
Dans le premier article nous vous avons présenté OpenFaas, projet opensource permettant de construire des fonctions serverless. Nous avons vu comment assembler un cluster de Raspberry PI, installer Docker Swarm, et enfin déployer Openfaas.
Dans cet article nous irons plus loin que le déploiement des fonctions fournies par défaut avec le projet. Nous aborderons les rudiments du développement de fonctions et de l’utilisation de faas-cli dans la première partie de l’article. Dans la seconde partie, les différents concepts seront illustrés par un exemple didactique : nous construirons une application complète permettant de rechercher des films dans une collection de DVD, l’occasion pour nous de coupler Openfaas, GraphQL et MongoDB.
Bref rappel sur le fonctionnement interne d’OpenFaas
OpenFaas peut être vu comme un « framework » pour Docker, permettant de lancer des fonctions serverless. Cette solution peut aisément être déployée au sein d’un cluster Kubernetes ou Swarm (ceci était d’ailleurs l’objet de mon premier article).
Les fonctions peuvent être écrites dans des langages différents comme Javascript, Python ou Java. Elles seront ensuite packagées dans des images Docker lors du build. Ce sont ces images qu’OpenFaas utilisera pour démarrer nos fonctions.
PREREQUIS
Un cluster (Raspberry ou VMs) avec OpenFaaS installé
MongoDB 4.0.6
Python 3
Partie 1 : prise en main
L’interface d’OpenFaas
Openfaas dispose d’une interface graphique minimaliste et très simple à utiliser, accessible par défaut sur le port 8080. La première page affichée permet de déployer facilement de nouvelles fonctions via un bouton Deploy New Function, tandis que le menu de gauche nous donne un aperçu des fonctions disponibles.
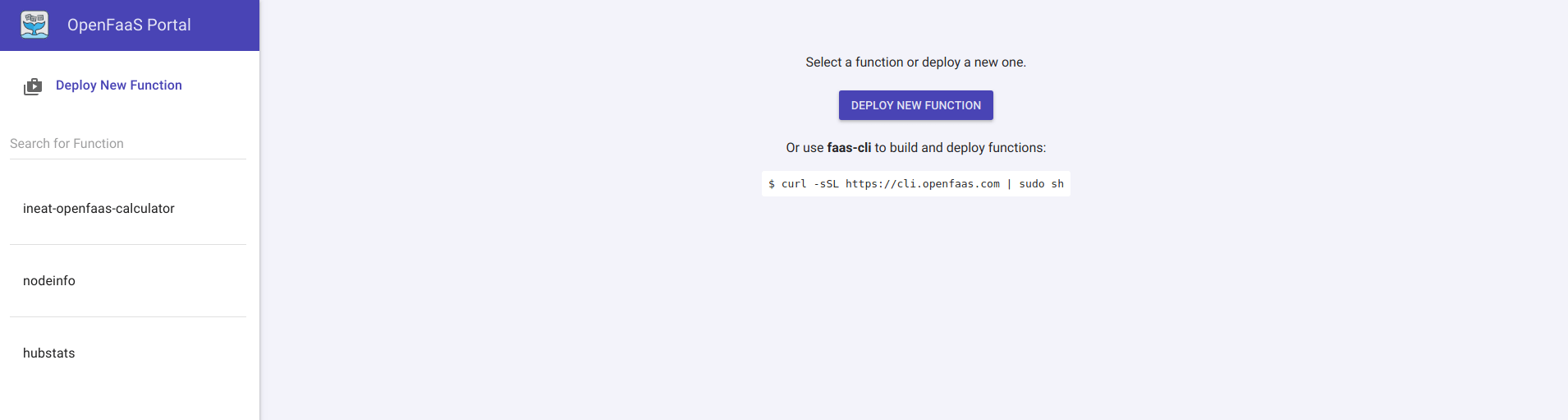
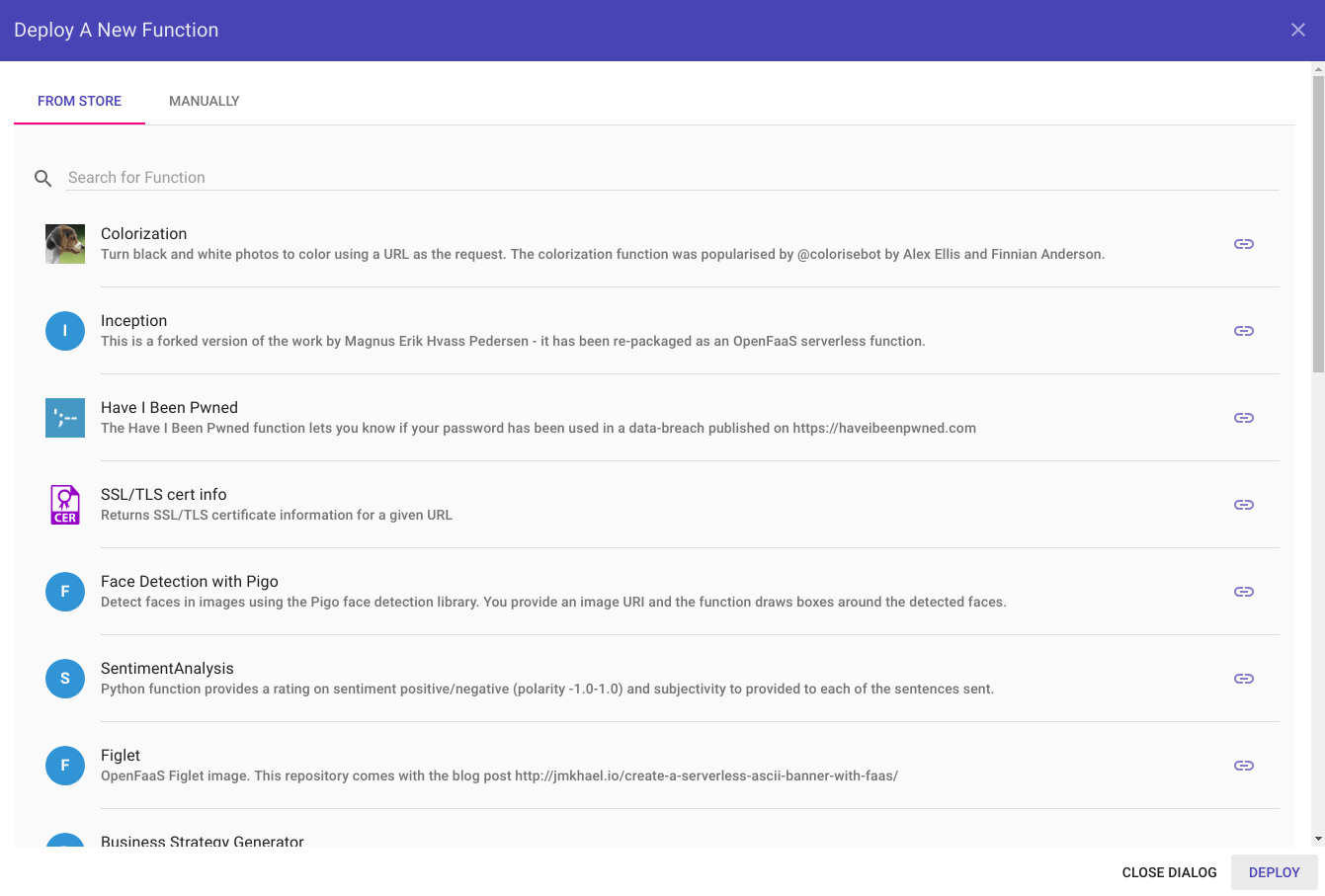
En cliquant sur le bouton Deploy New Function, une liste de fonctions par défaut nous est proposé dans une popup. Un second onglet nous permet de déployer manuellement une fonction (les paramètres obligatoires dans ce cas de figure étant le nom de l’image Docker à utiliser et la fonction à invoquer).
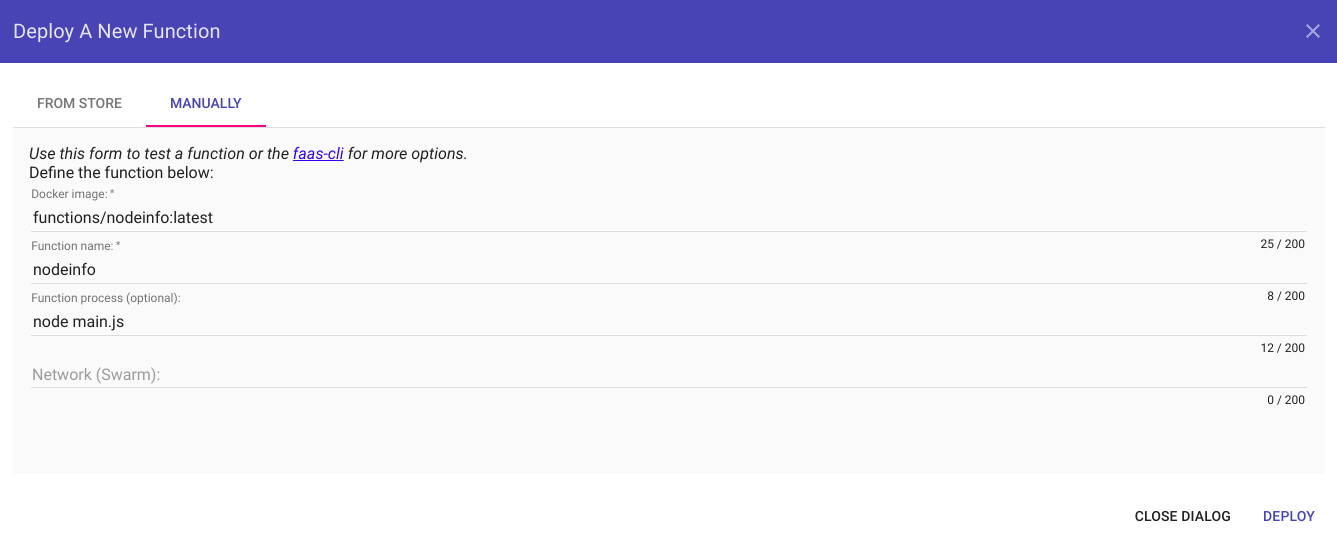
Nous aurons l’occasion de revenir sur l’interface d’OpenFaas dans la suite de cet article.
faas-cli, ou comment manager mes fonctions en ligne de commande
faas-cli est le CLI d’OpenFaas : l’interface en ligne de commande nous permettant de dialoguer avec OpenFaas … mais pas uniquement 😉
En effet, outre le déploiement de nouvelles fonctions, il peut être utilisé pour en créer de nouvelles (comprenez ici l’initialisation d’un squelette de fonction avec la structure de répertoires adéquate). faas-cli est également utile pour construire les images embarquant les fonctions et pour les pousser sur une registry docker.
Ci-dessous un listing des options les plus utilisées :
- faas-cli new – création d’une nouvelle fonction
- faas-cli build – construction d’une image docker à partir d’une fonction
- faas-cli push – mise à disposition d’une fonction packagée sur une registry
- faas-cli deploy – déploiement de fonctions au sein d’une plateforme OpenFaaS
- faas-cli remove – suppression de fonctions au sein d’une plateforme OpenFaaS
L’installation de faas-cli est détaillée dans l’article précédent. Pour rappel la procédure est la suivante :
curl -sSL https://cli.openfaas.com | sh sudo cp faas-cli /usr/local/bin/faas-cli sudo ln -sf /usr/local/bin/faas-cli /usr/local/bin/faas
Structure d’une fonction et premier exemple
Je vous propose de créer une première fonction très simple étape par étape. Cette fonction sera écrite en Python et permettra simplement de renvoyer la somme de deux nombres passés en paramètre (les sources de l’exemple sont disponibles ici).
Etape 1 : génération du squelette de fonction
Nous utiliserons pour cela l’option new de faas-cli :
faas-cli new ineat-openfaas-calculator --lang python3-armhf
Le premier argument correspond au nom de la fonction.
–lang nous permet de préciser le template à utiliser pour créer notre fonction. En effet faas-cli s’appuie sur des templates de fonctions prédéfinis, qui permettent de générer à la demande un squelette de fonction pour tel ou tel langage.
Dans le cas présent, nous optons pour python3-armhf.
Nous choisirons python3-armhf (plutôt que python3) puisque la fonction sera déployée sur un cluster de raspberry (l’image docker doit donc être construite de façon à pouvoir tourner sur une architecture ARM).
Une fois l’exécution terminée nous obtenons la structure de projet suivante :
– ineat-openfaas-calculator
|- handler.py
|- __init__.py
|- requirements.txt
– ineat-openfaas-calculator.yml
Etape 2 : écriture du code
Trois fichiers ont donc été générés. Les personnes ayant déjà eu l’occasion de créer des applications avec Python comprendront vite que requirements.txt permet de manager nos dépendances.
handler.py contient quant à lui le code Python de notre fonction. Nous allons modifier le code généré comme suit :
import json
def handle(req):
args_parse = json.loads(req)
result = args_parse["operande1"] + args_parse["operande2"]
return "Result : " + str(result)
Rien de bien complexe ici, il s’agit simplement de parser le JSON passé en argument (par le biais du paramètre req), puis d’additionner operande1 et operande2. La fonction se termine simplement en renvoyant une chaîne de caractères avec le résultat. Il y a donc très peu de nouveautés en comparaison à une fonction Python “classique”.
Etape 3 : build de l’image et premier déploiement
Le fichier Yaml ineat-openfaas-calculator.yml contient la configuration relative au build (partie functions) et déploiement (partie provider).
provider:
name: faas
gateway: http://127.0.0.1:8080
functions:
ineat-openfaas-calculator:
lang: python3-armhf
handler: ./ineat-openfaas-calculator
image: ineat-openfaas-calculator:latest
Dans le cas présent, nous développons et déployons nos fonctions directement sur un cluster de Raspberry. Il faut donc spécifier l’IP de notre nœud Master comme gateway (en local, ce sera 127.0.0.1 ;)).
La partie functions de ce fichier contient la définition de chacune de nos fonctions (en effet un projet pourrait contenir plusieurs fonctions). On retrouve ainsi le template utilisé (ici lang porte comme valeur python3-armhf puisque notre fonction est en Python), le nom de l’image docker qui sera générée durant le build et l’endroit où se trouve le handler.
Pour packager notre fonction nous exécutons cette commande :
faas-cli build -f ineat-openfaas-calculator.yml
L’option -f est employée pour préciser le fichier de build / déploiement à utiliser.
A ce stade, il ne reste que deux lignes de commande à taper avant de pouvoir utiliser notre fonction. La première nous permet de nous authentifier auprès d’OpenFaas et la seconde de déployer la fonction.
cat ~/faas_pass.txt | faas-cli login -g http://127.0.0.1:8080 -u admin --password-stdin faas-cli deploy -f ineat-openfaas-calculator.yml
Pour nous authentifier, nous aurions pu passer directement le mot de passe dans la ligne de commande via l’option –password. Cependant, externaliser cette donnée dans un fichier et exploiter son contenu en utilisant l’option –password-stdin est plus pratique et sécurisé. De plus, dans le cadre d’une utilisation en production, il serait judicieux de privilégier HTTPS.
Etape 4 : test de la fonction
Il ne reste plus qu’a nous rendre sur l’interface graphique d’Openfaas pour constater que notre fonction a bien été déployée et pour réaliser notre test. L’ensemble des fonctions déployées est visible dans le menu de gauche, en cliquant sur ineat-openfaas-calculator, nous accédons à l’écran nous permettant d’invoquer notre fonction.
Il suffit alors d’alimenter le champ Request body avec les opérandes qui seront utilisées pour le calcul (ces paramètres sont passés ici en JSON). Cliquez sur INVOKE et admirer le résultat :
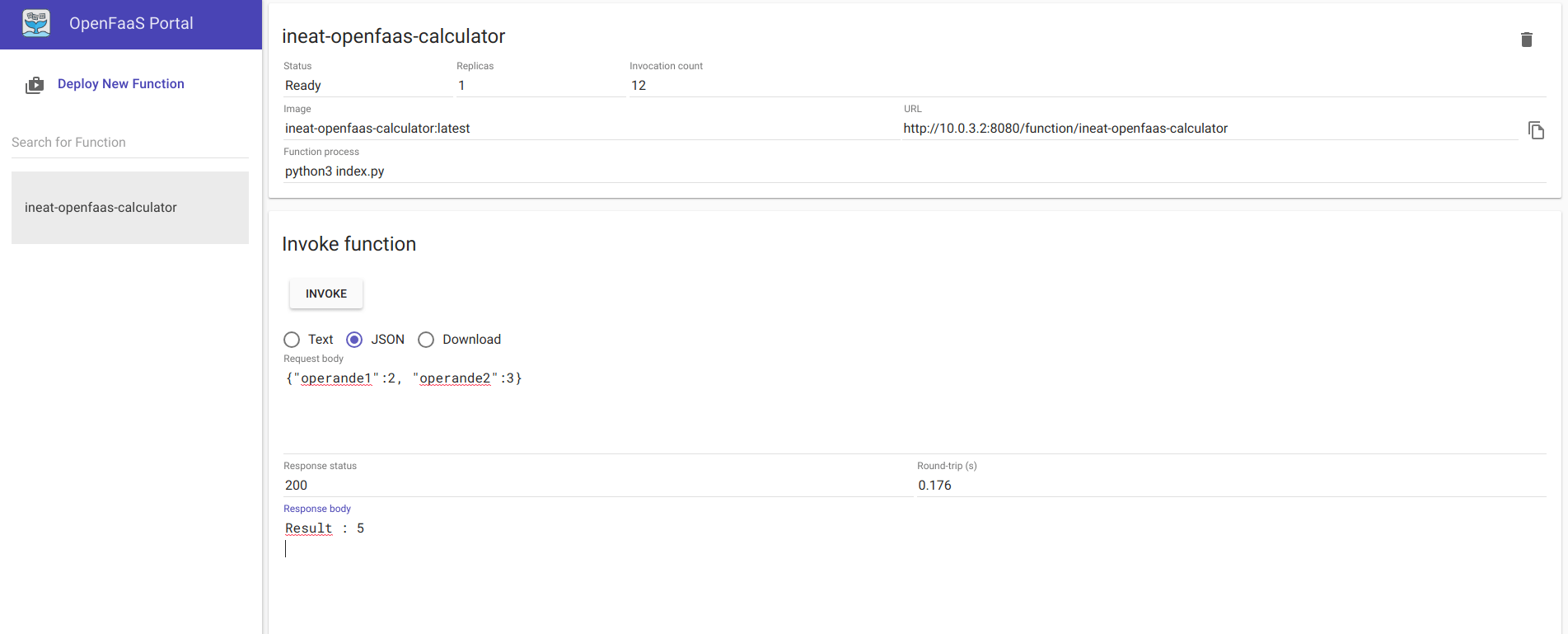
Et voilà, vous avez déployé votre première fonction entièrement codée par vos soins ! Nous avons ici mis en application un cas d’école, en créant une fonction très simple et en la déployant directement de notre machine de développement sur le cluster. Cependant cela se passe rarement de cette façon en “production”, les images sont généralement plus complexes et interagissent avec les autres briques composant le SI. Nous allons voir à présent un cas un peu plus réaliste.
Partie 2 : une application complète
Dans cette dernière partie, je vous propose une mise en pratique concrète. L’objectif sera de créer une fonction permettant de rechercher des films dans une collection de DVD.
La recherche sera assurée par GraphQL.
GraphQL est un langage de requête pour APIs développé par Facebook. Il permet au client de préciser la structure de données dans la requête, structure qui sera utilisée par le serveur pour organiser les données qui composeront la réponse.
La persistance des données sera ici assurée par MongoDB.
Architecture de l’application
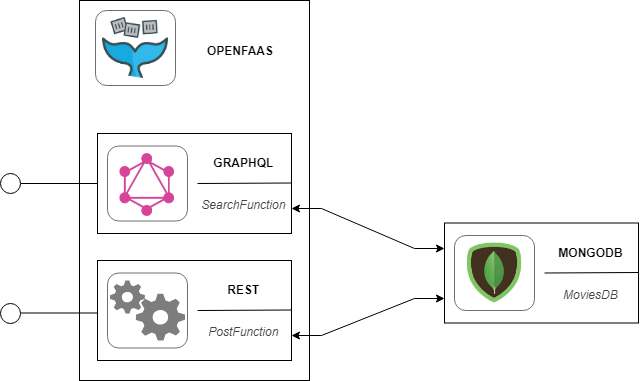
- la première permettra d’ajouter du contenu à notre base MongoDB. Dans notre use case, la fonction ajoutera donc un nouveau DVD.
- la seconde sera un peu plus complexe car elle fera intervenir GraphQL et aura pour rôle de rechercher des DVD selon différents critères (titre, réalisateur, …).
Mise en place de la base MongoDB
MongoDB est un système de gestion de base de données NoSQL orienté documents. Le but n’est pas ici de refaire une présentation complète de cette solution, mais sachez qu’avec MongoDB nous manipulons des collections de documents (une collection étant l’équivalent d’une table pour une base de données relationnelles). La principale différence ici est que contrairement aux systèmes de gestion de base de données classiques, il n’y a pas de schéma décrivant la structure d’une collection : les entrées des collections sont des documents JSON pouvant porter des informations très différentes d’un document à un autre (à nous de garder l’ensemble cohérent).
Nous ne décrirons pas ici la procédure d’installation de MongoDB. Une documentation détaillée existe déjà sur le site officiel.
Je vous déconseille d’installer directement MongoDB sur le cluster de Raspberry, privilégiez une installation sur une autre machine du réseau ou mieux sur une plateforme Cloud.
Pour notre petit projet, nous aurons besoin d’une base de données afin de persister notre collection de films. Celle-ci sera très simple et ne contiendra qu’une seule collection movies. Chaque film portera les informations suivantes :
- title -> le titre du film.
- actors -> la liste des acteurs, avec leurs noms et prénoms.
- director -> le réalisateur, avec son nom et prénom.
- type -> horreur, SF, …
- year -> l’année de sortie du film.
La création d’une telle base se déroule en 3 étapes.
1 – Après avoir installé MongoDB, on démarre le service et on ouvre l’invit de commande :
$ sudo service mongod start $ mongo
2 – Nous créons ensuite la base de données moviesDB via la commande suivante :
> use moviesDB
3 – Et enfin nous ajoutons une nouvelle collection et nous l’alimentons en données :
> db.movies.insertOne({title:"Dark City",actors:[{firstname: "Rufus", lastname:"Sewell"}, {firstname: "William", lastname: "Hurt"}, {firstname:"Kiefer", lastname:"Sutherland"}], director:{firstname: "Alex", lastname:"Proyas"}, type: "SF", year:"1998"})
> db.movies.insertOne({title:"IRobot",actors:[{firstname: "Will", lastname:"Smith"}, {firstname: "Alan", lastname: "Tudyk"}, {firstname:"Bridget", lastname:"Moynahan"}], director:{firstname: "Alex", lastname:"Proyas"}, type: "SF", year:"2004"})
> db.movies.insertOne({title:"Suicide Squad",actors:[{firstname: "Will", lastname:"Smith"}, {firstname: "Jared", lastname: "Leto"}, {firstname:"Margot", lastname:"Robbie"}], director:{firstname: "David", lastname:"Ayer"}, type: "Action", year:"2016"})
Afin de vous faire gagner un peu de temps, j’ai prévu un dump de ma propre base de données disponible ici.
Vous pourrez l’importer via la commande suivante :
$ mongorestore -d moviesDB moviesDB_dump
Notre base de données est désormais opérationnelle. Passons au développement des fonctions.
Ecriture et déploiement des fonctions
L’ajout de nouveaux films
La première fonction que nous allons écrire permettra d’ajouter de nouveaux films à la collection. Pour le moment nous ne faisons pas encore intervenir GraphQL (un peu de patience, nous verrons cela lors de l’écriture de la seconde fonction ;)).
1 – En premier lieu nous allons générer la fonction. Comme pour ineat-openfaas-calculator, nous utilisons pour cela la commande suivante :
$ faas-cli new ineat-openfaas-post-movie --lang python3-armhf
Nous obtiendrons ici la même structure que précédemment.
2 – Afin de pouvoir utiliser le connecteur MongoDB et contacter la base Mongo depuis le code python, nous ajoutons la dépendance suivante dans le fichier requirements.txt :
pymongo==3.7.2
3 – Côté code, la fonction définie dans handler.py se présente comme suit :
from pymongo import MongoClient
import json
def handle(req):
movie = json.loads(req)
client = MongoClient('mongodb://{ADDRESS_SERVER_MONGO}:27017')
movies = db.movies
result = movies.insert_one(movie)
return "Movie created : " + result.inserted_id
Le code débute avec l’import des dépendances pymongo et json (la première nous permettant d’utiliser le connecteur Mongo pour Python).
On extrait ensuite le contenu JSON de la requête, via l’appel à la fonction json.loads. Ce JSON contient toutes les informations relatives aux films qui seront insérés en base.
Les deux lignes suivantes assureront la connexion à la base (l’url passée en argument de MongoClient étant l’url permettant de contacter le serveur sur lequel est hébergée notre base de données). L’avant dernière ligne insère simplement le nouveau film dans la collection movies.
La fonction se termine en retournant le résultat des opérations, ici ce sera l’id du nouveau document ajouté en base si l’insertion se passe bien. Le code source de cette fonction est disponible ici.
La recherche des films
Pour la recherche nous procédons différemment et faisons intervenir une autre dépendance.
1 – Tout comme pour l’ajout de films, nous commençons par créer une nouvelle fonction ineat-openfaas-get-movies.
$ faas-cli new ineat-openfaas-get-movies --lang python3-armhf
2 – On ajoute la dépendance nécessaire. Nous optons pour le module graphene-mongo, qui fournit une intégration de mongoengine à Graphene.
graphene-mongo
Graphene, comme la plupart des frameworks GraphQL, repose sur les modèles. Un modèle n’est ni plus ni moins que la représentation des données que nous manipulons.
3 – Nous ajoutons un fichier models.py à la racine de ineat-openfaas-get-movies, dans lequel seront centralisés les modèles.
Ici deux modèles y sont définis :
- Person, qui peut être un acteur ou un réalisateur (donnée directement imbriquée dans chaque document de la collection movies).
- Movie, la donnée de base de notre projet. Rappelons que l’ensemble des films est sauvegardé dans la collection movies de la base de données.
from mongoengine import Document, EmbeddedDocument
from mongoengine.fields import (EmbeddedDocumentField, ListField, StringField)
class Person(EmbeddedDocument):
firstname = StringField()
lastname = StringField()
class Movie(Document):
meta = {'collection': 'movies'}
title = StringField()
type = StringField()
year = StringField()
director = EmbeddedDocumentField(Person)
actors = ListField(EmbeddedDocumentField(Person))
L’entité Movie représente ici un document (non imbriqué) de la collection movies, d’où la présence du mot clé meta permettant de faire le lien avec la collection en question.
Chaque champ d’un document de movies est également défini dans la classe Movie. On y retrouve donc le title et le type de film mais aussi le director, qui est un document imbriqué de type Person et les acteurs (une liste de Person).
4 – Les classes déclarées à l’étape précédente ne sont pas directement exploitables. On ajoute un nouveau fichier schema.py à la racine de la fonction. Celui-ci contiendra le code suivant :
import graphene
from graphene_mongo import MongoengineObjectType
from models import Movie as MovieModel
class Movie(MongoengineObjectType):
class Meta:
model = MovieModel
class Query(graphene.ObjectType):
movies = graphene.List(Movie)
def resolve_movies(self, info):
return list(MovieModel.objects.all())
schema = graphene.Schema(query=Query)
La classe Query est utilisée pour générer un schéma. Celui-ci permettra à la fonction de rechercher les films correspondant aux critères spécifiés par l’appelant.
5 – On définit le handler.py, contenant le comportement de notre fonction ainsi que les informations de connexion à la base.
from pymongo import MongoClient
from schema import Query
import json
def handle(req):
# Connexion a la base mongo
connect('moviesDB', host='mongodb://{ADDRESS_SERVER_MONGO}:27017', alias='default')
# Extraction de la requête passée en paramètre lors de l'appel
query = json.loads(req)["query"]
# Exécution de la requête
result = schema.execute(query)
return result
La fonction prendra en paramètre la requête à exécuter (passée dans l’url d’appel). Comme précédemment, les sources sont disponibles ici.
Déploiement et tests des fonctions
Pour le déploiement des fonctions, rien de nouveau : on procède exactement comme précédemment !
Une fois les fonctions déployées, on peut tester. Commençons par ajouter un nouveau film :
$ curl http://192.168.1.19/function/ineat-openfaas-post-movie -X POST -d '{ "title" : "Venom", "actors" : [ { "firstname" : "Tom", "lastname" : "Hardy" }, { "firstname" : "Michelle", "lastname" : "Williams" }, { "firstname" : "Riz", "lastname" : "Ahmed" } ], "director" : { "firstname" : "Ruben", "lastname" : "Fleischer" }, "type" : "Action", "year" : "2018" }'
Une petite requête en base nous permet de nous assurer que l’opération a réussi :

Nous allons à présent rechercher les films d’action, et plus précisément le titre, l’année et le réalisateur de ces films :
$ curl -g -X GET 'http://192.168.1.19/function/ineat-openfaas-get-movies?query={Movie(type : "Action"), {title, year,director}}'

Et voilà ! La fonction nous retourne bien le résultat attendu, à savoir les films “Suicide Squad” et “Venom”. GraphQL permet de requêter beaucoup plus finement des collections, et nous n’avons testé qu’un cas d’usage très simple : je vous laisse le soin de faire évoluer le code présenté ici et perfectionner les fonctions.
Pour aller plus loin
Comme vous avez pu le voir au début de cet article, la prise en main d’OpenFaas et l’écriture de fonctions restent accessibles.
Dans la seconde moitié, nous avons construit une application un peu plus complexe. Celle-ci peu largement être optimisée, notamment lors de la génération du schéma. Dans notre cas, le schéma est directement défini à partir d’un modèle écrit en Python. Ce n’est pas très impactant quand une seule fonction l’utilise mais peut vite devenir problématique lorsque plusieurs fonctions doivent accéder au même schéma (il est alors nécessaire de modifier le code de chaque fonction lorsque le schéma vient à changer). Une solution serait de générer le schéma à partir d’un fichier JSON (et non plus d’un modèle écrit en Python), fichier qui pourrait ensuite être centralisé sur un bucket S3 (Amazon) ou CloudStorage (Google). Les fonctions pourraient alors accéder au JSON “à distance” et donc rester à jour en cas de changement dans le schéma GraphQL.
Dans un prochain article, nous verrons quelles sont les limites à notre façon de développer et comment les contourner. Ce sera également l’occasion d’automatiser la construction des images de nos fonctions :).
Liens utiles
- Partie 1, mise en place du cluster et installation d’Openfaas
- Partie 2, développons quelques fonctions – Vous le consulter actuellement.
- Documentation officielle du projet OpenFaas – https://docs.openfaas.com/
- Code source des exemples de l’article – https://github.com/ineat/ineat-openfaas-article-2-development
- Documentation officielle GraphQL – https://graphql.org/learn/
- Trois méthodes pour représenter un schéma GraphQL – https://blog.apollographql.com/three-ways-to-represent-your-graphql-schema-a41f4175100d
- Documentation officielle MongoDB – https://docs.mongodb.com
- Site officiel de Graphene – https://graphene-python.org/
- Documentation Graphene-mongo – https://graphene-mongo.readthedocs.io/en
