Les nouvelles architectures techniques et l’avènement du cloud ont posé autant de défis que d’opportunités dans nos systèmes d’information. Les GAFAM et autres géants d’Internet ont habitué les utilisateurs à des applications performantes et résilientes. La puissance de nos smartphones, de nos ordinateurs, du cloud et de nos réseaux (fibre, 4G, bientôt 5G…) offre toujours plus de possibilités. Cependant, la performance est aussi fortement liée aux développements que nous effectuons, à l’usage des bons patterns, au stockage des données, à l’évolution de la charge, aux différentes fonctionnalités mises en place… Pour bien maîtriser tous ces aspects, nous devons être capables de tester et mesurer de manière continue la performance.
Alors quand un projet débute, on pense souvent frameworks, déploiement, stacks techniques… mais aussi à la qualité du produit fini. Et qui dit qualité ne dit pas uniquement Tests de Non Régression ( TNR ) et lisibilité de code. La performance offerte par l’application est aussi essentielle que l’absence de bug. Par exemple une application lente ou régulièrement indisponible, faute de ressources suffisantes, perd la confiance de l’utilisateur.
Pourtant cet aspect est régulièrement mis de côté par faute de temps ou par simple méconnaissance des outils de perf-test disponibles.
Nous vous proposons dans cet article un comparatif d’outils fréquemment utilisés (en dehors de certains pure players comme AppDynamics, Dynatrace, NewRelic…) afin de vous aiguiller dans vos choix futurs. Simplicité de prise en main, langages supportés, extensibilité… vous saurez tout sur ces technologies de load testing.
Au sommaire :
- Déroulement du comparatif
- JMeter, vétéran qui a déjà fait ses preuves
- Gatling pour un mitraillage en règle de vos applications
- K6, ajoutez une touche fruitée à vos tests
- Locust, véritable essaim pour tester vos applications
- En définitive, y-a-t-il vraiment un vainqueur ?
- Liens utiles
Déroulement du comparatif
Notre étude ne consistait pas uniquement à évaluer les principales features de quelques outils sélectionnés aléatoirement, l’idée étant bien de donner une vue globale des capacités de telle ou telle solution afin de vous aider à orienter vos choix.
Certes, des points comme la prise en main ou le support ont été analysés, mais des aspects plus techniques ont également été abordés durant notre comparatif et ce au travers de tests en conditions réelles sur l’application Petclinic de Spring :
- un test de charge classique (100 utilisateurs simultanés) → via un seul nœud master
- un test de montée en charge (nombre d’utilisateurs de départ à 100, avec une augmentation de 100 utilisateurs toutes les minutes pendant 10 minutes ) → via un cluster multi nœuds (master + 2 slaves)
- un stress test (pour 4000 virtual users en simultané) → via cluster multi nœuds (master + 2 slaves par exemple)
Cela nous a permis de mettre en exergue des indicateurs relatifs à la complexité d’écriture des tests, mais aussi à leur mise en oeuvre dans un environnement distribué.
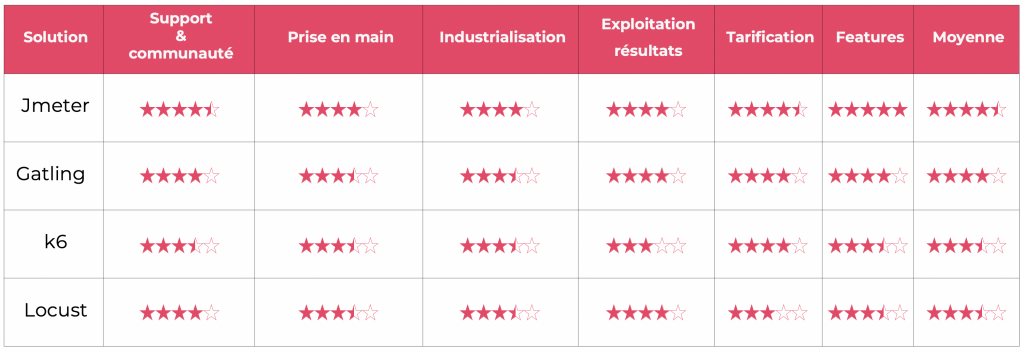
En outre quatre outils ont été retenus dans notre bench : Jmeter, Gatling, k6 et Locust. Chacun ayant fait l’objet d’études sur :
- Le support et la communauté
- La complexité de prise en main
- L’industrialisation de la solution (c’est-à-dire de quelle façon ces outils peuvent être partie prenante de votre chaine d’intégration continue)
- L’exploitation des résultats (sont-ils représentés de façon brute, ou des rapports concis sont-ils mis à disposition des utilisateurs ?)
- Tarification (la solution évaluée est-elle utilisable en mode SaaS ? Si oui quels sont les tarifs proposés ?).
- Fonctionnalités utiles (quelles sont les fonctionnalités qui peuvent nous faire gagner du temps au quotidien ?)
Voilà pour le contexte, passons en revue les challengers !
JMeter, vétéran qui a déjà fait ses preuves

Support & Communauté
Note : 4,5/5
Développé par la Fondation Apache et sorti en première version en 2006, JMeter fait aujourd’hui référence en matière de test de performance.
Majoritairement développé en Java et très bien documenté, JMeter est également extensible via des plugins (proposés par la communauté, ou développés par vos soins).
Concernant la communauté justement, elle compte à ce jour 29 contributeurs “principaux”. Enfin, la dernière release du projet date du 15 Mai dernier (à un rythme de 2 ou 3 releases annuelles).
Prise en main
Note : 4/5
Bien qu’aujourd’hui la tendance soit au “Everything As Code” (Infrastructure As Code, Deployment As Code, …) et contrairement à ce que propose ses concurrents, JMeter garde sa ligne de conduite en fournissant une interface graphique permettant de “composer” ses campagnes de tests. Pas de scénario écrit dans un quelconque DSL, il faudra donc remplir quelques formulaires de l’interface…du moins en apparence ! Car JMeter dispose également d’API permettant d’écrire des campagnes directement en Java.
La première approche (c’est à dire l’utilisation de l’UI) a ses avantages, et notamment le fait qu’il n’est donc pas nécessaire de savoir coder pour créer un test de performance sous JMeter. Cependant l’interface, dont l’ergonomie reste perfectible, pourra paraître déstabilisante pour certains. Une petite période d’adaptation et de prise en main du GUI sera alors parfois nécessaire.
Industrialisation
Note : 4/5
Tester les performances de son application “une fois de temps en temps” n’a pas de sens. L’évaluation des performances s’inscrit dans la durée et doit donc être réalisée très régulièrement, et ce tout au long du cycle de vie d’un projet.
L’intégration de ce processus dans la chaine d’intégration continue apparait comme une évidence.
Mais quelles sont les solutions de CI supportant JMeter ? Rassurez-vous la plupart le sont ! JMeter peut être exécuté “directement”. Par ailleurs, Jenkins propose un Performance Plugin afin de simplifier davantage cette intégration.
On notera également la possibilité de s’appuyer sur Taurus, framework OpenSource permettant d’automatiser des campagnes de tests (JMeter, mais pas que 😁 ).
Les irréductibles codeurs apprécieront sans doute Taurus, qui permet de configurer une campagne de tests sans avoir à mettre les mains dans l’interface de JMeter, uniquement en manipulant quelques fichiers Yaml 😉
Mais au-delà du branchement à la CI l’exécution de tests de performance implique la simulation d’un nombre très important d’utilisateurs (appelés Virtual Users, ou “VU”), chose difficile voire impossible avec une seule machine : en fonction de la configuration de celle-ci le nombre de VU est plus ou moins limité. En effet le nombre de CPU disponibles, la mémoire allouée, … sont directement impactés par des facteurs tels que le nombre de requêtes exécutées ou la taille des réponses.
Pour pallier à cela, la plupart des outils de perftest disposent d’un mode distribué et JMeter ne fait pas exception. Ainsi, il est tout à fait possible de créer un cluster de machine dédié à l’exécution des tests. Comme précisé un peu plus haut, nous nous sommes appuyés pour notre bench sur un nœud master, et deux slaves.
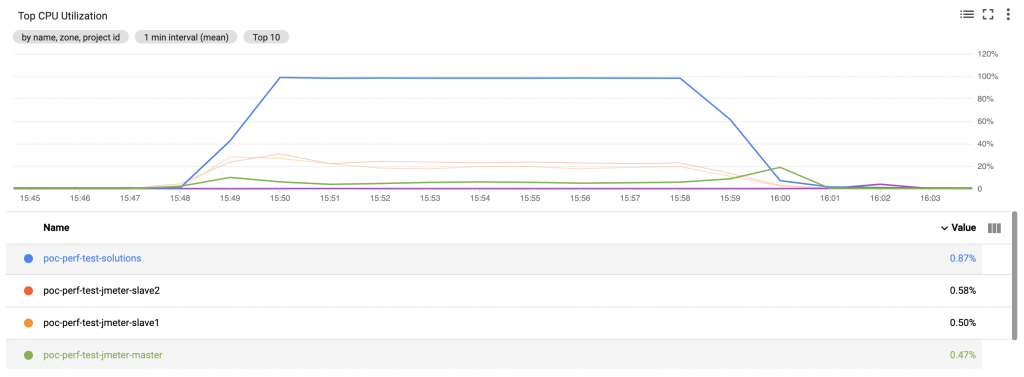
Mais cette mise en oeuvre s’est-elle faite sans douleur ?
Et bien oui et non, un certain nombre de facteurs devant être pris en compte :
- Les firewalls des systèmes doivent être désactivés et les ports corrects ouverts
- Serveurs et clients sont tous sur le même sous-réseau
- Bien entendu JMeter doit pouvoir accéder au serveur
- JMeter et Java sont utilisés dans la même version sur l’ensemble des nœuds du cluster
- RMI doit être activé sur le cluster exécutant les tests, et SSL correctement configuré (ou à défaut désactivé)
Exploitation des résultats
Note : 4/5
Une fois les tirs de performances réalisés, un rapport est généré par JMeter. Ce dernier est disponible au format HTML, mais peut également être exporté en JSON.
Outre ces rapports, les résultats peuvent être exploités au sein de dashboards Grafana, ceux-ci étant au préalable centralisés par une instance Graphite ou Prometheus.
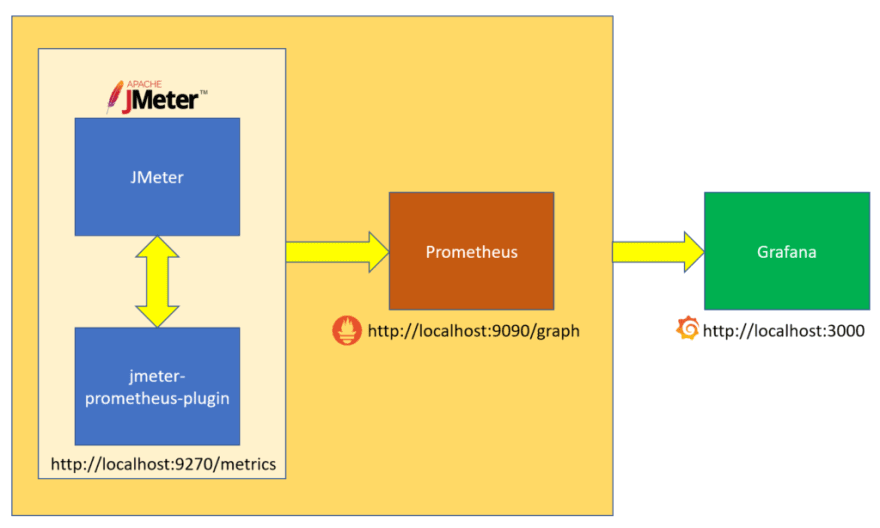
JMeter / Prometheus / Grafana
(source: https://dev.to/qainsights/jmeter-prometheus-and-grafana-integration-312n)
Tarification
Note : 4,5/5
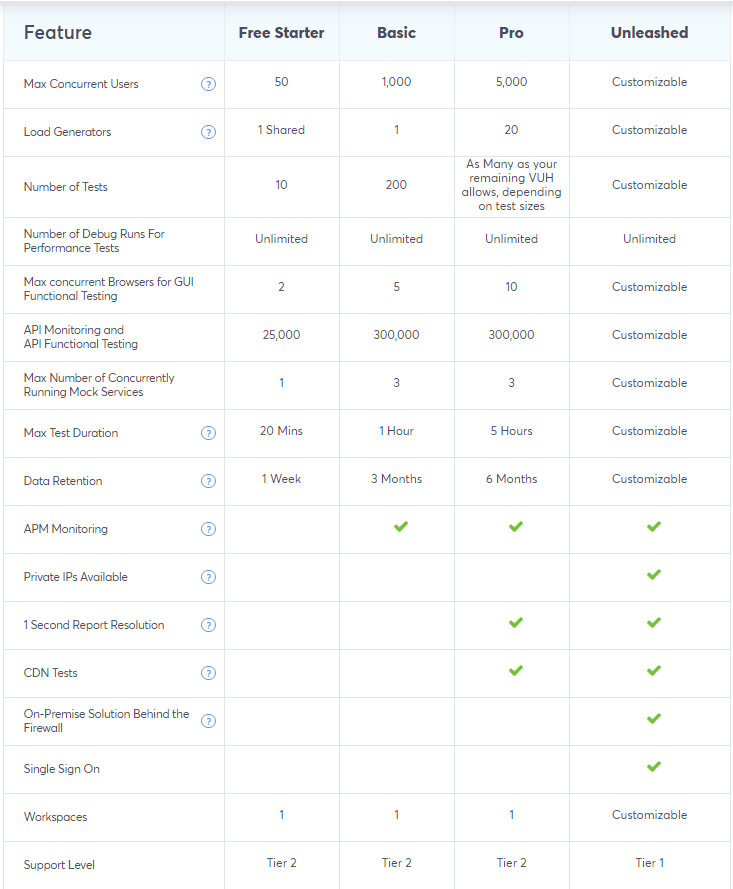
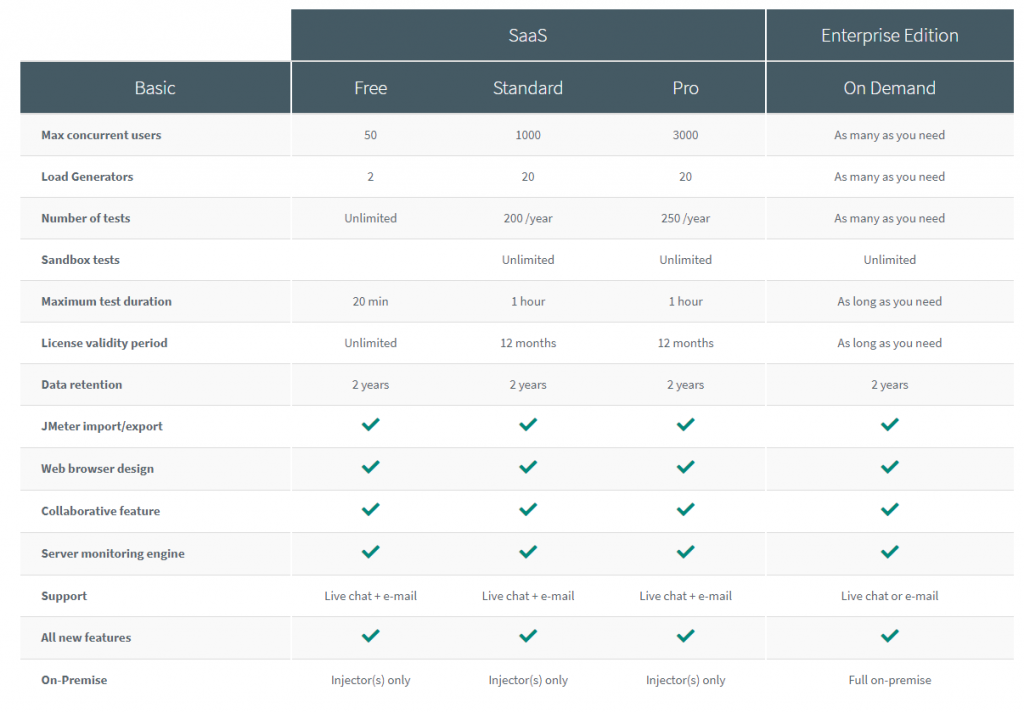
La mise en oeuvre d’une infrastructure dédiée aux tests de performances avec JMeter peut être longue et fastidieuse, mais fort heureusement plusieurs entreprises proposent des solutions SaaS clé en main. C’est le cas de Blazemeter et Octoperf.
A titre informatif, voici les tableaux récapitulatifs des offres proposées par ces deux sociétés :
Fonctionnalités utiles
Note : 5/5
C’est sans doute l’atout majeur de JMeter : le nombre de fonctionnalités proposées, dont voici un échantillon :
- Capacité à charger et à tester les performances de nombreux types d’applications / serveurs / protocoles différents (Web – HTTP / HTTPS, SOAP, REST, FTP, JDBC, LDAP, MOM via JMS, Messagerie – SMTP / POP3 / IMAP, TCP, Objets Java, Scripts Shell, …).
- IDE de test complet qui permet l’enregistrement rapide du plan de test (à partir de navigateurs ou d’applications natives), la construction et le débogage.
- Mode CLI (mode ligne de commande) pour charger le test depuis n’importe quel OS compatible Java (Linux, Windows, Mac OSX…).
- Un rapport HTML dynamique complet.
- Corrélation facile grâce à la capacité d’extraction des données des formats de réponse les plus courants, HTML, JSON, XML ou tout autre format textuel.
- Framework multithreading complet permettant l’échantillonnage simultané par de nombreux threads et l’échantillonnage simultané de différentes fonctions par des groupes de threads séparés.
- Mise en cache et analyse / relecture hors ligne des résultats des tests.
- Noyau hautement extensible (Pluggable Samplers offrant des capacités de test illimitées, multiplicité des statistiques de charge possible via les Pluggable Timers, visualisation / analyse / personnalisation des données simplifiées par des plugins mis à disposition par la communauté, …).
Moyenne : 4,33/5
Gatling pour un mitraillage en règle de vos applications
Support & Communauté
Note : 4/5
Fort d’une communauté de plus de 150 contributeurs et téléchargé plus de 800 000 fois durant ses 5 premières années d’existence, Gatling a su se faire un nom dans le cercle relativement restreint du perf testing. Créé en Janvier 2012 et sortie en v3.3 en Juillet 2020, Gatling faisait à ses débuts pâle figure face au géant JMeter. Mais les manques semblent avoir été comblés (comme nous le verrons un peu plus loin) et se pose aujourd’hui en véritable alternative à JMeter : David aurait-il su rattraper Goliath ?
Majoritairement développé en Scala et Akka, l’arme de destruction massive développée par Stéphane Landelle peut-elle être mise entre toutes les mains ?
Prise en main
Note : 3,5/5
…et bien oui et non. L’outil dispose depuis quelques temps d’un recorder, chose qui lui faisait particulièrement défaut face à JMeter. Le DSL permettant d’écrire les scénarios est assez simple à prendre en main, puisqu’il s’agit de simples classes Scala qui étendent l’objet Simulation :
class PetClinicSimulation extends Simulation {
// ...
object AddPet1 {
val addPet = exec(
http("Pet Creation") // let's give proper names, as they are displayed in the reports
.post("/petclinic/api/pets")
.body(StringBody("""{ "birthDate": "2019/09/01", "id": 0, "name": "Roger", "owner": { "id": ${ownerId}, "firstName": "${ownerFirstName}", "lastName": "${ownerLastName}", "address": "${ownerAddress}", "city": "${ownerCity}", "telephone": "${ownerTelephone}", "pets": [] }, "type": { "id": 1, "name": "cat" }, "visits": []}""")).asJson
.check(jsonPath("$.id").saveAs("pet1Id")))
.pause(5)
}
//...
val petClinic = scenario("FullScenario").exec(CreateUser.createUser, AddPet1.addPet, ... )
//...
Un appel à la fonction setUp depuis votre code vous permettra de spécifier le nombre d’utilisateurs virtuels, la durée d’une simulation…
//...
setUp(
petClinic.inject(constantConcurrentUsers(2) during (10 seconds))).protocols(httpProtocol)
On notera également la présence de plugins et dépendances Maven, Gradle et SBT qui faciliteront l’initialisation d’un projet de tests. Mais la présence de ces éléments ne suffissent pas et Gatling pêche parfois par le manque d’information de sa documentation officielle : un novice pourrait avoir quelques difficultés notamment lors du setup de l’outil.
Industrialisation
Note : 3,5/5
Côté industrialisation, sachez que Gatling dispose d’une image Docker officielle, et qu’il est donc possible de s’appuyer sur celle-ci pour démarrer un conteneur qui sera ensuite utilisé dans vos pipelines Jenkins, GitlabCI, ConcourseCI, … bref quel que soit votre écosystème ! Vous n’aurez donc aucune difficulté dans la mise en oeuvre de Gatling au sein d’une CI.
La véritable faille réside plutôt dans l’exécution distribuée des simulations car il n’existe tout simplement pas de mode cluster dans la version Open Source de Gatling. Pour obtenir un comportement “similaire”, il vous faudra configurer vos injecteurs et agréger manuellement les résultats. A titre indicatif la démarche est disponible ici. Vous remarquerez que le mode opératoire est loin d’être trivial, la procédure étant beaucoup plus simple lorsqu’on s’appuie sur la version entreprise de Gatling (Frontline) : les injecteurs peuvent être aisément déployés sur AWS, GCP, Azure, … et les résultats seront automatiquement agrégés par Frontline.
Exploitation des résultats
Note : 4/5
En passant l’option -ro au lancement d’une simulation, un rapport sera généré à partir du fichier simulation.log (lui-même généré automatiquement durant l’exécution). Ce rapport est très complet, sans pour autant nous noyer sous une myriade d’informations. On y retrouve notamment des indicateurs sur le taux d’échec de la simulation, le nombre de VUs à un instant donné, les temps de réponses, et bien d’autres. Dans une large partie des cas, ce rapport est suffisant.
Néanmoins dans certaines situations, il est intéressant de pouvoir agréger différemment les résultats, les représenter autrement, ou les visualiser “en temps réel” durant la simulation. On pourrait opter pour un branchement sur un APM ou à minima sur une solution comme Grafana. Mais ce type de mise en oeuvre est-il possible avec Gatling ?
Nous avons vu qu’il existait des connecteurs permettant d’interfacer Gatling avec Prometheus, et ainsi exploiter les résultats dans Grafana. Une nouvelle fois la version Entreprise, Gatling Frontline, permet ce type de visualisation. Mais rassurez-vous il existe également une solution pour la version Open Source. Celle-ci consiste à exporter les données en sortie de simulation vers une base “timeseries” type InfluxDB ou Graphite (via son composant Carbon) et à “brancher” Grafana sur cette base de données. Pour cela, la configuration centralisée dans gatling.conf devra être modifiée et intégrer les paramètres du connecteur à utiliser (Graphite ou Influx). A titre d’exemple, l’intégration de Graphite pourrait se faire comme suit :
data {
writers = [graphite, console, file]
...
graphite {
host = "127.0.0.1"
port = 2003
}
}
Tarification
Note : 4/5
Comme évoqué précédemment , Gatling propose une version entreprise payante appelée Frontline. Celle-ci peut au choix être provisionnée automatiquement sur AWS ou Azure (offre “cloud”), ou être installée par vos soins sur votre infrastructure (offre “on-premise”). Cette dernière option se décline en plusieurs offres :

L’offre Cloud quant à elle vous laisse le choix entre deux Cloud Provider :
- AWS, qui semble être la plus flexible

- Azure

Sachez que quel que soit l’option retenue (Cloud ou On-premise), vous pourrez disposer d’une période d’essai gratuite (15 jours pour l’option On-premise, 5 jours pour l’offre Cloud avec AWS).
Une nouvelle fois, on regrettera que le passage à la version entreprise soit obligatoire pour disposer d’un cluster permettant d’exécuter nos tests en distribué.
Fonctionnalités utiles
Note : 4/5
Gatling propose clairement moins de features que JMeter, mais n’a tout de même pas à rougir puisque l’outil vous permettra de :
- réaliser des tests de performances sur diverses technologies / protocoles (HTTP/HTTPS, WebSocket, Rest ou SOAP API, JMS, JDBC, ou encore FTP).
- bénéficier d’un recorder graphique pour créer vos scénarios.
- utiliser un CLI pour rapidement lancer une exécution depuis votre console, ou votre CI.
- disposer de rapports clairs et synthétiques.
- mettre en place facilement une visualisation temps réel de vos exécutions, en interfaçant avec des solutions comme Grafana.
Moyenne : 3,83/5
K6, ajoutez une touche fruitée à vos tests

Support et communauté
Note : 3,5/5
Nouveau venu dans les tests de performances, K6 est un projet récent apportant un peu de fraîcheur dans un environnement principalement dominé par JMeter et Gatling. Créé en 2016, K6 n’est toujours pas en version 1 (la dernière version 0.27.1 datant de Juillet 2020). A ce jour, K6 rassemble 61 contributeurs, et a obtenu rapidement plus de 7 000 étoiles sur Github. Fondé sur les bases de Load Impact, K6 met à disposition une plateforme de test écrite en Go à la fois simple et flexible, permettant d’exécuter des tests en local mais également dans le Cloud. En raison du succès et de la croissance rapide de K6, les équipes de développement ont même décidé de renommer l’outil Load Impact (fer de lance de leur offre SaaS) en K6 Cloud. Sachez enfin que les scénarios sont écrits en JavaScript ES6.
Prise en main
Note : 3,5/5
K6 s’installe très facilement via votre gestionnaire de paquets préféré. Pour les utilisateurs Windows, un installer est disponible. Et pour les aficionados de Docker, une image est également proposée. Vous trouverez plus d’informations sur le sujet sur le site officiel.
Avec K6, l’écriture des tests se fait en JavaScript, une série de modules étant mise à disposition pour en faciliter la création (appel HTTP, simulation d’un temps d’attente, …). Ci-dessous un exemple très simple de scénario :
import http from 'k6/http';
import { sleep } from 'k6';
export default function() {
http.get('http://test.k6.io');
sleep(1);
}
Une fois le test écrit, l’exécution se fait via le CLI fournit par l’outil :
$ k6 run script.js
L’utilisation de K6 est donc triviale, en tout cas pour des cas simples. Mais qu’en est-il lorsqu’on souhaite réaliser des contrôles plus poussés ? Et bien cela ne se corse pas tellement : la documentation officielle est très bien faite, avec de nombreux exemples à l’appui, et la syntaxe est simple à appréhender. Ainsi la définition de “thresholds” (critères permettant d’évaluer le degré d’acceptation de la performance d’un système) se fait simplement en créant un objet. Cet objet associe des clés (les noms des métrics à prendre en compte, par exemple http_req_duration représentant la durée d’exécution d’une requête HTTP) avec des seuils à respecter (par exemple p(95)<500 qui, associé à http_req_duration, permet de préciser que 95% des requêtes doivent être complétées en moins de 500ms).
Ce qui pourrait se traduire dans nos scénarios par :
//...
export let options = {
thresholds: {
'failed requests': ['rate<0.1'], // threshold on a custom metric
'http_req_duration': ['p(95)<500'] // threshold on a standard metric
}
};
//...
La création de scénarios se limite cependant à du code JavaScript (du moins pour l’utilisation on premise), l’outil ne disposant de recorder nativement. On notera néanmoins qu’un outil extérieur permet de convertir les fichiers de type HAR en tests K6 (har-to-k6, qui s’installe via npm). A noter également que d’autres projets du même type vous aideront à convertir certaines sources de données en scénarios K6 (citons notamment jmeter-to-k6, postman-to-k6 ou encore OpenApi Generator). Autre manque par rapport à JMeter par exemple, k6 ne teste que des endpoints http (HTTP/2 et websocket sont de la partie), pas de Mqtt ou d’autres protocoles par exemple.
Industrialisation
Note : 3,5/5
K6 disposant d’une image Docker, son utilisation par votre outil de CI préféré s’en retrouve grandement simplifiée. Mais l’outil ne se limite pas à une utilisation on premise, et l’offre Cloud peut également être une option pour automatiser les tests de performance.
La version cloud vous proposera des intégrations facilitées pour bon nombre d’outils de CI du marché.

Bien que k6 permette une utilisation optimisée des ressources CPU (jusqu’à 40000 VUs selon la documentation officielle), l’exécution distribuée n’est pas triviale. En effet la mise en cluster des workers k6 reste faisable avec l’offre Cloud, mais dès lors que l’on tente l’expérience en local les choses se compliquent et il faudra très certainement consolider vos résultats en aval (les X process k6 exécutés sur les diverses machines du cluster ne se synchronisant pas).
Exploitation des résultats
Note : 3/5
Par défaut K6 affiche les résultats d’une exécution dans le terminal.
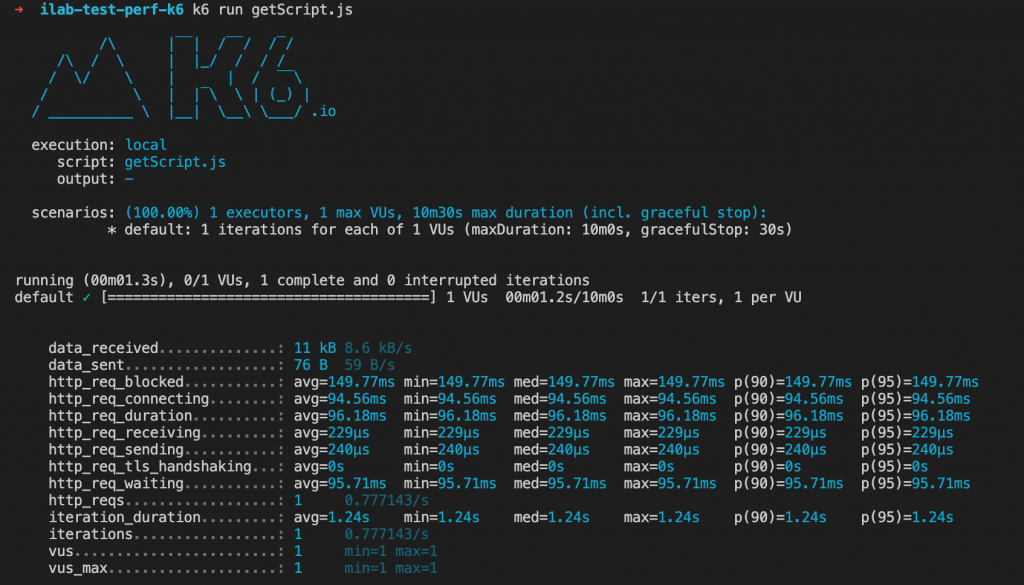
Seule l’offre Cloud permet d’obtenir des dashboards complets et facilement exploitables… du moins sans avoir à faire intervenir des outils tiers. Sachez que les données générées à l’issue d’une exécution de tests avec k6 peuvent tout à fait être exportées vers d’autres sorties via une série de connecteurs disponibles sur le site du projet. Ainsi il est possible de pousser vers ces cibles :
A titre d’exemple, vous pourrez tout à fait brancher un connecteur Kafka vers une base de données ou les indexer dans Elastic (via le format Json). Ces intégrations relèvent un peu la note, mais les résultats par défaut sont assez limités.
Tarification
Note : 4/5
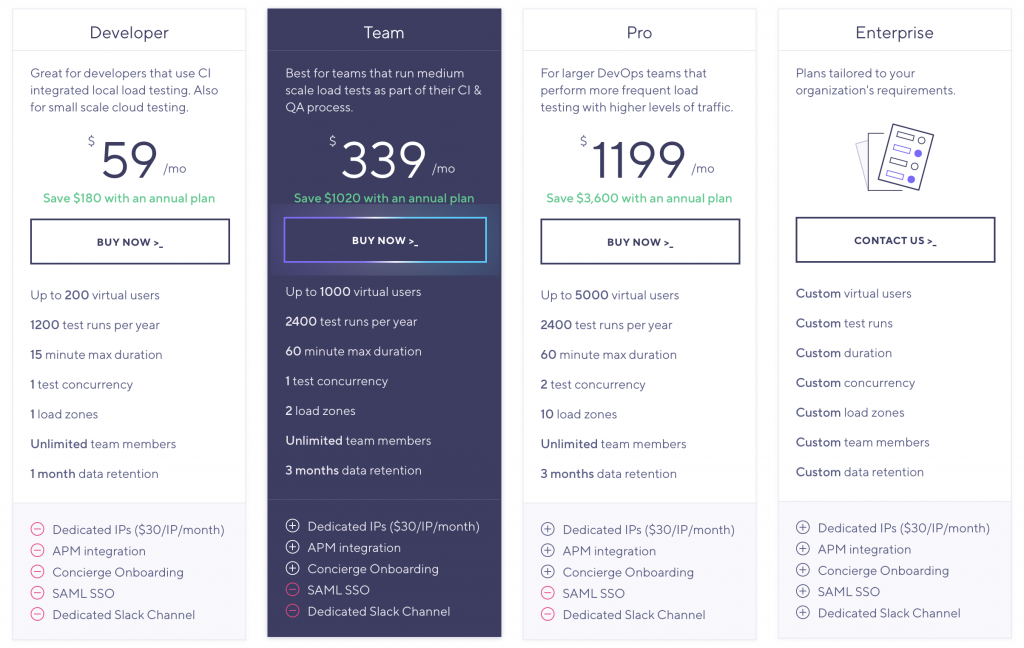
K6 est utilisable librement en “on premise”, cependant le site officiel incite fortement à utiliser l’offre Cloud, qui a pour principal avantage de faciliter l’exécution distribuée des tests. L’offre SaaS vous permettra aussi de :
- disposer d’une restitution visuelle sous forme de dashboards, là où la version on premise se limite à une restitution dans la console
- créer des espaces projets pour collaborer avec le reste de son équipe
- enregistrer un scénario avec l’extension browser, en somme moins de scripts et plus de “clics” 😉
- scaler jusqu’à 100 000 utilisateurs
- bénéficier de supports de la part des équipes de k6 Cloud
Ci-dessous le pricing de l’offre SaaS de k6 :
Fonctionnalités utiles
Note : 3,5/5
Globalement K6 propose des fonctionnalités similaires aux autres solutions de perf-testing. On notera néanmoins :
- une bonne optimisation des ressources permettant d’utiliser une grand nombre de VUs sur une seule machine
- Les intégrations externes de résultats
- L’utilisation de “checks” et de “thresholds” pour donner un cadre et des limites d’acceptabilité des tests.
- la variabilisation des données possible (via un fichier JSON par exemple)
Moyenne : 3,5/5
Pour voir plus de détails sur k6, lisez notre article.
Locust, véritable essaim pour tester vos applications
Support et communauté
Note : 4/5
Autre projet open source encore peu connu, Locust offre une approche assez similaire à celle de k6, mais avec quelques autres fonctionnalités très intéressantes. De la même manière que pour k6 ou Gatling, les tests sont à coder (en Python cette fois-ci). Cette solution est clairement “orientée développeur”. Sorti en première version en 2011 et actuellement en v1.2.3, Locust rassemble aujourd’hui plus de 150 contributeurs et détient 13 900 étoiles sur Github…preuve de l’engouement grandissant autour de cet outil !
Prise en main
Note : 3,5/5
Celle-ci est extrêmement simple (en tout cas pour les développeurs), l’installation et le setup de l’environnement pouvant se faire en une ligne de commande (sous condition d’avoir déjà Python 3 sur votre machine) :
$ pip3 install locust
La documentation est bien fournie, et offre bon nombre d’exemples. Comme dit plus haut, les scénarios sont écrits en Python et sa philosophie pourrait faire penser à celle de k6.
from locust import HttpUser, between, task
class WebsiteUser(HttpUser):
wait_time = between(5, 15)
def on_start(self):
self.client.post("/login", {
"username": "test_user",
"password": ""
})
@task
def index(self):
self.client.get("/")
self.client.get("https://d3uyj2gj5wa63n.cloudfront.net/static/assets.js")
@task
def about(self):
self.client.get("/about/")
La syntaxe est simple, l’écriture des scénarios en est d’autant plus rapide. Leur exécution est tout aussi simple : Locust dispose d’un CLI, permettant de lancer une simulation mais aussi de préciser le nombre d’utilisateurs virtuels, la fréquence d’augmentation des VUs, la durée de la simulation, … L’exemple suivant permet de lancer une simulation d’une heure et demie, avec une augmentation progressive du nombre de VUs (300 VUs supplémentaire toutes les 20 minutes).
$ locust -f --headless -u 1000 -r 100 --run-time 1h30m --step-load --step-users 300 --step-time 20m
Cependant la vraie force de Locust face aux autres (du moins pour la version on premise) est sans doute son interface web, permettant de configurer les exécutions de tests et notamment:
- le nombre d’utilisateurs à simuler
- le nombre d’utilisateurs par seconde
- le Host cible
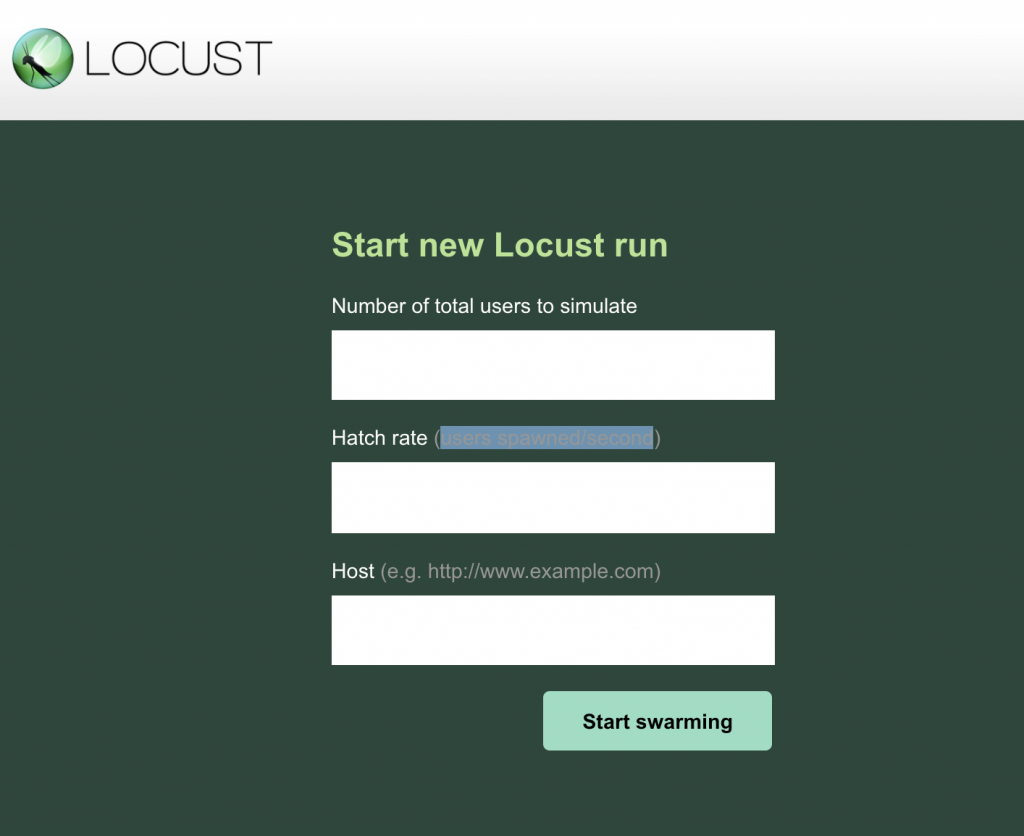
Une fois l’exécution terminée, les résultats sont consultables dans des dashboards affichés dans l’interface. Une véritable plus-value ! Nul besoin d’avoir recours à des outils extérieurs pour obtenir un rapport “human readable”. De plus, l’écriture des tests ne se limite pas au Python, et des portages vers d’autres langages existent (citons Locust4J pour Java et Kotlin, ou Boomer pour Golang).
On regrettera tout de même l’absence de recorder simplifiant la création de scénarios.
Industrialisation
Note : 3,5/5
Locust peut être exécuté de deux façons :
- Mode UI
- Mode headless (via la la commande locust –headless)
Et c’est justement ce second mode qu’il faudra utiliser au sein de votre CI pour lancer vos tests. Mais au-delà du CLI, Locust intègre un système de “hook” permettant d’intercepter des événements, de traiter les résultats d’une exécution, de les republier sur d’autres sources… via des scripts (qui devront être développés par vos soins).
Comme pour ses “concurrents”, Locust permet l’exécution distribuée de vos tests , le cluster pouvant être déployé sur GKE, EKS ou AKS (en fonction du cloud provider utilisé 😉). Dans sa forme la plus simple, la création d’un cluster peut se faire comme suit :
$ locust -f locust_file.py --master --host=http://localhost:3000 $ locust -f locust_file.py --slave --master-host=ip_server
En outre, on spécifie via l’option -f le fichier contenant notre scénario. L’option –master permet de créer le nœud master. Les slaves sont démarrés via l’option –slave, en spécifiant l’adresse du nœud master avec –master-host. Vous l’aurez constaté, la démarche est on ne peut plus triviale !
Exploitation des résultats
Note : 4/5
Locust permet d’exporter les résultats d’une simulation en CSV, mais on privilégiera sans doute l’interface Web de l’outil, qui fournit nombre de tableaux et de graphiques synthétisant les données.
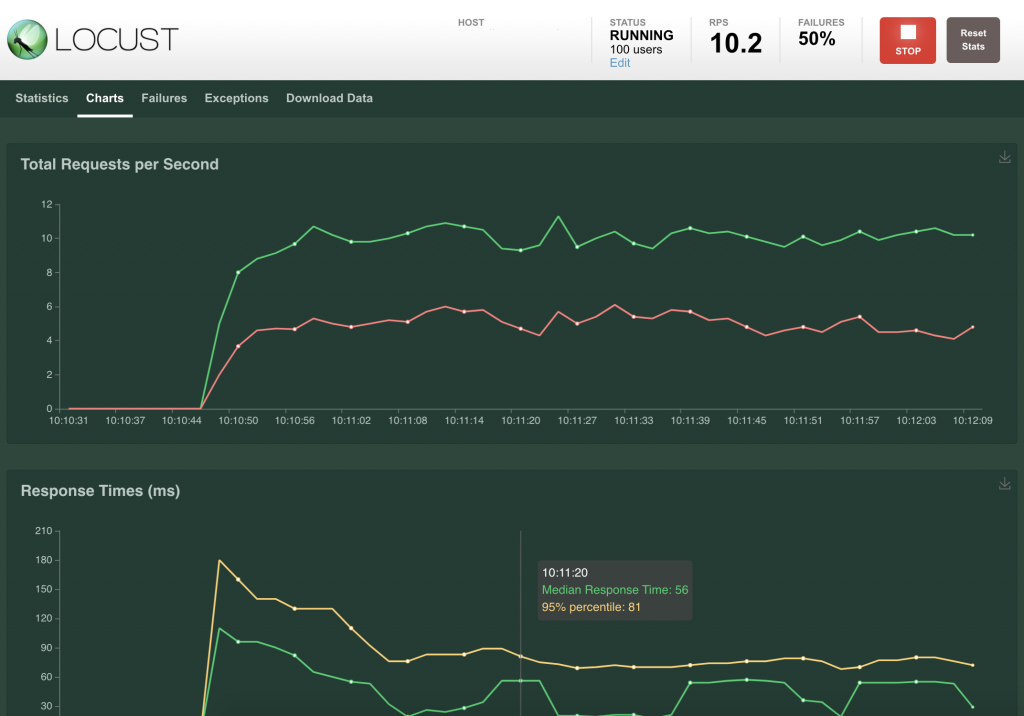
Mais l’utilisation de ces dashboards n’est pas la seule possibilité pour visualiser les résultats, ceux-ci pouvant être affichés dans Grafana : on optera alors pour un stockage en base de données timeseries, type Carbon (composant faisant partie de l’écosystème de Graphite), source qui sera alors branchée sur votre instance Grafana.
Tarification
Note : 3/5
Locust est Open Source et entièrement gratuit en version “on premise”. Cependant, et c’est là le talon d’Achille de l’outil, il n’y a pour l’instant aucune solution SaaS “officielle”. Un créneau à prendre ? On notera tout de même que Blazemeter propose une intégration de Locust (conférez-vous à la section “Tarification” de JMeter pour plus de détails).
Fonctionnalités utiles
Note : 3,5/5
Outre la possibilité de ré-exploiter du code python dans l’ensemble des scripts, Locust présente peu de fonctionnalités originales. On notera tout de même la présence de deux features intéressantes :
- L’authentification, pouvant être centraliser dans un fichier Python auth.py. Les scripts nécessitants une connexion (en outre l’ajout de bearer dans les headers des requêtes HTTP) pourront ensuite s’appuyer sur auth.py.
- De la même manière que pour k6, les customs greenlets permettent d’observer le taux d’échec et couper une simulation à tout moment.
Moyenne : 3,66/5
En définitive, y-a-t-il vraiment un vainqueur ?
Bien que JMeter tire toujours son épingle du jeu, les autres solutions du banc de tests sont au coude à coude. K6 et Locust, moins connus, talonnent Gatling en terme de simplicité d’utilisation, mais aussi de par leur facilité à s’interconnecter avec d’autres briques de votre SI. En outre, vous l’aurez compris, il n’y a pas de mauvaise solution, ni de solution idéale pour tous les cas de figure. Tout dépendra de votre besoin : si l’équipe en charge de développer les campagnes de tests de performances est réfractaire au code, privilégiez plutôt une solution qui met à disposition un recorder comme JMeter.
Si votre projet concerne un petit périmètre et qu’une exécution distribuée n’est pas nécessaire, Gatling voir k6 répondront d’ores et déjà à votre besoin. A contrario si vous souhaitez générer un nombre important de VUs et jouer régulièrement vos campagnes, il vous faudra sans doute opter pour une solution disposant d’une offre SaaS et d’une bonne intégration avec les solutions de CI/CD du marché. En ce sens, JMeter reste malgré son grand âge, un incontournable de par le nombre de features proposées (et l’offre SaaS de Blazemeter simplifiera grandement sa mise en place).
Mais au-delà des projets de référence que sont JMeter et Gatling, d’autres moins connus offrent également des aspects très intéressants : on retiendra Locust pour sa simplicité de prise en main et son interface graphique permettant de paramétrer rapidement vos simulations, et k6 dont la version Open Source pêche un peu sur la restitution / synthèse des résultats d’une exécution et la mise en cluster, mais se rattrape amplement avec son offre SaaS (chose que Locust ne propose pas vraiment, sauf via l’offre de BlazeMeter).
Liens utiles
- Sites officiels :
- JMeter – https://jmeter.apache.org/
- Gatling – https://gatling.io/
- K6 – https://k6.io/
- Locust – https://locust.io/
- Démarche de tests de performance – https://blog.octo.com/une-demarche-de-tests-de-performance/


1 Comment
Comments are closed.