
Dans l’équipe, lorsque nous nous sommes répartis les différentes solutions à éprouver, mon choix s’est tourné vers k6.
Je ne connaissais que de nom, mais leur homepage, le logo, le nom, les références… m’ont plu ; ce n’est pas anodin, l’informatique n’échappe pas aux règles de mise en valeur d’un produit. Et surtout la documentation ne m’a pas déçue, ni le reste d’ailleurs… mais commençons par le commencement : le setup et le premier run !
Cet article est un focus issu du dossier de benchmark d’outils de tests de performance disponible ici.
Tout commence dans le terminal
Le titre de ce chapitre est à la fois un oxymore, mais aussi une réalité : pour vos premiers pas en local (sans la version cloud que nous verrons plus tard), vous n’aurez pas d’application lourde à la JMeter par exemple, pas d’interface graphique, mais à l’instar d’un Apache Benchmark, un outil en ligne de commande (en plus du framework de coding des tests).
Au passage, si vous ne l’utilisez pas, Apache Benchmark peut en quelques commandes vous aidez à exécuter localement et rapidement, via une URL, une petite charge de tests, ce qui m’a souvent bien dépanné.
Revenons à k6.
Ecrit en Go (voir repo Github), il s’installe facilement sur l’OS de votre choix et bien sûr, c’est un incontournable, aussi via une image Docker. Tout est expliqué ici et j’ai personnellement utilisé brew pour l’installer sur ma machine. Vous aurez en plus de la documentation en ligne et toute l’aide nécessaire dans votre terminal, bien entendu.
Vous allez me dire : la vie, ce n’est pas son poste de dev ; et vous n’auriez pas tort ; même si dans la suite de l’article j’utilise mon terminal pour lancer les tests, sachez que pour la partie industrialisation vous pourrez facilement l’intégrer à votre CI favorite (rappelez-vous c’est un binaire simple à installer ou une image Docker).

Pour notre benchmark, nous avions utilisé l’API Petclinic de Spring, histoire d’avoir une base commune, le même scénario et les mêmes données.
Mon premier test est basique et permet d’illustrer le minimum requis pour votre premier script (en Javascript donc) :
import http from 'k6/http';
import { sleep } from 'k6';
export default function() {
http.get('http://my_host:9966/petclinic/api/pets');
sleep(1);
}
Au minimum on importe le module http, pour réaliser les différents appels (avec les verbes usuels) et les autres fonctionnalités, comme ici “sleep” pour réaliser une pause (si on fait des enchaînements).
Puis on exporte une “function” par défaut (libre à vous d’en créer d’autres bien sûr si vous avez du code à exécuter en amont/aval des requêtes. Il y a d’ailleurs, tout de prévu pour vous aider dans le cycle de vie du test. Pour le lancement, on utilise le binaire k6 et la commande suivante :
k6 run --vus 10 --duration 30s getPetScript.js
Vous pourrez aussi effectuer d’autres types de requête. Je vous renvoie vers la documentation avec des exemples concrets. Je me suis concentré vers des appels d’API HTTP/1.1.
On peut exporter les différents paramètres de son test directement dans le code du script, ou en ligne de commande pour modifier les exécutions.
Ici on passe les paramètres :
vus: les “virtuals users”, ils seront au nombre de 10duration: mon test durera 30 secondes, 30 secondes durant lesquelles les “virtuals users” feront autant d’exécutions que possible.
Le résultat dans la console, se présente sous cette forme :
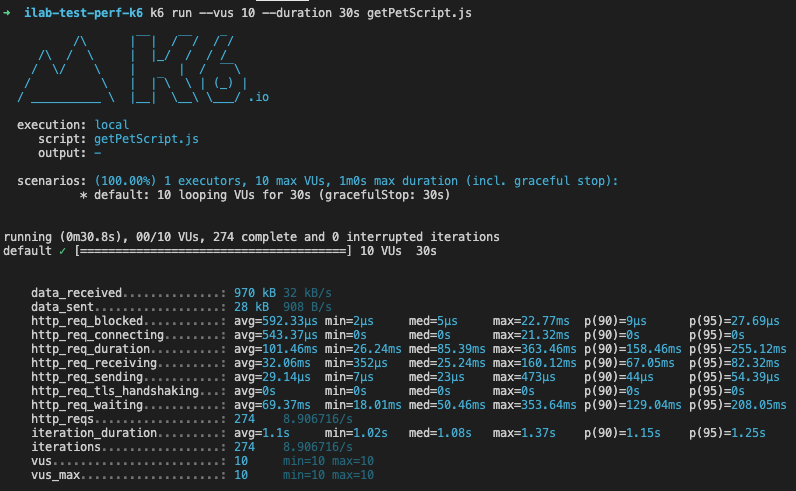
Mon test s’est déroulé correctement : je n’ai pas d’assert particuliers, hormis celui de base qui attend la réponse Http de mon Get.
Nous pouvons visualiser les métriques de base ordonnées par : les résultats à l’extrême (min et max), la moyenne, la médiane, les percentiles…
Pour résumer, mes 10 “virtual users” ont pendant 30 secondes généré 274 requêtes, ont reçu 970 kb de données pour un temps de réponse moyen de 101.46 ms. Vous avez déjà, pour un test one shot, des éléments d’analyse simples et complets.
Vous pourrez dans le code expliciter d’autres métriques et ajouter celles qui vous manquent et pour cela k6 vous propose 4 types de mesure:
Un bon test, c’est avant tout un bon scénario
Vos utilisateurs vont appeler votre application de différentes manières, en enchainant les requêtes, les données…
Alors pour vous rapprochez d’une utilisation “normale”, mais qui sera démultipliée en nombre, il vous faut écrire un bon scénario.
Pour cela, plusieurs options s’offrent à vous.
Si vous souscrivez à l’offre cloud, vous bénéficierez d’une extension de browser pouvant enregistrer vos actions. Vous pouvez aussi convertir d’autres formats vers un test k6, comme illustré ci-dessous.

Pour ma part, j’ai testé la conversion d’une archive de type HAR. Par exemple, j’ai utilisé l’UI de la Petclinic pour enregistrer quelques requêtes via Chrome.
N’hésitez-pas à visualiser votre .har ici: https://toolbox.googleapps.com/apps/har_analyzer/
Ensuite, il vous faut installer le module de conversion, et lancer cette conversion en nommant le test final souhaité.
npm install -g har-to-k6 har-to-k6 pet-clinic.har -o petClinicScenario1FromHAR.js
Vous pourrez donc ensuite lancer votre test, comme n’importe quel script. Vous verrez dans le code du script js généré que c’est beaucoup plus verbeux que de simples requêtes d’API, puisqu’il enregistre tout (comme les headers de request par exemple). Libre à vous de modifier le code obtenu pour variabiliser, ajouter des étapes, des assertions… La partie scénario est très complète d’un point de vue exécution, un très bon point, et vous pouvez allouer des “virtual users”, des durées… à certaines parties du scénario : https://k6.io/docs/using-k6/scenarios
Check your body
Pour la suite, j’ai utilisé un “scénario” maison qui enchaîne des créations/modifications… en prenant soin de récupérer des informations entre chaque appel et réaliser à minima des “checks” sur les codes de retour.
Exemple ici avec un extrait de la création d’un propriétaire, assertion sur le retour et récupération du body de réponse en Json pour vérifier qu’il n’y a pas de transformation dans la suite (+ le timestamp en suffixe) :
export default function () {
let response = http.get(prefixUrlApi + 'pets');
//sleep();
let bodyJson = JSON.parse(response.body);
check(response, {
"response code was 200": (response) => response.status === 200,
});
let globalHeaderParams = {
headers: {
'Content-Type': 'application/json',
},
};
let suffixeTimestamp = Date.now();
// POST an owner
let payloadOwner = JSON.stringify({
address: 'adresse fake',
city: 'Lille',
firstName: 'firstname' + suffixeTimestamp,
lastName: 'lastname' + suffixeTimestamp,
telephone: 1234567890
});
response = http.post(prefixUrlApi + "owners", payloadOwner, globalParams);
check(response, {
"response code was 201": (response) => response.status === 201,
});
bodyJson = JSON.parse(response.body);
let idOwner = bodyJson.id;
let firstNameOwner = bodyJson.firstName;
let lastNameOwner = bodyJson.lastName;
let addressOwner = bodyJson.address;
let cityOwner = bodyJson.city;
let telephoneOwner = bodyJson.telephone;
console.log("create owner with id " + idOwner);
...
Dans cet exemple, nous avons un appel Get à la liste des animaux, avec une vérification sur le code de retour, puis une suite de créations/mises à jour (que je n’ai pas recopié entièrement).
Vous pouvez ainsi, récupérer toutes les informations de la réponse et vérifier le contenu que vous souhaitez. Le titre que vous donnez à votre check permet à k6 de les grouper (si vous l’utilisez plusieurs fois durant le test) et de compter le nombre de succès/échecs.
check(response, {
"response code was 200": (response) => response.status === 200,
});
check(response, {
"response code was 201": (response) => response.status === 201,
"Good pet get": (response) => JSON.parse(response.body).id === idPet,
});
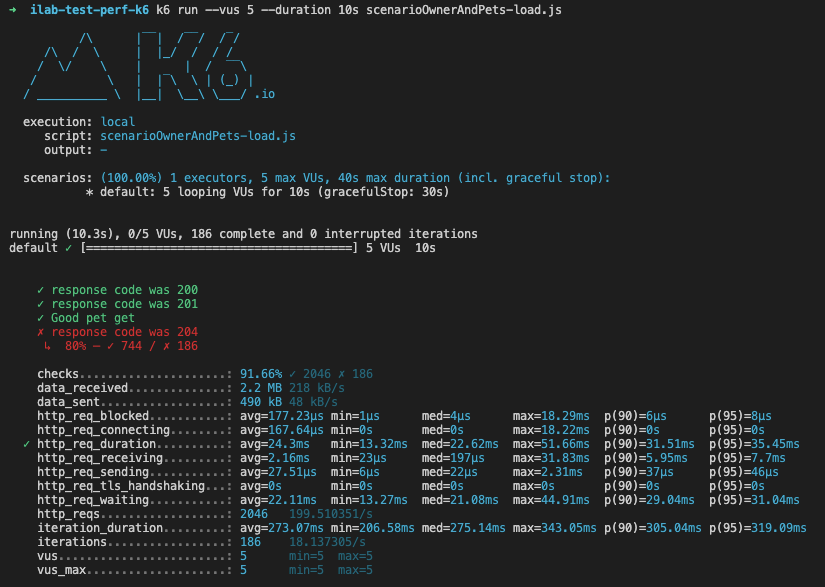
En vert, les 3 types de “check” qui ont fonctionné et en rouge certains qui ont échoué (avec le ratio d’erreur, j’a volontairement mis une erreur dans la comparaison pour illustrer le résultat).
On charge la mule
Les exécutions réalisées jusque là s’apparentent à des “smoke tests” comme le décrit k6 dans sa documentation.

Pour réaliser des tests plus conséquents, il va falloir augmenter le nombre d’utilisateurs virtuels et enchaîner des phases de “ramp up” puis des plateaux de charges constantes, pour finir par réduire la charge. Ces différentes phases vous permettront d’analyser le comportement de votre application ou plateforme complète. Ci-dessous un exemple de phase avec durée et nombre de virtual users pour obtenir un stress test.
Les spike tests sont quand à eux des tests qui surchargent directement l’API et ne laissent pas de montée progressive des requêtes.
Illustration avec un load test dont les options sont exportées comme ceci :
export let options = {
stages: [
{ duration: '1m', target: 50 }, // simulate ramp-up of traffic from 1 to 50 users over 1 minute.
{ duration: '3m', target: 50 }, // stay at 50 users for 3 minutes
{ duration: '1m', target: 0 }, // ramp-down to 0 users
],
thresholds: {
http_req_duration: ['p(99)<1500'], // 99% of requests must complete below 1.5s
'logged in successfully': ['p(99)<1500'], // 99% of requests must complete below 1.5s
},
};
En commentaires, vous remarquerez que nous avons trois étapes : une montée en puissance, un plateau de 50 “virtual users”, puis une descente jusqu’à zéro progressivement. Et nous souhaitons toujours que la quasi totalité des requêtes soit en dessous de 1500ms. Ceci est rendu possible grâce à la notions de “thresholds“.
Ces seuils vous permettent de configurer par exemple un nombre de requêtes qui doit forcément être inférieur à un temps de réponse donné, un taux d’échec de requête… On peut diviser une même métrique en plusieurs seuils ou les associer à des groupes de requêtes spécifiques dans le test.
Puis après le load test, on configure un stress test plus conséquent, notez en commentaires les différents plateaux.
export let options = {
stages: [
{ duration: '1m', target: 100 }, // below normal load
{ duration: '3m', target: 100 },
{ duration: '1m', target: 200 }, // normal load
{ duration: '3m', target: 200 },
{ duration: '1m', target: 300 }, // around the breaking point
{ duration: '3m', target: 300 },
{ duration: '1m', target: 400 }, // beyond the breaking point
{ duration: '3m', target: 400 },
{ duration: '1m', target: 0 }, // scale down. Recovery stage.
],
};
Durant l’exécution, c’était à prévoir, l’API a souffert, certaines requêtes ont échoué et le taux de check en a pâti.
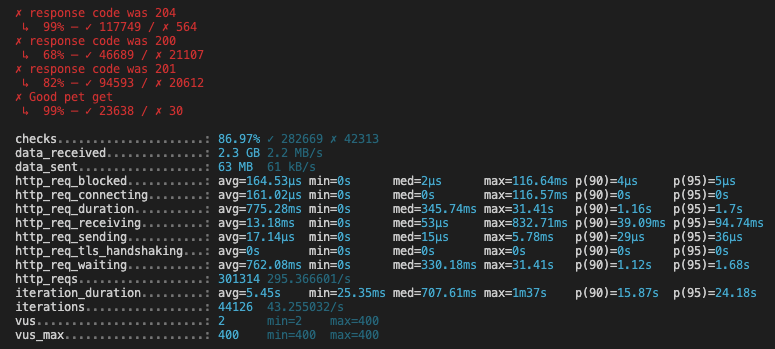
On peut voir au démarrage que k6 prépare le nombre de “virtual users” à créer et nous donne la durée estimée du test.
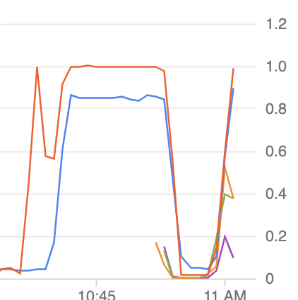
Durant le test, la première montée en charge à suffit à faire monter le processeur de la machine à 100% (en rouge), il n’est redescendu que lors de la phase de scale down. Ce n’est pas très grave, ni notre application, ni la machine n’ont été optimisées, les valeurs nous permettent seulement de visualiser les différentes étapes du test.
Pour ce test, je n’avais pas besoin de simuler énormément d’utilisateurs, mais pour connaître d’autres solutions comme JMeter et Gatling et leur clusterisation, je me suis mis à chercher la section “clustering” dans la documentation… Sans résultat.
En effet, k6 met en avant la capacité de sa solution à utiliser de manière optimale les ressources CPU et peut générer jusqu’à 30-40 000 utilisateurs virtuels et donc encore plus de requêtes sur des machines “standards”.
Des recommandations en terme de configuration de machines (process, memoire et réseau) sont disponibles ici :: https://k6.io/docs/testing-guides/running-large-tests . Si toutefois, les tests sur plusieurs machines sont nécessaires, il faudra consolider en aval les résultats, les process k6 ne se synchroniseront pas.
Dessines moi un graphique
Dans la version de base, il n’y a pas d’autres visualisations que la console. Seulement, on aime tous les graphiques et une courbe vaut mieux que 1000 métriques dans un terminal. Pour cela, k6 a plusieurs solutions, tout d’abord les exports et intégrations et la version SaaS. Voici la liste des cibles d’export de vos données et il y a de quoi faire :
- Amazon CloudWatch
- Apache Kafka vous pourrez y attacher des traitements qui surveilleront les exécutions au fil de l’eau (comme de l’alerting)
- Cloud
- CSV
- DataDog
- InfluxDB – Grafana
- JSON
- NewRelic
- StatsD
Si vous possédez une de ces stacks au sein de votre SI, vous n’aurez pas de mal à exporter vos données et avec des formats bruts comme le csv ou Json on peut aussi imaginer un phase de transformation/loading dans une autre cible (Elastic par exemple).
Je me suis créé un compte cloud pour pouvoir faire le tour de la solution et je ne suis pas déçu non plus. Sur le portail, vous récupérerez vos identifiants de projet et d’API pour pouvoir par exemple lancer une exécution locale et intégrer les résultats dans le cloud (les exécutions cloud chez k6 sont possibles aussi dans les offres).
export let options = {
ext: {
loadimpact: {
projectID: PROJECT_ID,
// Test runs with the same name groups test runs together
name: "YOUR TEST NAME"
}
}
}
Puis lancez les commandes suivantes :
k6 login cloud -t TOKEN k6 run -o cloud YOUR_SCRIPT.js
Les résultats sont disponibles ensuite dans la section de votre projet, illustration ici pendant l’exécution du test (avec quelques secondes de latence entre le lancement et l’affichage dans le navigateur) :
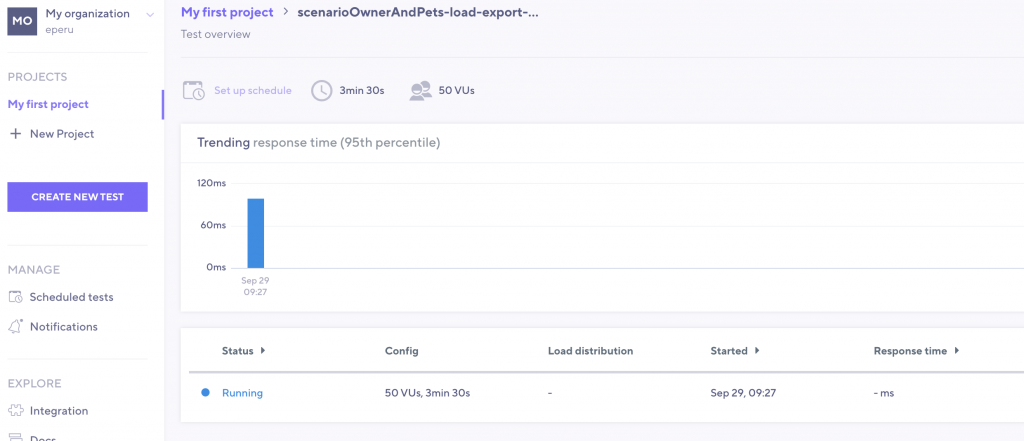
Au clic sur le détail, à la fin de l’exécution dans mon cas (il est là le joli graphique !) :
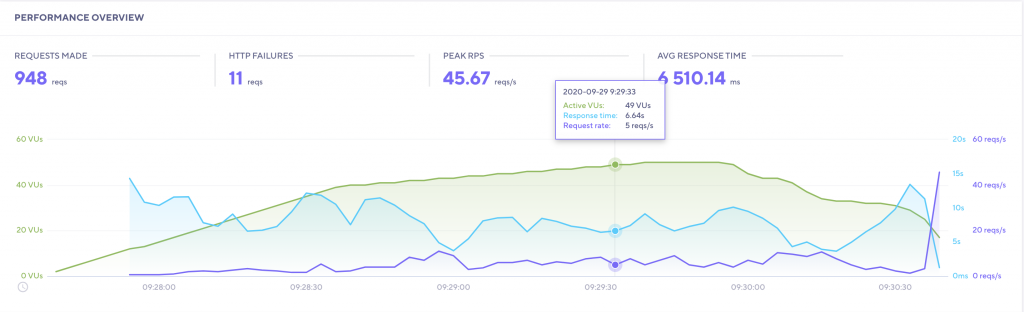
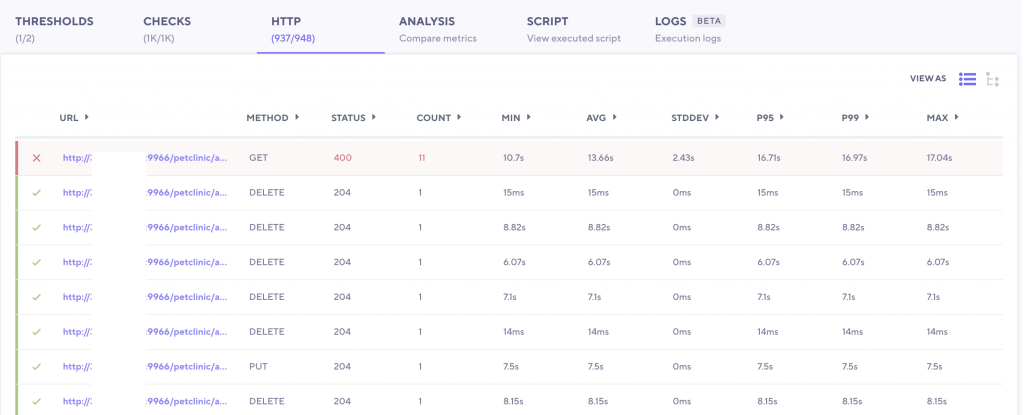
Et le détail des requêtes est disponible pour étudier les échecs ou les temps de réponses anormaux :
Ce n’est pas la seule fonctionnalité de l’offre SaaS, elle permet en effet de :
- disposer d’une restitution visuelle sous forme de dashboards comme vu précédemment, là où la version on premise se limite à une restitution dans la console
- créer des espaces projets pour collaborer avec son équipe
- d’historiser les exécutions et ainsi les comparer dans le temps
- enregistrer un scénario avec l’extension browser, en somme moins de scripts et plus de “clics” 😉
- scaler jusqu’à 100 000 utilisateurs
- bénéficier de supports de la part des équipes de k6
Et comme tout a un prix, je vous laisse découvrir celui de k6, qui a l’échelle d’une équipe, d’une entreprise est raisonnable, à condition d’utiliser au mieux la plateforme et d’être dans une démarche de performance.
On finit sur une note sucrée
L’analogie avec le fruit était facile, mais en bon français, je ne peux m’empêcher de prononcer “kassisse” pour parler de la solution, alors que ça n’a rien à voir, son identité repose sur un aligator (le créateur de la solution en avait d’ailleurs “adopter” deux). Pour autant, la solution ne m’a effectivement pas laissé un goût amer. Je ne suis pas le seul : depuis plusieurs années la communauté sur Github grandit et les usecases clients sont nombreux et assez prestigieux. Le code javascript nécessaire pour rapidement écrire des tests pertinents est assez simple, les exécutions rapides, la documentation complète, il y a beaucoup de possibilités, de customisation, de modularité, d’intégrations… (je suis très loin de vous avoir tout détailler) et c’est un outil que j’ai bien envie d’utiliser pour mes prochains projets, et vous ?

1 Comment
Comments are closed.