Difficile de participer à des conférences sans entendre parler de monitoring et d’observabilité. On y évoque souvent des termes comme APM, metrics ou dashboards. Mais concrètement ça consiste en quoi ? Est ce que cela nécessite de modifier notre code source ? Y a-t-il des solutions permettant de monitorer nos applications Java sans impacter le code ? Autant de questions auxquelles nous répondrons dans cet article.
Du monito quoi ?
Peu répandu il y a encore quelques années, le monitoring applicatif est aujourd’hui un des éléments clé de bon nombre de projets. Mais au delà du buzzword, en quoi cela consiste-t-il ?
Pour y répondre il suffit simplement de se poser la question suivante : Comment garder un oeil sur l’activité de mon application ?
En somme, comment voir en temps réel la consommation mémoire ou cpu de telle ou telle partie de mon application afin de prévenir les crash en production ?
La réponse devient évidente : avec du monitoring.
On peut le mettre en place de diverses façons :
- en s’appuyant sur des APM (Application Performance Management) comme AppDynamics ou Dynatrace pour observer nos applications.
- en utilisant des solutions comme Micrometer pour exposer des métriques (i.e des indicateurs), qui seront par la suite affichées dans des dashboards (type Grafana).
La première approche a généralement un coût puisque des solutions comme AppDynamics, destinées à de grosses infrastructures, ont des coûts de licence assez importants. Dans le cas d’applications isolées ou de taille relativement réduite, investir sur ce type d’outils devient difficilement envisageable.
La seconde approche repose sur des librairies et outils gratuits mais implique, tout comme pour l’ajout de logs, une modification du code de nos applications. Cela n’est pas vraiment un problème quand ce facteur est pris en compte dès le début des développements, mais dans le cas d’un projet existant l’ajout de métriques peut rapidement devenir long et fastidieux.
InspectIt Ocelot
Et c’est là qu’intervient InspectIt Ocelot ! Il s’agit d’un agent permettant d’observer la JVM et de remonter des indicateurs relatifs à l’activité d’une application Java. Il propose entre autre :
- du Tracing distribué,
- la découverte des dépendances (c’est-à-dire la découverte des services interagissant avec notre application),
- la collecte de tout type de métriques,
- l’ajout, la modification et la suppression dynamique des règles de collecte de données.
Et tout cela sans a avoir a modifier le code des applications monitorées !
Afin de démontrer toute la puissance de l’outil, nous allons le mettre en application sur un projet relativement simple dont la macro-architecture est illustré par le schéma ci – dessous :
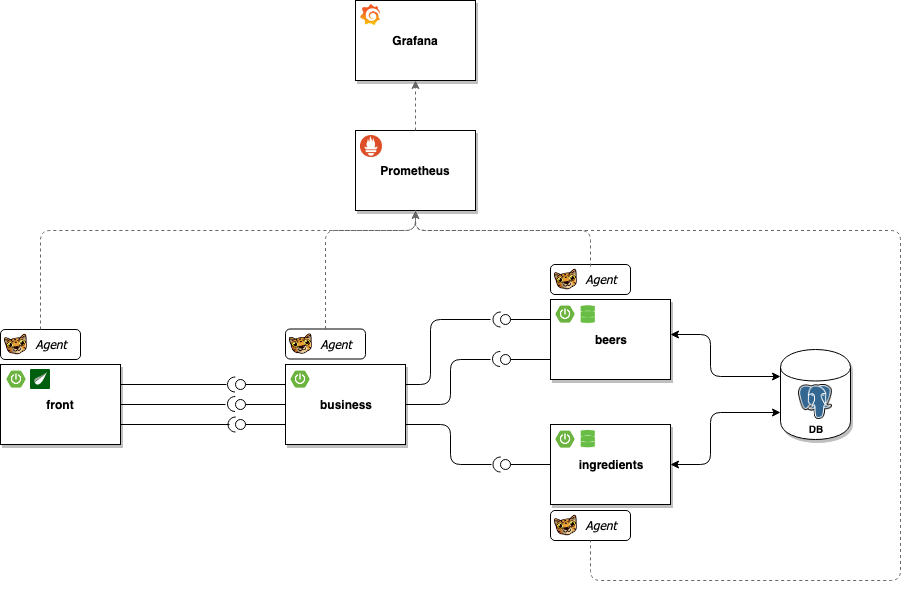
Le projet est un petit jeu dont le but est de reconstituer la liste des ingrédients d’une bière tirée au hazard.
Il est en outre constitué d’un front (en Spring MVC / Thymeleaf), et d’un back faisant appel à deux micro-services :
- le premier permet d’accéder à une liste de bières stockée en base.
- le second est utilisé pour lister les ingrédients eux aussi stockés en base de données.
Le back (la couche business) s’appuie sur ces micro-services pour reconstituer la recette d’une bière donnée.
Chaque brique sera “surveillée” par un agent Ocelot, dont les métriques seront affichées par le duo Prometheus / Grafana.
Le code source complet de l’application est disponible ici.
Premier lancement
Avant de pouvoir lier l’agent InspectIt aux composants de notre application, il est nécessaire de le télécharger :
$ wget https://github.com/inspectIT/inspectit-oce/releases/download/0.4/inspectit-ocelot-agent-0.4.jar
Chaque module du projet est packagé sous la forme d’un jar autonome, et peut être démarré indépendamment.
Pour lancer le front (par exemple), en y attachant l’agent inspectIt on lancera donc :
$ java -javaagent:"https://d3uyj2gj5wa63n.cloudfront.net/path/inspectit-ocelot-agent-0.4.jar" -jar gui.jar
Il est possible d’attacher l’agent à une JVM déjà en cours d’exécution en spécifiant un process ID en argument :
$ java -jar /path/inspectit-ocelot-agent-0.4.jar PID
Une fois lancée, on remarque vite la présence de logs liés à InspectIt, et notamment le suivant :
2019-09-01 16:39:01,829 INFO 2176 --- [inspectIT] [ Thread-0] r.i.o.c.e.PrometheusExporterService : Starting Prometheus Exporter on 0.0.0.0:8888
Par défaut l’agent démarre un exporter Prometheus, d’autres backends sont également supportés et l’agent peut être configuré pour utiliser les exporters associés.
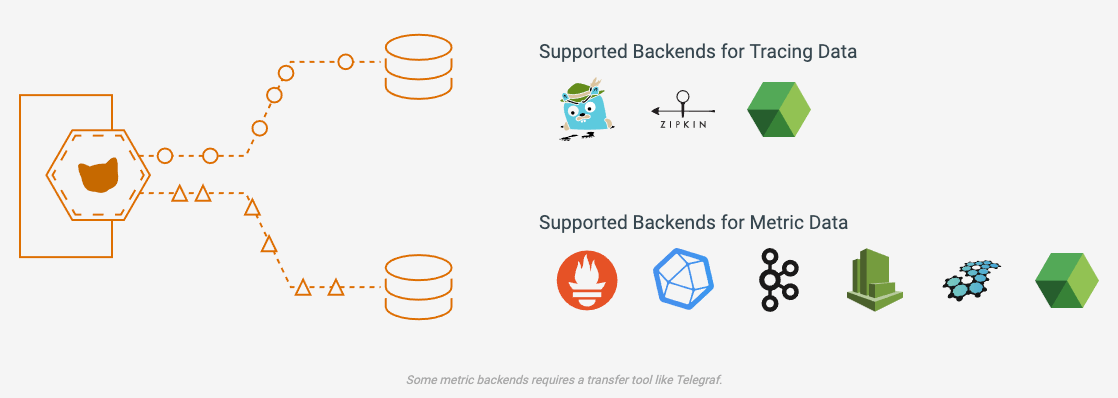
En joignant l’url http://localhost:8888 on retrouve l’ensemble des métriques de bases remontées.
Au sujet des métriques, quelques autres lignes de logs nous donnes des informations sur le type d’indicateur mesuré :
2019-09-01 16:39:02,188 INFO 2535 --- [inspectIT] [ Thread-0] r.i.o.c.m.system.GCMetricsRecorder : Enabling GC metrics recorder 2019-09-01 16:39:02,195 INFO 2542 --- [inspectIT] [ Thread-0] i.o.c.m.s.AbstractPollingMetricsRecorder : Enabling DiskMetricsRecorder. 2019-09-01 16:39:02,197 INFO 2544 --- [inspectIT] [ Thread-0] i.o.c.m.s.AbstractPollingMetricsRecorder : Enabling MemoryMetricsRecorder. 2019-09-01 16:39:02,202 INFO 2549 --- [inspectIT] [ Thread-0] i.o.c.m.s.AbstractPollingMetricsRecorder : Enabling ThreadMetricsRecorder. 2019-09-01 16:39:02,206 INFO 2553 --- [inspectIT] [ Thread-0] i.o.c.m.s.AbstractPollingMetricsRecorder : Enabling ClassLoaderMetricsRecorder
Comme nous le verrons un peu plus loin, il est tout a fait possible de paramétrer ces indicateurs et customiser les données collectées.
D’autres lignes encore nous indiquent les sources depuis lesquelles les configurations sont reprises :
2019-09-01 16:39:00,453 INFO 800 --- [inspectIT] [ Thread-0] r.i.o.core.config.InspectitEnvironment : Registered Configuration Sources: 2019-09-01 16:39:00,453 INFO 800 --- [inspectIT] [ Thread-0] r.i.o.core.config.InspectitEnvironment : systemProperties 2019-09-01 16:39:00,454 INFO 801 --- [inspectIT] [ Thread-0] r.i.o.core.config.InspectitEnvironment : systemEnvironment 2019-09-01 16:39:00,454 INFO 801 --- [inspectIT] [ Thread-0] r.i.o.core.config.InspectitEnvironment : inspectitDefaults
Les sources en question peuvent elles aussi être ajustées finement en fonction de nos besoins.
Les sources de configuration
Les sources de bases
L’agent peut être paramètré de plusieurs façons :
- au lancement de celui ci en passant simplement la configuration en argument sous la forme d’une chaine de caractères.
$ java -javaagent:/path/inspectit-ocelot-agent-0.4.jar="{ \"inspectit\": { \"service-name\": \"Beer Contest GUI\" }}" -jar gui.jar
- en créant une variable d’environnement.
$ java -Dinspectit.service-name="Beer Contest GUI" -javaagent:/path/inspectit-ocelot-agent-0.4.jar -jar gui.jar
- en définissant une propriété système.
$ java -javaagent:/path/inspectit-ocelot-agent-0.4.jar='{ "inspectit": { "service-name": "Beer Contest GUI" }}' -jar gui.jar
Bien que pratique dans le cas où la configuration est assez sommaire, le passage des paramètres en option de la ligne commande peut rapidement devenir illisible. Les prochaines approches sont donc a privilégiées.
Les fichiers
Il est recommandé de centraliser l’ensemble de la configuration dans un fichier, et uniquement spécifier le chemin du répertoire contenant ce(s) fichier(s) :
$ java -javaagent:"https://d3uyj2gj5wa63n.cloudfront.net/path/inspectit-ocelot-agent-0.4.jar" -Dinspectit.config.file-based.path="/path/ocelot" -jar target/beer-0.0.1-SNAPSHOT.jar
L’autre avantage de cette solution est que le contenu des fichiers de configuration est régulièrement contrôlé et toute modification apportée aux fichiers est automatiquement prise en compte sans nécessiter de redémarrage de l’agent.
La fréquence de contrôle des fichiers est de 5s, mais peut être ajustée en fonction de nos besoins avec l’option -Dinspectit.config.file-based.frequency
Endpoint HTTP
Nous venons de voir que la centralisation des configurations dans des fichiers restait simple et était préférable au passage brutal des paramètres via des options de la ligne de commande.
Néanmoins cela implique de donner le chemin complet du répertoire contenant les fichiers à l’agent InspectIt, et dans le cas où ce répertoire venait à être déplacé, l’application finirait par crasher (le chemin du répertoire étant précisé “en dur”).
Une autre solution de centralisation des configurations d’InspectIt Ocelot existe : le serveur de configuration. Il s’agit d’un composant fourni par le projet et disponible sous la forme d’une image Docker.
Pour démarrer le serveur, rien de plus simple :
$ docker pull inspectit/inspectit-ocelot-configurationserver $ docker run -p 8090:8090 -e INSPECTIT_WORKING_DIRECTORY=/configuration-server -e INSPECTIT_DEFAULT_USER_PASSWORD=password -v configuration-server:/configuration-server inspectit/inspectit-ocelot-configurationserver
Le port utilisé ici pour joindre le serveur, et pour se connecter à l’UI, sera le 8090. On précise également le mot de passe a utiliser pour s’authentifier sur l’interface d’admin, ainsi qu’un volume (un répertoire nommé configuration-server) dans lequel seront enregistrés les fichiers de configuration utilisés par les différentes instances de l’agent.
En nous connectant à http://localhost:8090/ui/ avec le login admin et le mot de passe password, nous accédons à une interface d’administration épurée mais très pratique pour ajouter de nouvelles configurations.
Dans notre cas de figure, la première étape consiste à définir la structure de répertoires suivantes :
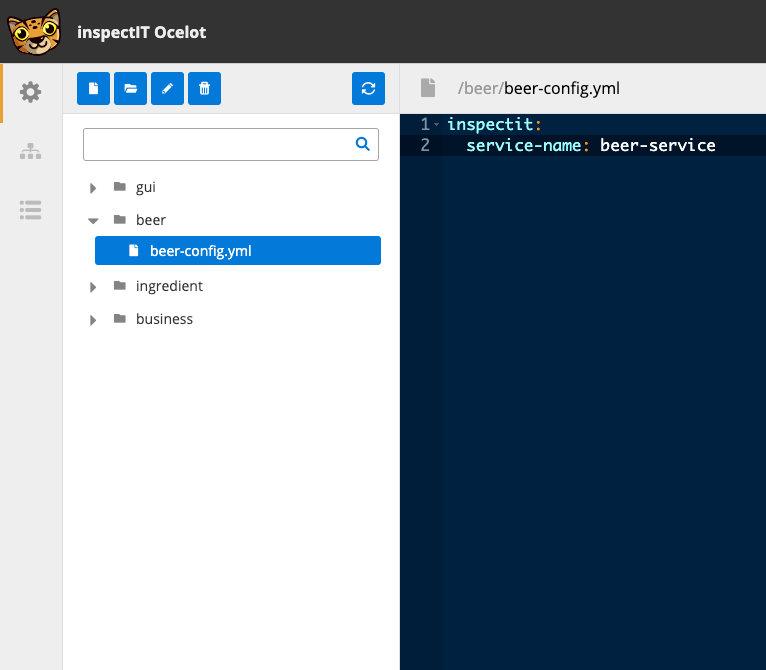
Pour déterminer quels sont les fichiers de configuration associés à un agent donné, le serveur maintient une table d’association. La prochaine étape consiste donc à se rendre dans la rubrique Agent Mapping et à y définir les associations fichiers <=> agents/services.
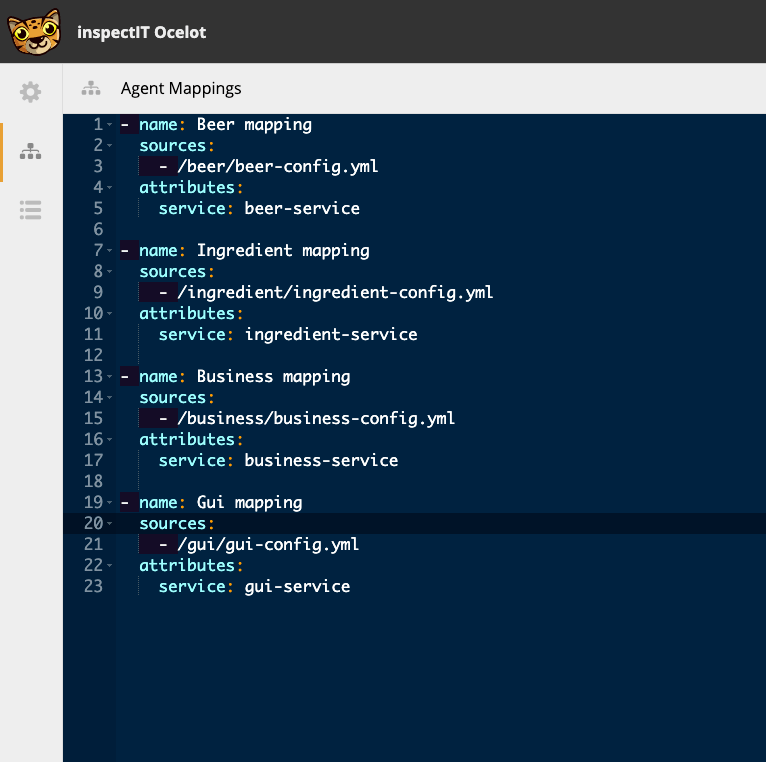
Rien de bien complexe ici : on lie un service-name (défini à l’étape précédente) à un fichier en spécifiant son path (section sources).
Chaque agent est exécuté en précisant en argument l’url du serveur de configuration et le nom du service ciblé, leur permettant ainsi de récupérer le paramétrage adéquat (ci dessous un exemple pour le service “beer”) :
$ java -javaagent:"https://d3uyj2gj5wa63n.cloudfront.net/path/inspectit-ocelot-agent-0.4.jar" -Dinspectit.config.http.attributes.service="beer-service" -Dinspectit.config.http.url="http://localhost:8090/api/v1/agent/configuration" -jar target/beer-0.0.1-SNAPSHOT.jar
Tout comme pour l’usage des fichiers, les configurations centralisées dans le serveur fournit par InspectIt peuvent être reprises à chaud par les agents, en spécifiant la fréquence de rafraîchissement avec l’option
-Dinspectit.config.http.frequency
Paramétrage et personnalisation des métriques
Nous avons vu comment externaliser la configuration, et la rendre accessible aux agents. A présent voyons ce qu’elle contient.
Pour injecter du code de surveillance dans l’application monitorée, InspectIt Ocelot s’appuie sur plusieurs sections importantes de la configuration :
- Les metrics, qui représentent les points de mesure (temps de traitement d’un bloc de code, nombre d’appels a une méthode, …).
- Les actions, pouvant être vue comme des fonctions, qui seront ensuite appliquées sur les données mesurées. Les traitements réalisés par les actions peuvent être définis en Java.
- Les scopes, qui permettent de spécifier le périmètre d’application des actions. Nous pouvons donc “demander” à l’agent d’effectuer des mesures sur des blocs de codes bien précis.
- Les rules qui lient actions, scopes et metrics.
Pour illustrer ces différentes sections, mettons en pratique sur le service “Beer” et commençons par définir les métriques dans beer-config.yml
En partant du principe que nous souhaitons mesurer le temps de traitement cumulé (en ms) et le nombre d’appels à un bloc de code, la section metrics ressemblerait a ceci :
metrics:
definitions:
'[method/duration]':
unit: ms
description: "getBeers Method duration"
views:
'[method/duration/sum]':
aggregation: SUM
'[method/duration/count]':
aggregation: COUNT
Nous avons définit un point de mesure method/duration, qui remontera 2 vues :
- La première permet de donner la durée de traitement d’un bloc de code (method/duration/sum),
- La seconde réalise un cumul d’appels sur un bloc de code donné.
Côté actions, nous allons en déclarer trois :
- Deux d’entre elles seront utilisées pour calculer le temps passé dans un bloc de code,
- La dernière, appelée get_method_full_name, fournira un libellé sous la forme className.methodName
inspectit:
instrumentation:
actions:
get_starting_time:
value: "new Long(System.nanoTime())"
get_time_spent:
input:
startingTime: long
value: "new Double( (System.nanoTime() - startingTime) * 1E-6)"
get_method_full_name:
input:
_methodName: String
_class: Class
value: "new StringBuilder(_class.getSimpleName()).append('.').append(_methodName).toString()"
Les actions prennent des paramètres en entrée, que nous déclarons dans la sous-section input.
Dans le cas de get_method_full_name par exemple, on spécifie en entrée le nom de la méthode ainsi que la classe sur laquelle l’action sera appliquée. La value indique quant à elle la valeur renvoyée par l’action (ici nous concaténons le nom de la classe avec le nom de la méthode).
Comme précisé un peu plus haut, pour délimiter le champs d’action des actions il est nécessaire de définir un scope.
inspectit:
instrumentation:
...
scopes:
rest-call-scope:
type:
name: "com.ineat.poc.beer.BeerController"
matcher-mode: "EQUALS_FULLY"
methods:
- name: "getBeers"
matcher-mode: "EQUALS_FULLY"
visibility: [PUBLIC]
Dans l’extrait de code précédent nous définissons un scope nommé rest-call-scope. Ce dernier s’appliquera sur la méthode getBeers de la classe BeerController (spécifié via type). Ici la recherche du nom de classe et de la méthode est effectuée de façon stricte. Il est toutefois possible de rendre la recherche plus permissive et par exemple trapper toutes les méthodes commençant par getBeers. Dans ce cas le matcher-mode sera positionné à STARTS_WITH.
Les scopes permettent d’aller très loin dans la définition des périmètres d’applications des règles de monitoring. Pour plus de détails, n’hésitez pas a consulter la documentation officielle.
La dernière étape consiste à déclarer les rules qui appliqueront les actions sur les données issues de metrics elles mêmes appliquées sur un ou plusieurs scopes.
inspectit:
instrumentation:
...
rules:
rest_call_duration:
scopes:
rest-call-scope: true
entry:
method_entry_time:
action: start_timer
get_method_full_name:
action: get_method_full_name
exit:
method_duration:
action: get_time_spent
data-input:
sinceNanos: get_starting_time
metrics:
'[method/duration]' : method_duration
On précise le ou les scopes à appliquer, les actions à exécuter en début d’exécution de la méthode getBeers (section entry) et les actions à lancer en fin d’exécution de cette même méthode (section exit). L’action get_time_spentprend en entrée un long qui, dans l’exemple ci-dessus, est renvoyé par une autre actionget_starting_time. La déclaration de la règlerest_call_durationse termine en liant le traitement décrit dans method_durationaux metrics d’où les données à traiter proviendront. Dans notre exemple la métrique method/duration est lié au traitement method_duration.
Démarrez le couple agent et service, et rendez vous sur localhost:8888 pour visualiser le résultat !
Création d’un dashboard
Nous avons désormais à disposition des informations concernant le taux d’utilisation CPU, mémoire, … mais également le nombre d’appels à la méthode getBeers du BeerController, ainsi que le temps de traitement cumulé. Ces deux informations nous permettraient, par exemple, de déterminer le temps moyen de traitement de la méthode getBeers. Mais avant d’afficher cette information dans un joli dashboard Grafana, il est nécessaire de référencer notre beer-service dans Prometheus (ce dernier fonctionnant en mode “pull”, il doit donc avoir connaissance des url à scruter).
Dans la suite de l’article, nous réaliserons les opérations sur un duo Prometheus / Grafana dockerisé. Les commandes suivantes seront utiles pour démarrer ces outils :
$ docker run -p 3001:3000 -e GF_SECURITY_ADMIN_PASSWORD=password grafana/grafana $ docker run -p 9090:9090 -v /tmp/prometheus.yml:/etc/prometheus/prometheus.yml prom/prometheus
Référencer des endpoints dans Prometheus
Prometheus s’appuie sur un fichier prometheus.yml pour initialiser sa configuration, et c’est dans ce fichier que nous allons référencer les urls à partir desquelles seront extraits les relevés.
global:
scrape_interval: 1s
scrape_timeout: 1s
evaluation_interval: 1m
scrape_configs:
- job_name: beers-challenge-monitor
scrape_interval: 1s
scrape_timeout: 1s
metrics_path: /metrics
scheme: http
static_configs:
- targets:
- {IP-BEER-SERVICE}:8888
- {IP-INGREDIENT-SERVICE}:8888
- {IP-BUSINESS-SERVICE}:8888
- {IP-GUI-SERVICE}:8888
On remplacera {IP-BEER-SERVICE}, {IP-INGREDIENT-SERVICE}, {IP-BUSINESS-SERVICE} et {IP-GUI-SERVICE} avec les adresses des services correspondant.
Au démarrage de Prometheus, on retrouvera ce paramétrage dans Status > Targets.
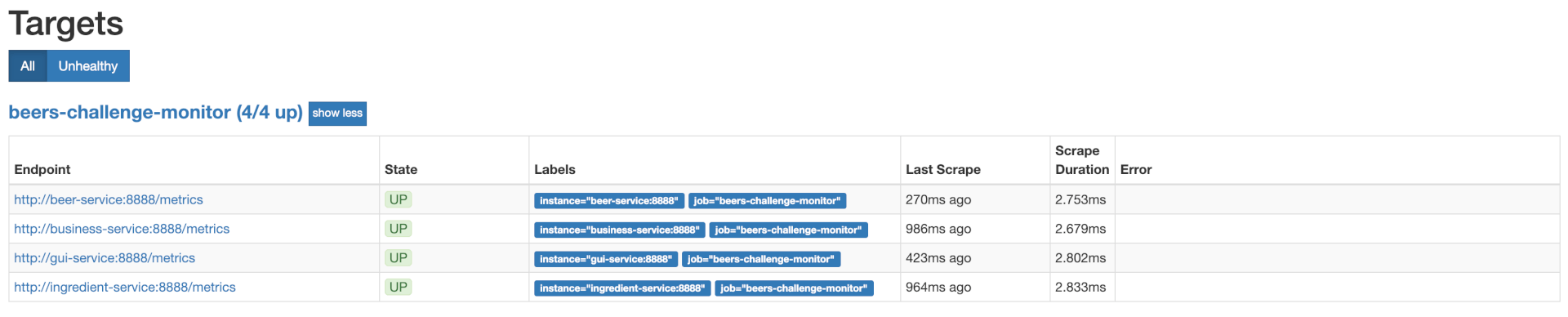
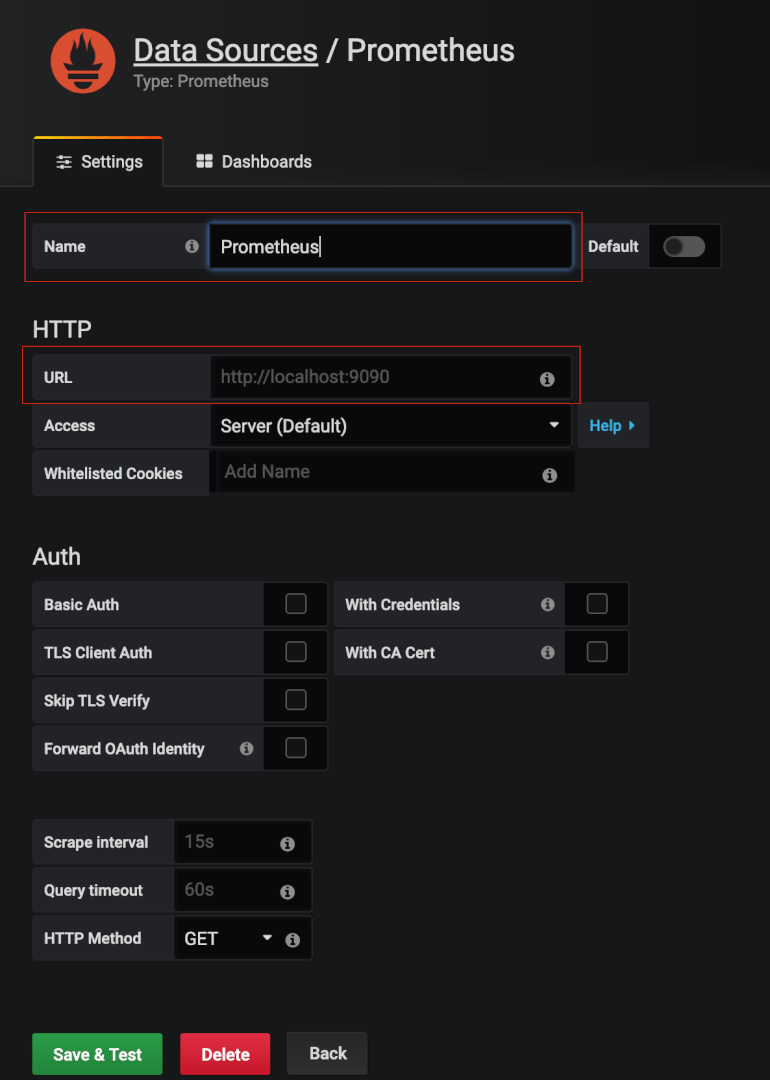
Ajout de la nouvelle data source à Grafana
Une fois notre Prometheus configuré, reste à l’ajouter comme source de données dans Grafana. Pour cela rendez vous dans Configuration > Data Sources, puis cliquez sur Add data source et sélectionnez Prometheus. Enfin, renseignez l’adresse de votre instance Prometheus et sauvegardez. Vous pouvez également changer le nom par défaut de cette nouvelle data source si vous le souhaitez.
Et voilà, nous sommes prêts pour la création de notre Dashboard !
Création du dashboard
La création d’un Dashboard se fait via le menu Create > Dashboard. Une fois le dashboard créé, nous pouvons ajouter de nouveaux widgets avec le menu Add panel. Pour afficher le temps moyen de traitement de la méthode getBeers, nous pourrons par exemple utiliser un panel de type Singlestat, qui prendra en Queries la requête PromQL suivante :
method_duration_sum{get_method_full_name="BeerController.getBeers",service="beer-service"} / method_duration_count{get_method_full_name="BeerController.getBeers",service="beer-service"}
Après avoir ajouté quelques panels, vous obtiendrez alors un dashboard de ce type :
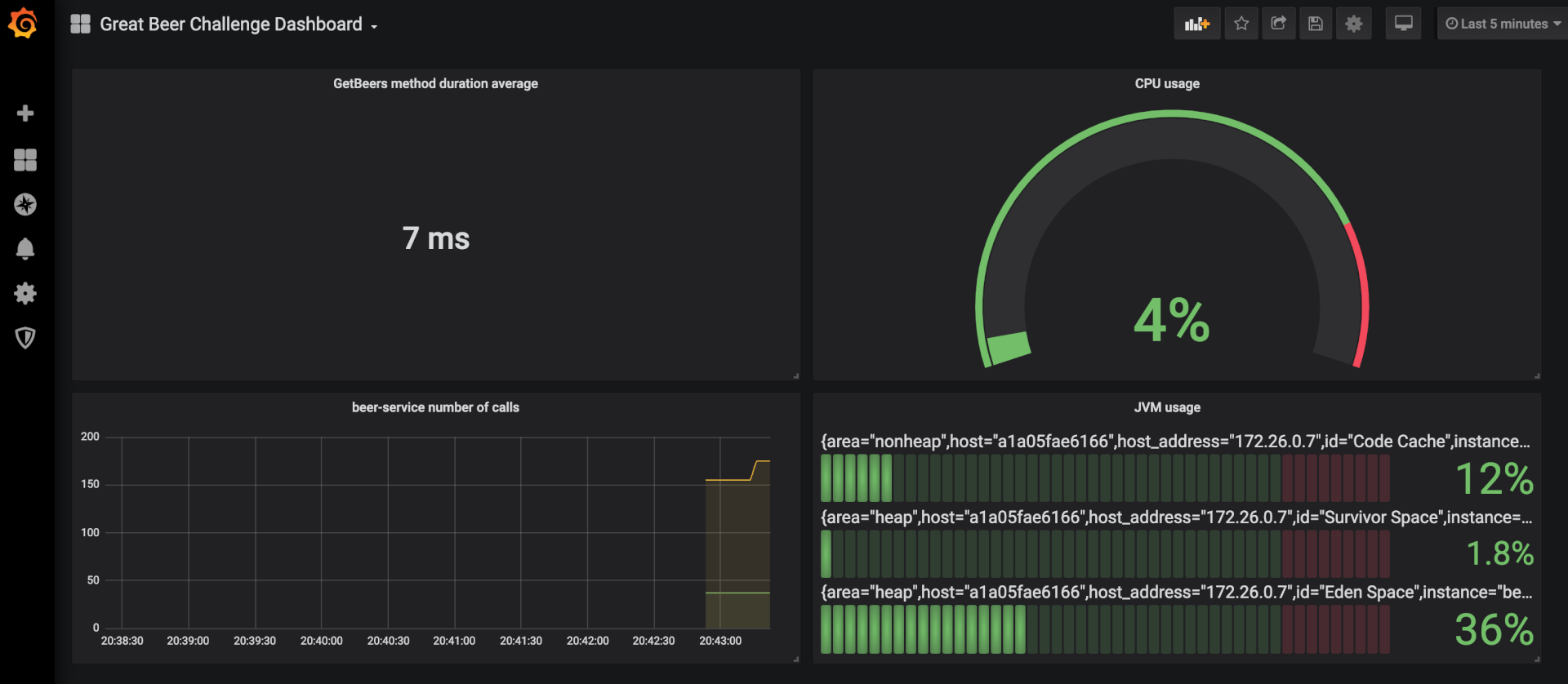
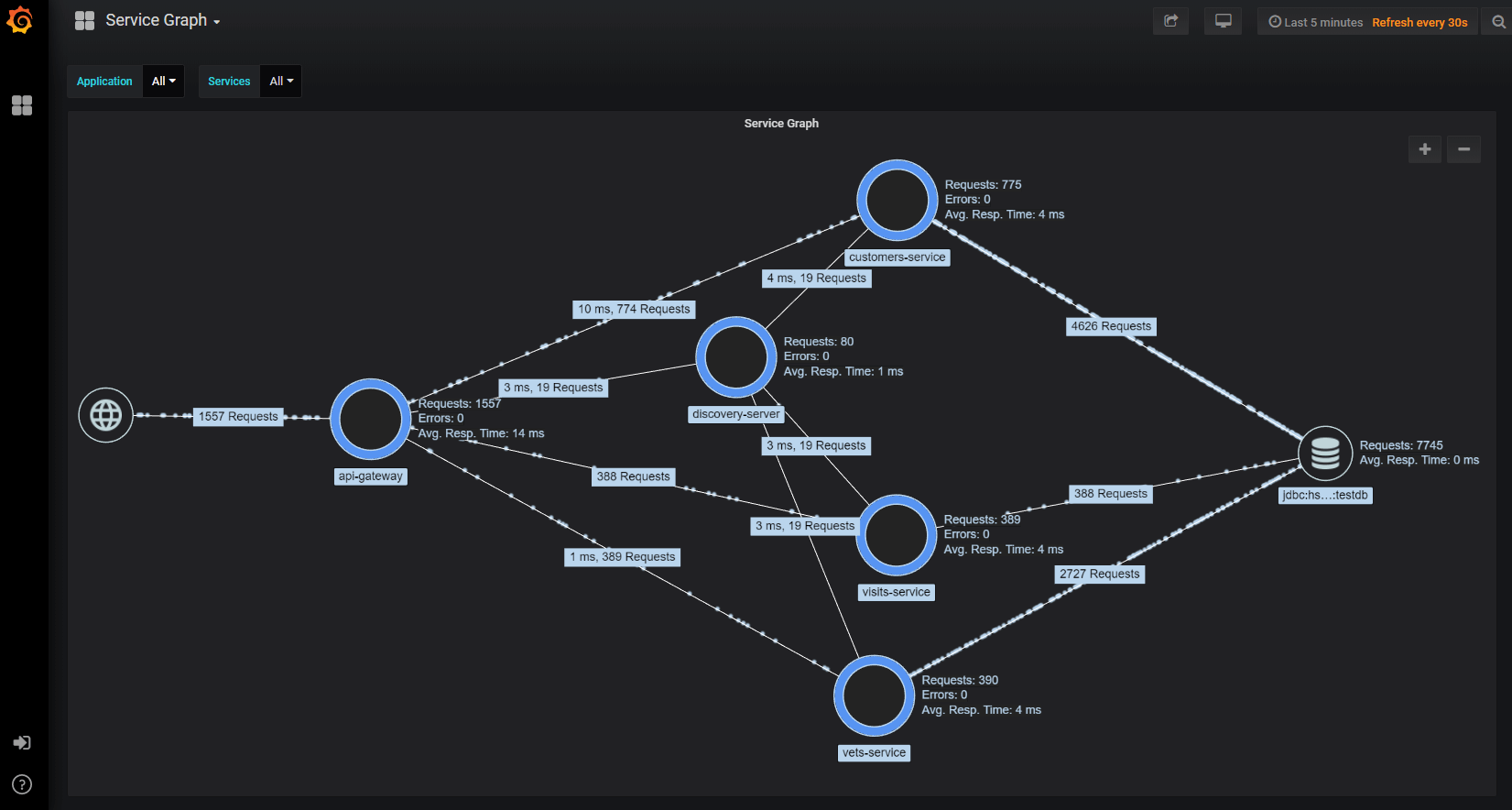
Ceci n’est qu’un exemple, et vous pourrez composer des dashboards plus ou moins complexes en fonction de vos besoins. Des panels beaucoup plus complets, disponibles sur le store de Grafana , permettent d’afficher des données complexes. Citons le plugin service-graph qui vous permettra d’obtenir une vision macro des interactions entre vos services et de visualiser en temps-réel les requêtes HTTP en transite.
Alors quoi penser d’InspectIt Ocelot ?
Et voilà ! Comme vous aurez pu le constater en parcourant cet article, nous avons mis en place simplement et rapidement un monitoring fiable de notre application et cela sans en modifier le code source. Certes la configuration Yaml peut paraître un peu déstabilisante, les nombreux mots clés et les liens entre chaque section pouvant effrayer lors des premières manipulations. Mais après un peu de pratique, vous pourrez monter rapidement vos propres stacks de monitoring basées sur Ocelot.
Nous n’avons fait ici qu’effleurer le potentiel de cette technologie. Sachez qu’elle ne se limite pas uniquement aux relevés de metrics : elle permet également d’effectuer du tracing distribué. Mais cela, vous le découvrirez au prochain épisode.
Liens utiles
- Code source des exemples – https://github.com/ineat/ocelot
- Site officiel – https://www.inspectit.rocks/
- Documentation officielle – https://inspectit.github.io/inspectit-ocelot/docs/doc1
- Lier Prometheus et Grafana – https://prometheus.io/docs/visualization/grafana/
- Documentation PromQL – https://prometheus.io/docs/prometheus/latest/querying/basics/
- Plugins Grafana – https://grafana.com/grafana/plugins
- Site officiel AppDynamics – https://www.appdynamics.fr/
- Site officiel Dynatrace – https://www.dynatrace.com/