
Découvrez nos impressions et notre résumé de la 5ᵉ édition (du 29 mai 2022) de la conférence pour les architectes by OCTO Technology.
Pavillon Chesnay du Roi
Pour le retour en présentiel, l’équipe de la DuckConf a choisi de faire nager ses canards au Pavillon Chesnay du Roi, au cœur du Parc Floral de Paris. Cadre arboré et très sympathique, à une grosse demi-heure de la Gare du Nord en transport en commun.

Comme pour les années précédentes, pas de goodies pour les participants (hormis quelques canards en plastique éparpillés dans le pavillon). Ce budget a été octroyé à l’association La Croix-Rouge et on préfère ça !
Nous avions évidemment accès sur place à de la restauration : des viennoiseries à notre arrivée, des litres de cafés et des jus de fruits bio tout au long de la journée ainsi qu’un panier repas froid le midi, (accompagné de quelques bouchées chaudes) pour nous remplir l’estomac. L’architecture ça creuse.
L’équipe est toujours aussi enthousiaste et souriante, on ne change pas un canard qui gagne 😉
Quelques nouveautés cette année
Quelques nouveautés cette année :
- La possibilité de suivre la conférence à distance, mais une semaine après
DIGITAL DUCK, c’est le nom de ce ticket virtuel. Quasiment cinq fois moins cher, il permet d’avoir accès aux vidéos des conférences une semaine après l’événement. Enfin, sur le papier.
- Le lancement d’une chasse aux non-canards tout au long de la journée, permettant de gagner Le Livre de La Duck au format broché : le résumé des comptes-rendus de l’édition 2021.

Belle idée. Nous avons su débusquer une girafe qui faisait de l’ombre aux canards. Gagné !
- La possibilité de poser des questions après les conférences, enfin !
Il s’agissait d’une forte demande de la part des conférenciers et l’équipe de la DuckConf a su répondre à cette demande. Un créneau d’une quinzaine de minutes était dédié aux questions.
Et il y en a eu, souvent très pertinentes, avec les réponses adaptées des speakers. Petit effet de bord à cela… des conférences moins longues (30 / 35 minutes contre 45 / 60 minutes auparavant) et donc moins de contenus ou des sujets moins approfondis.
- Des ateliers en parallèle des conférences
Et oui, nous avions la possibilité de réserver une place dans un des workshops proposés au détriment de la participation à une conférence. Un bon moyen de découvrir des sujets concrets lors de sessions pratiques de live coding.
Belle initiative.
Seul bémol, la conférence suivante avait déjà commencé, le temps de changer de salle. Les organisateurs ont fait le choix d’enchainer (et prendre de l’avance) les sujets si la session de questions était écourté. Pour l’année prochaine, il serait plus adapté de respecter les horaires de fin de session afin d’éviter ces déboires.
Bien, à présent, place à nos résumés des talks !
DOCTOLIB – JUSQU’ICI, TOUT VA BIEN
NICOLAS MARTIGNOLE & DAVID GAGEOT
Comment mieux débuter cette journée de conférences ?
Nos amis de chez Doctolib sont de retours à la DuckConf (3 ans après nous avoir parlé de Boring Architecture) pour faire le point sur l’état de leur plateforme, après toutes ces vagues de COVID.
Et c’est assez bluffant.
D’abord, l’équipe s’est étoffée depuis 2019, la société est passée de 110 à 500 personnes en France, dont 250 profils techniques. Pour gérer une équipe aussi importante, Nicolas évoque une organisation en constante évolution, inspiré de (l’ouvrage) Team topologies.
On y apprend que Doctolib, c’est :
- 20 pulls requests (PR) mergées toutes les 3 heures
- 3 livraisons en production par jour
- 40 000 tests pour valider les développements, joués sur chaque push
- 1/3 sont des tests end-to-end
- tout ça orchestré par une plateforme d’intégration maison propulsée par 12 clusters Kubernetes
Pour faire face à la montée en charge de la plateforme Doctolib, les équipes ont commencé des chantiers de modularisation (ou modernisation ?), mais en gardant toujours une approche unitaire.

- Concernant le stockage, et puisque la solution, PostgreSQL atteints ses limites dans leur contexte (20M rpm et 23 To de données), deux solutions sont en études actuellement :
- Créer un cluster PostgreSQL de 2 bases ou plus : une révolution d’après les dires de David Gageot car l’approche unitaire est remise en question ;
- Remplacer Aurora par une base de données plus élastique comme Citus, Cloud Spanner ou Yugabyte.
- Concernant la codebase, Doctolib souhaite passer du monolithe au “modular monolith” afin d’offrir un découplage de ses composants.
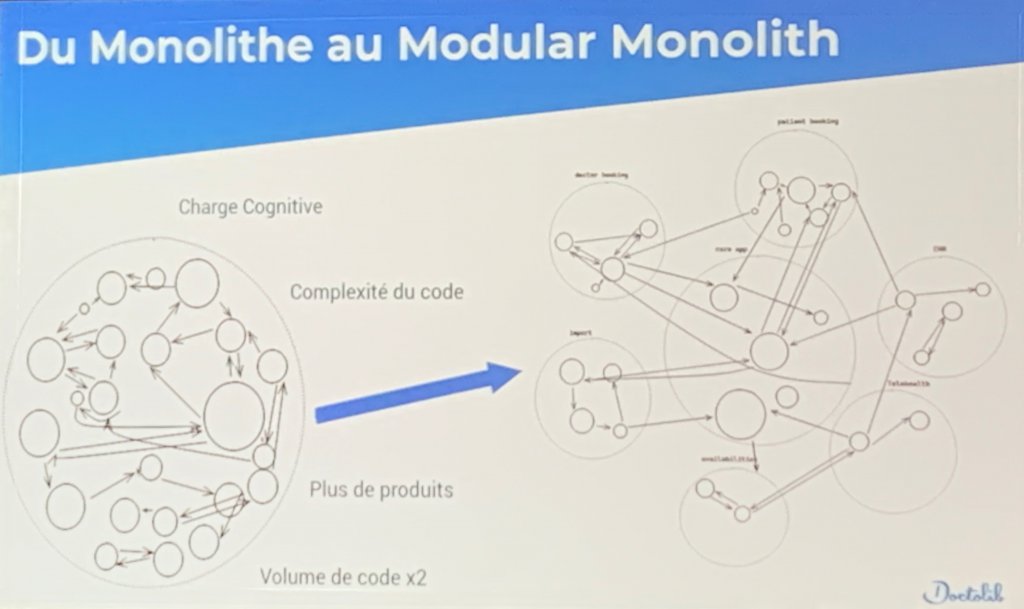
Cette nouvelle architecture permettrait par exemple de réduire le nombre de tests à jouer (les tests seraient “scopés” aux modules) et donc l’infrastructure nécessaire à leurs exécutions (et ça, ça serait bon pour la planète !).
En tout cas, on a hâte de retrouver Doctolib lors d’une prochaine édition afin de découvrir ce qui a réellement été fait !
Au fait, Doctolib a racheté Tanker en 2022 afin de renforcer la sécurité de sa plateforme et de chiffrer ses données de santé de bout en bout.
DuckConf 2022
APPRENDRE LA NORMALITÉ OU DÉTECTER L’ANORMALITÉ AVEC L’IA ?
Un sujet sur l’IA avec un use-case sur la sécurité : comment détecter des intrusions informatiques grâce à l’IA ?
Reynald introduit son talk en nous indiquant qu’en moyenne, les équipes IT découvrent une attaque 212 jours plus tard et que les attaquants exploitent les failles durant 56 jours (d’après un rapport d’IBM). Il est donc déjà trop tard quand les analystes sont sollicités.
Le talk est basé sur un Proof Of Concept effectué pour une université canadienne et qui propose une approche interessante.
Plutôt que d’apprendre à un modèle IA quelles sont les attaques (Brute Force, DoS, etc) possibles dans le monde du web, les équipes de Reynald ont entraîné l’IA à comprendre quels étaient les scénarios normaux. Apprendre les comportements normaux au lieu d’apprendre les comportements anormaux !
De cette manière, dès qu’une donnée ne semble pas normale pour l’IA, celle-ci peut très facilement la détecter et alerter les analystes.
Concrètement, Reynald nous explique avoir utilisé un encodeur (algorithme d’apprentissage) pour apprendre cette normalité. Pour les besoins du POC, l’encodeur a été alimenté avec un extrait de logs applicatifs (en provenance de pare-feu, proxy ou applications), préalablement nettoyé pour en éliminer les logs anormaux (ceux qui pourraient être produits suite à des attaques).
Un petit échantillon (moins de 3 jours d’historique) aurait été suffisant à l’IA pour apprendre et détecter plus ou moins efficacement les attaques.
- Brute Force ✅ ✅
- Dos / DDos ✅ ✅ ✅ ✅ ✅
- Heart Bleed ✅
- Infiltration ✅ ✅ ✅
- Port scan. ✅
- Web attacks. 🚫 🚫 🚫
- Botnet ARES 🚫
KEEP CALM AND WORK EFFECTIVELY WITH LEGACY INFRA-AS-CODE
Premier atelier auquel nous avons participé, animé par Benjamin.
Au menu ? De l’infra-as-code. Plus précisément, de l’infra-as-code avec Terraform sur un kata de refactoring.
Objectifs ?
- L’équipe de dev demande un nouvel environnement aux 2 existants. Cet environnement s’appellera stg. Il faudra refactorer le code tout en conservant le bon fonctionnement des 2 environnements existants ;
- Le RSSI demande d’avoir un groupe de sécurité pour tous les environnements afin de leur faciliter le monitoring des accès ;
- Le dernier objectif sera de faire évoluer le type de VM, actuellement Centos, vers Ubuntu, aussi pour des raisons de sécurité.
Benjamin avait soigneusement préparé les différentes étapes du kata afin de tenir les 45 minutes d’atelier, et c’est malin (on sait tous que le live-coding ne se passe jamais comme prévu !).
Il a ainsi pu communiquer sa démarche de refactoring :
- S’approprier le code en le parcourant ;
- Mettre le doigt sur les portions de code non-conventionnelles ou impactées par les objectifs ci-dessus ;
- Effectuer le refactoring pas à pas en jouant les dry-run Terraform au fil de l’eau pour s’assurer de la non-régression.
Sympathique à suivre même si cet atelier était plus destiné à des profils peu expérimentés (ce qui n’est pas notre cas 🙃).
Le Kata est disponible sur github si vous souhaitez le jouer.
5 ANGLES MORTS À DÉRISQUER POUR BIEN MENER SON CHANTIER DE PERF
Un sujet sur la performance ? Génial !
Jennifer propose, lors de ce talk, un REX de son projet client “RdvPermis”. Au programme, les tests de performances ! Avec des pics journaliers dépassant les 30 000 utilisateurs sur 15 min, il était très important pour eux de mettre en place des tests de performances permettant de valider le comportement de leur plateforme face à une telle charge.
Il est nécessaire d’avoir certains points en tête pour mettre en place de tels tests :
- Générer des jeux de tests cohérents
- Cela peut être fastidieux et chronophage, mais c’est une étape importante et nécessaire. Ces jeux doivent être représentatifs et avoir du sens métier.
- Actualiser les jeux de test en fonction des évolutions
- Les jeux de tests ne doivent pas rester figés au cours du temps, sinon, ils perdront de leur cohérence vis-à-vis du système. En effet, ce dernier va évoluer au cours du temps (optimisation et ajout de fonctionnalités) et les jeux de tests doivent évoluer en parallèle.
- Penser à la capacité de réinitialiser les tests
- Les tests de performance doivent pouvoir être rejoués autant de fois que nécessaire. La capacité à réinitialiser doit donc forcément être prise en compte (suppression/ajout/maj en base, création/suppression de fichiers…).
- Faire les tirs sur un environnement cible
- Pour avoir du sens et être pertinent, les tests de charge doivent s’effectuer sur un environnement “iso” production. Sans cette condition, il est impossible de déduire les comportements de l’environnement de production lors de pics de charge.
- Comparer ce qui est comparable
- Lors de ces tirs, il est important de savoir ce que l’on souhaite mesurer et comparer. Veut-on être en dessous des SLAs ? Désire-t-on comparer par rapport aux précédents tirs ? Et dans ce cas, compare-t-on la même chose ? Avons-nous ajouté des fonctionnalités ?
Une fois ces quelques points pris en compte, la mise en place de ces tests se fait de manière plus sereine, avec moins de surprises 🙂
LE MODÈLE DES “SUPER APPS” ASIATIQUES ENFIN DÉCHIFFRÉ !
HANA AMIRI
Hana est architecte chez Octo et vient nous parler d’architecture mobile, et plus précisément des architectures “Super Apps”. Mais alors qu’est-ce qu’une Super App ?
Une Super App est une application mobile qui en agrège pleins d’autres, tout simplement !
Ce modèle d’application présente quelques avantages :
- L’application embarque de nombreux services (contre le modèle traditionnel une application = un service) ce qui fidélise davantage l’utilisateur ;
- Ce modèle favorise les partenariats et permet d’accéder à des services tiers pouvant nous économiser l’installation d’applications pour ces services. Du côté des partenaires, c’est du gagnant-gagnant puisqu’il minimise les coûts permettant de proposer leur service (moins de développements, mais plus d’intégrations ?) ;
- Et puis il ne faut pas se leurrer, ce modèle permet de recueillir de la donnée sur l’ensemble des fonctionnalités de la Super App, une mine d’or pour les entreprises.
Anna nous présente deux approches différentes pour créer une Super App : celle de WeChat et celle de Revolut.
Modèle WeChat
Cette SuperApp est devenue en quelques années une des plus grosses SuperApp connues sur le marché. Historiquement application de messagerie, elle propose aujourd’hui quelque 20 millions d’applications en son sein. 20 millions !!
Alors comment réussir à proposer autant d’applications ?
Le modèle de WeChat repose en fait sur ce que nous connaissons déjà avec l’approche Micro-Frontends :
- Le socle applicatif est une coquille native Android ou iOs ;
- L’éditeur (ici WeChat) propose ensuite un SDK aux partenaires basé sur les technologies web ;
- Ce SDK est capable de communiquer avec un bridge JavaScript dans l’application afin d’accéder à l’écosystème du téléphone, et de WeChat (paiement, authentification, etc.) ;
- Chaque partenaire a juste à développer son application web en respectant les guidelines WeChat.
Modèle Revolut
Revolut est une neo-banque numérique qui intègre également plusieurs services au sein de son application, mais son modèle est tout à fait différent.
Si vous connaissez ou utilisez l’application, vous savez que l’UX est soignée et cohérente.
Ce résultat est dû au fait que chaque service de l’application est développé par les équipes Revolut, à la différence de WeChat.
- Les applications Revolut (Android ou iOs) sont complétement natives ;
- Elles possèdent chacune une structure Core contenant les modules de paiement, d’authentification ou encore de wallet ;
- Les équipes Revolut développent les modules natifs à intégrer dans l’application ;
- Les partenaires doivent fournir les APIs de leurs services, et c’est tout.
Vous pouvez retrouver un billet d’Hana à ce sujet ici même.
LES BONNES HABITUDES DE CODE D’UN DATA SCIENTIST
Lors de cet atelier, Maria Mokbel nous montre en live coding comment exporter du code exploratoire (test) issu d’un Notebook Jupyter, afin d’implémenter des tests unitaires dans son IDE.
La parti decouverte, exploration et test du notebook Jupyter est pratique et permet rapidement d’avoir des résultats, mais pour passer à une phase d’industrialisation de la solution, il est préferable et souhaitable (voire nécessaire) de passer par un bon IDE.
De plus, les IDE proposent des fonctionnalités “d’assistance” (autocomplétion, génération automatique de code…) qui permettent un gain de productivité.
L’atelier se concentre donc sur la récupération du code du notebook Jupyter, de l’intégration de ces parties de code dans un projet au sein de l’IDE, de la mise en place de tests unitaires et d’une partie de refactoring de ce code. Atelier plus orienté tests unitaires et IDE que data scientist finalement.
SRE : DÉCOUVREZ LES PRATIQUES DE RUN DE DEMAIN
Malheureusement pour nous, nous sommes arrivés une vingtaine de minutes après le début de cette conférence, celle-ci ayant commencé en avance alors que l’atelier dans l’autre salle n’était pas terminé.
On retiendra que l’auteur se base sur le livre Site Reliability Engineering de Betsy Beyer, Chris Jones, Jennifer Petoff et Niall Richard Murphy, membres clés de l’équipe SRE chez Google. Celui-ci est disponible gratuitement : https://sre.google/sre-book/table-of-contents/.
5 TRUCS QUE VOUS DEVRIEZ ARRÊTER DE FAIRE VOUS-MÊME
Cette session nous explique ce que nous devrions arrêter de faire nous même, car cela n’apporte pas de valeur ajoutée et nous ne permet pas de nous distinguer des concurrents. En effet, avec les multiples solutions cloud existantes sur le marché, les entreprises ont la possibilité (le devoir ?) de se concentrer sur leur cœur de métier.
Des bases de données à l’hébergement en passant par le build, le déploiement, les middlewares et même la gestion des certificats, il existe actuellement de très nombreuses solutions sur lesquelles Florent JABY nous conseille fortement de s’appuyer.
Là où précédemment, on migrait vers le cloud pour faire face à des charges variables et non prévisibles (scalabilité du cloud), on y va maintenant aussi par facilité, pour s’appuyer sur des solutions éprouvées afin de se concentrer sur son métier et ses valeurs ajoutées et ainsi gagner en time-to-market.
Cette mouvance n’est pas nouvelle car la plupart des entreprises et du public de cette conférence en ont déjà bien conscience et ont pour beaucoup déjà entamé cette “migration” dans les nuages.
Quelques remarques sur ce qu’on pourrait d’ailleurs appeler une “course” vers le cloud:
- Le cloud, ca côute plus cher !
- Pas forcement !! Quand on exploite nous même nos machines, ont oublie souvent les coûts perdus et les coût cachés ;
- Quid du cloud souverin ?
- Le cloud se développe bien, notamment en France et nous avons de plus en plus d’offres qui permettent de garantir le stockage et l’exploitation des données sur le territoire.
OBSERVER SON SI EN 3 DIMENSIONS AVEC LE CORE DOMAIN CHART
Dernier atelier proposé de la journée et victime de son succès, la session proposée par Romain Vailleux était bel et bien pratique.

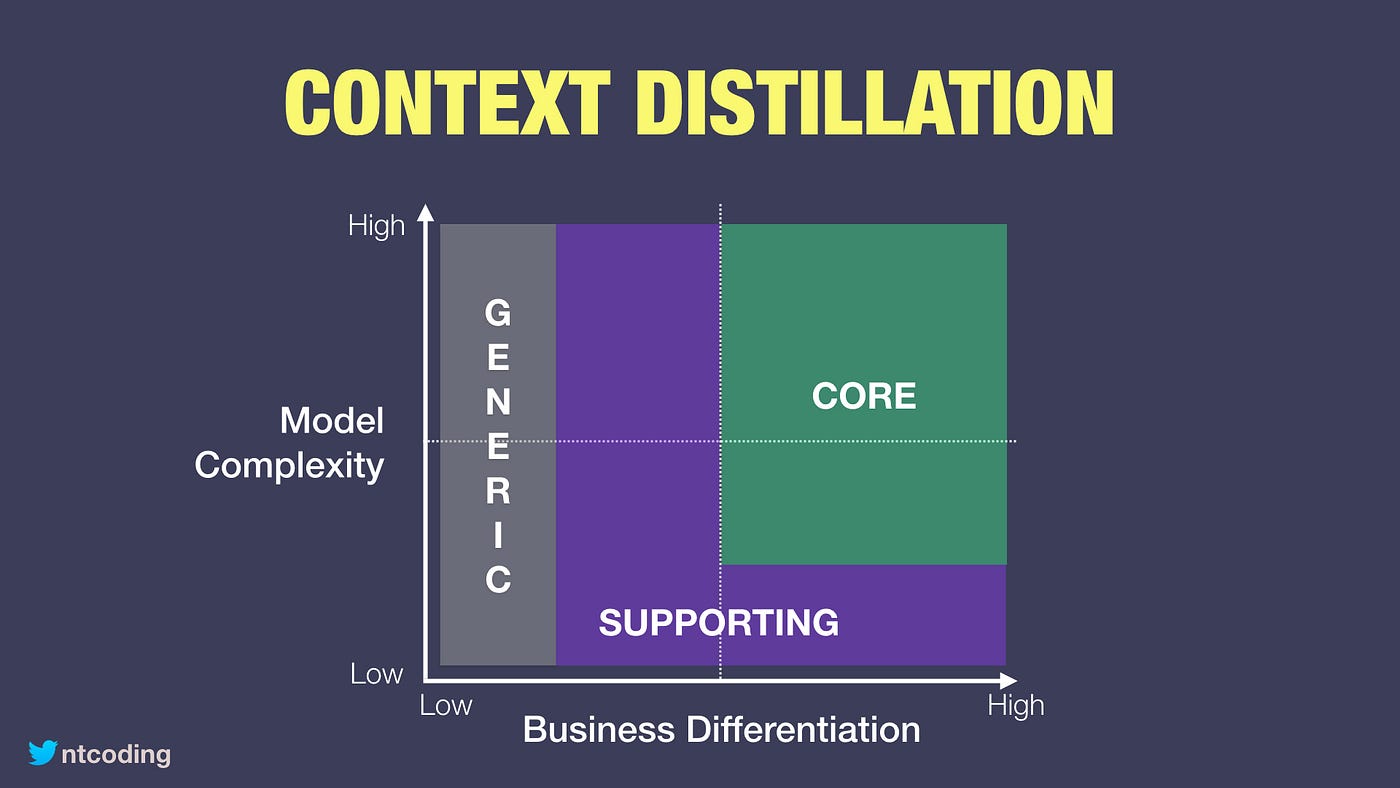
L’approche Core Domains est issue du Domain Driven Design et permet de travailler autour des enjeux business et techniques des domaines d’une DSI. Son objectif est de pouvoir cartographier visuellement les domaines par niveaux de complexité et différentiations business.
Si nous traduisons, cela permet de déterminer :
- Les périmètres critiques (CORE) de l’activité d’une société. Les équipes et outils de ces périmètres devront être stratégiquement gérés par la société ;
- Les périmètres transverses (SUPPORTING) qui devront être pilotés et gérés en partie par la société ;
- Les périmètres génériques (GENERIC) pour lesquels il sera possible de déléguer l’activité (offshore, sous-traitance, etc).
L’atelier nous plonge dans un jeu de rôle (nous sommes 6 autour de la table) et nous devons positionner sur le plateau les domaines métiers de notre entreprise fictive (VoyagerPlusLoinQueChezSoi) couplés aux applications IT (CRM / APIs / websites / etc) sur base d’une session d’Event Storming.
Les discussions commencent, certaines décisions sont prises et d’autres restent en suspens, car l’équipe n’arrive pas à se mettre d’accord. Est-ce que la CRM doit être gérée par le domaine Business Excellence ou par le domaine Relation Client ? Est-ce que ce domaine est différenciant niveau business ? Pourrait-on prendre un outil du marché pour la gestion des appels ?
Si nous avions réussi à aller au bout de l’exercice (car 45 minutes, c’est très court), nous aurions pu délimiter des équipes en charge de chaque périmètre et y assigner des ETPs en fonction de la criticité du périmètre afin d’optimiser les différents chantiers à mener au sein de notre SI.
Superbe idée cet atelier, mais malheureusement mal calibré, ce qui nous a empêché de recevoir les conseils et conclusions de Romain.
Le Core Domain Charts tire ses inspirations de Team Topologies et Wardley Mapping
FAIRE PARLER LA DONNÉE POUR MIEUX COMPRENDRE LE DÉBAT POLITIQUE
Dans cette conférence, Nicolas Cavallo nous montre par l’exemple comment récupérer et interpréter des données provenant de réseau sociaux (ici twitter) et surtout, comment interpréter les résultats.
Au programme, du NLP et des statistiques : comment faire parler la donnée et comment le faire de façon à ce que celle-ci, à partir d’un petit échantillon, soit représentative du plus grand nombre.
On retiendra que la terminologie employée pour expliciter les résultats est très importante, elle renseigne, par exemple, la façon dont les données sont extraites et extrapolées (sur la population globale, sur une sous partie, parmi les personnes actives sur twitter, etc.).
BIENVENUE DANS LE MARVEL ARCHITECTURE UNIVERSE : THE EXPERT WAR
La journée s’achève en beauté par une conférence de Romain Taillade, Chief Technical Innovation Officer chez Décathlon. Le sujet : comment faire évoluer un SI vieillissant quand la seule documentation existante est répartie entre les différents “experts” de la société et que ceux-ci sont peu enclins au changement.

Romain nous explique les difficultés humaines auxquelles il a dû faire face pour faire évoluer l’une des briques les plus critiques du SI ; et quelles solutions il a trouvées pour y remédier.
La méthodologie est empirique : essayer, échouer, recommencer. Des sessions de travail courtes pour ne perdre personne, réunis dans la même pièce, avec des hypothèses ayant pour but d’être cassées jusqu’à ce que ce ne soit plus possible.
Les hypothèses restantes constituent les futurs spécifications. A partir de celles-ci un document d’architecture type est rédigé.
Cette nouvelle méthode a produit ses fruits puisqu’en quelques mois, il a été possible de refondre cette brique. Elle est de plus en plus utilisée au sein des équipes de Décathlon.
Conclusion
Ce qu’on a aimé
- L’organisation de l’événement, toujours au top ;
- Les ateliers et la possibilité de poser des questions (enfin !) ;
- La variété des sujets et l’expertise des speakers.
Ce qu’on a moins aimé
- Très peu de sujets d’architecture au final ;
- Des talks moins approfondis (sans doute lié au temps alloué pour les questions…) ;
- Les talks qui commencent avant l’heure prévue.
Un mot de nos reporters ?
C’est toujours un plaisir de participer à cette conférence d’architecture (c’est la 3ᵉ fois pour moi). Mais cette année, les sujets n’en étaient pas vraiment, des sujets d’archi, je m’attendais à mieux.
J’espère retrouver la qualité des talks des premières éditions où je découvrais des uses-cases de folie tout en apprenant.
Ludovic Dussart – Solutions Architect chez Ineat
Pour ma part, c’était la première participation à cette conférence. Mon ressenti se rapproche de celui de Ludovic. Je m’attendais à un conférence centrée sur l’architecture mais ce n’était que trop rarement le cas. Trop peu de découverte / nouveauté sur les sujets abordés. Ceci étant dit, les sujets restaient intéressants et les speakers de qualité.
Simon Steinmetz – Solutions Architect chez Ineat
Je rejoins l’avis de mes collègues, trop peu de sujets d’architecture, perdus entre des sessions de découvertes traitant de sujets connus pour la plupart depuis des années, s’adressant selon moi d’avantage à des profils peu expérimentés qu’à des architectes.
Antoine Descamps – Solutions Architect chez Ineat
