<pack name>)
Si votre sensor ne fonctionne pas:
- Vérifier qu’il est enregistré :
st2 sensor listS’il n’est pas enregistré, recharger la configuration :
sudo st2ctl reload --register-sensors --register-fail-on-failure --verboseVérifier que l’environnement virtuel est créé :
/opt/stackstorm/virtualenvs/<pack name> doit exister dans le container st2sensorcontainerVérifier les logs du sensor :
/opt/stackstorm/st2/bin/st2sensorcontainer --config-file=/etc/st2/st2.conf --debug --sensor-ref=pack.SensorClassNameSensors
#Lister les sensors installés
st2 sensor list
#Afficher le détail d'un sensor
st2 sensor get elasticsearch.ElasticsearchCountSensorTriggers
#Lister les triggers installés
st2 trigger list
#Afficher le détail d'un trigger
st2 trigger get elasticsearch.count_event Actions
#Lister les actions installées
st2 action list
#Afficher le détail d'une action
st2 action get elasticsearch.indices.create_index
#Exécution manuelle d'une action
st2 run core.local cmd=date --trace-tag="simple-date-check-`date +%s`"
st2 run core.http method=POST body='{"you": "too", "name": "test"}' url=https://localhost/api/v1/webhooks/ineat headers='x-auth-token=<oauth_token>,content-type=application/json' verify_ssl_cert=FalseWorkflow
Le principe est le même avec Orquesta ou ActionChain
- Création d’un fichier meta.
---
name: orquesta-sequential
pack: examples
description: A basic sequential workflow.
runner_type: orquesta
entry_point: workflows/orquesta-sequential.yaml
enabled: true
parameters:
name:
required: true
type: string
default: Lakshmi- Création du fichier d’actions
version: 1.0
description: A basic sequential workflow.
input:
- name
vars:
- greeting: null
output:
- greeting: <% ctx().greeting %>
tasks:
task1:
action: core.echo message=<% ctx().name %>
next:
- when: <% succeeded() %>
publish: greeting=<% result().stdout %>
do: task2
task2:
action: core.echo
input:
message: "All your base are belong to us!"
next:
- when: <% succeeded() %>
publish:
- greeting: <% ctx("greeting") %>, <% result().stdout %>
do:
- task3
task3:
action: core.echo message=<% ctx('greeting') %>
next:
- when: <% succeeded() %>
publish: greeting=<% result().stdout %>
- Enregistrement du workflow
st2 action create packs/examples/actions/orquesta-sequential.yaml- Test du worflow
st2 run examples.orquesta-sequential name=Ineat- Visualisation de l’exécution dans l’interface :

Executions
#Lister les exécutions passées
st2 execution list
#Afficher le détail d'une exécution
st2 execution get 5fa3d65e2210968fb9a0df63Rules
#Lister les rules
st2 rule list
#Afficher le détail d'une rule
st2 rule get ineat.sample2_rule_with_es
#Création d'une rule
#Création d'un fichier yaml de définition (ex: sample2_rule_with_es.yaml)
#Ajout de la règle sur la plateforme
st2 rule create /tmp/sample2_rule_with_es.yaml
#Mise a jour de la règle
st2 rule update ineat.sample2_rule_with_es /tmp/sample2_rule_with_es.yaml
#Supression de la règle
st2 rule delete ineat.sample2_rule_with_esConclusion
Cette plateforme a donc fait ses preuves au fil du temps et peut facilement s’intégrer dans un ou plusieurs SI hétérogènes.
La prise en main est simple et la documentation est bien faite. La communauté est active et fourni beaucoup de packs. Attention malgré tout, beaucoup de packs sont en version 0.X. Le pack ElasticSearch testé ici montre rapidement ses limites et je pense que le mieux pour s’adapter aux différents besoins est de développer ses propres capteurs/actions. (Si on ne trouve pas notre bonheur dans les packs existants)
L’installation en production serait plus complexe de par le nombre de composants mis en oeuvre (les composants spécifiques StackStorm + Redis + RabbitMQ + MongoDB) mais également la mise en cluster de certains composants (RabbitMQ, MongoDB, Redis). En test, la version docker est relativement simple à mettre en place et permet rapidement de prendre en main l’outil.
L’API est complète et donc les fonctionnalités proposées par l’interface web et le CLI le sont aussi.
SatckStorm a de solides références : Cisco, Nasa, Netflix… ce qui rassure sur la robustesse de cette plateforme.

