
Cet article est le premier d’une série concernant Clickhouse.
Pour les besoins d’un projet en cours de développement chez Ineat, nous mettons en place la base de données Clickhouse et nous avons beaucoup appris sur cette solution assez méconnue. Nous allons donc vous la présenter ici dans les grandes lignes, car il faudrait bien plus qu’un article pour couvrir l’ensemble des fonctionnalités que cette dernière propose !
Clickhouse est donc une base de données orientée colonnes (BDMS) créée en 2009 par Alexey Milovidov. Initialement, c’était un projet expérimental permettant de générer des rapports en temps réel sur des données non agrégées qui arrivent en permanence (streaming d’événements).
Écrite en C++ et développée par Yandex, elle fut mise en production en 2012 (après 3 ans d’étude) pour répondre à des besoins d’analytique en ligne (OLAP).
Elle est notamment utilisée par
- Yandex.Metrica : premier concurrent de Google analytics, 374 serveurs, 20,3 billions de lignes pour un volume de donnée utile compressé de 2 pétaoctets (sans les réplications),
- Yandex.Tank : outils de test de charge,
- Yandex.Market : Marketplace – Clickhouse est utilisé pour monitorer l’accessibilité des sites
- et bien d’autres comme Uber, Comcast, eBay, Contentsquare ou encore Cisco.
La solution est passée open source depuis 2016 et certaines sociétés proposent du support comme Altinity.
En septembre 2021, et suite à sa popularité grandissante, le siège social ClickHouse Inc. s’est constitué dans la baie de Californie (USA) (avec une filiale en Europe basée à Amsterdam (PB)) pour héberger la technologie open source avec un investissement initial de 50 millions de dollars provenant notamment de :
En octobre 2021, la société a reçu un nouveau financement de série B totalisant 250 millions de dollars pour une valorisation de 2 milliards de dollars, accueillant de nouveaux investisseurs comme :
Pour la petite histoire, ClickHouse a été implémentée au Centre Européen de la Recherche Nucléaire pour l’expérimentation Large Hadron Collider beauty (exploration des légères différences qui existent entre matière et antimatière grâce à l’étude d’un type de particule appelé « quark beauté » ou « quark b ») qui stocke et process des métadonnées sur 10 milliards d’événements avec 1000 attributs par événement !
Caractéristiques

ClickHouse est une véritable base de données orientée colonnes.
Elle permet de générer des rapports extraits de petabytes de données en moins d’une seconde. La solution permet aux utilisateurs de générer ces rapports en utilisant des requêtes SQL en temps réel.
En 2016, le système offrait un débit de cent mille lignes par seconde. Aujourd’hui, il peut atteindre des centaines de millions de lignes par seconde.
Avantages

La solution est masterless et est facilement scalable par l’ajout de serveurs.
Elle est tolérante à la panne par sa conception : c’est un système composé de shards clusterisés, ou chaque shard est répliqué sur un ou plusieurs nœuds. Clickhouse utilise pour cela une réplication asynchrone basée sur Zookeeper : les données sont écrites sur n’importe quel shard disponible qui sera répliqué dans un second temps sur les autres nœuds.
Exemple d’un cluster sur 6 nœuds, 3 shards et une réplication par shard:
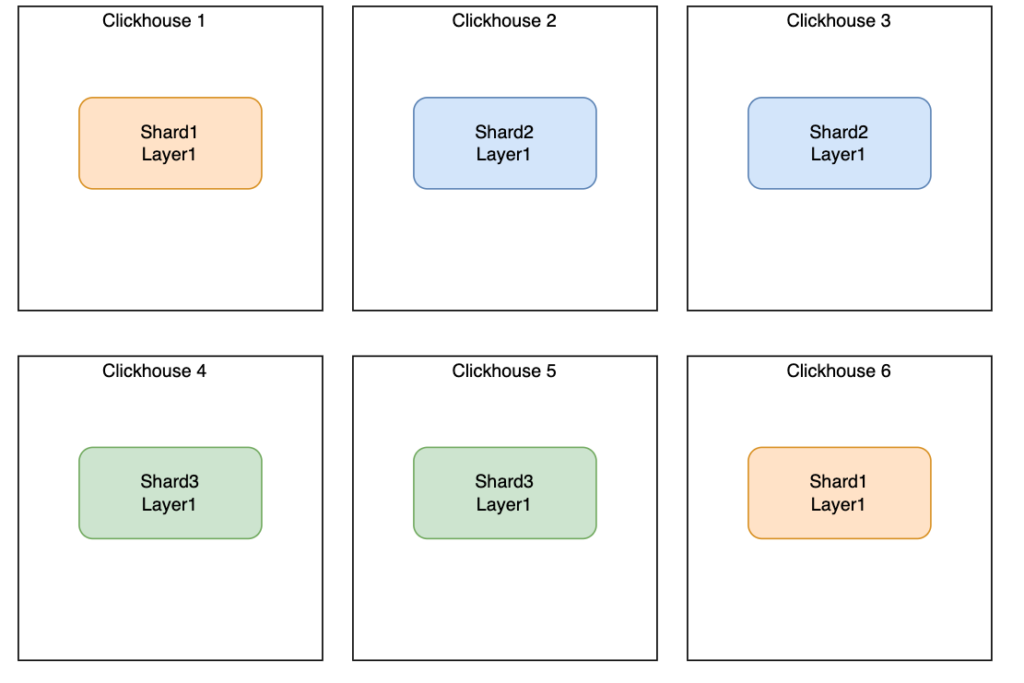
Dans l’exemple précédent, lorsque l’on écrit sur le nœud 1, la donnée sera automatiquement répliquée sur le nœud 6 (il en va de même entre le nœud 2 et 3 ainsi qu’entre le nœud 4 et 6). Nous détaillerons cette partie dans le chapitre Architecture.
Comme évoqué précédemment, ClickHouse supporte un langage “SQL-like” qui inclut la gestion des tableaux, les structures imbriquées, les approximations ou encore les fonctions d’URI. Il est également possible d’interconnecter des systèmes externes de clé/valeur, que nous détaillerons dans la suite de cet article.
ClickHouse est une solution hautement performante qui utilise les calculs vectoriels. Non seulement l’outil stocke les données, mais il les traite par vecteurs (partie de colonne) (cf chapitre Fonctionnement).
Selon des tests de référence menés par ses développeurs, pour les requêtes OLAP, ClickHouse est 100 fois plus rapide que Hive (un SGBD basé sur la technologique Hadoop) ou MySQL.
La solution supporte le traitement parallèle et distribué des requêtes (également pour les requêtes de type JOIN)
La compression des données est également un point fort de la solution puisqu’elle peut traiter un volume de données qui ne tiendrait pas en RAM habituellement. La solution optimise également la gestion des HDD (Hard Disk Drive).
Il existe de nombreuses façons d’interagir avec cette base :
- une CLI
- une API HTTP/HTTPS
- une interface web
- des librairies pour Python, PHP, NodeJs, Perl, Ruby et R
- des drivers ODBC ou JDBC sont également disponibles
Pour finir, la solution est hautement configurable : les paramètres de configuration permettent de changer radicalement le comportement de la base en fonction de vos besoins.
Inconvénients
Actuellement, la base ne supporte pas les transactions, mais la roadmap du produit est encourageante à ce sujet.
Sur cette base, les suppressions et modifications sont très consommatrices et peu recommandées. Initialement, ces fonctionnalités n’existaient pas. Les utilisateurs ont dû attendre 2017 pour en profiter. Cependant, certains “table engines” permettent de palier les problématiques de mise à jour, nous le verrons par la suite.
La modification d’un schéma de table est catastrophique, en partie à cause de Zookeeper (qui devrait disparaitre dans une version future et permettra à la solution de n’être qu’un unique binaire à installer). Une des alternatives est de créer une nouvelle table avec le nouveau schéma et d’en migrer la donnée.
Certaines tâches (notamment d’OPS) restent manuelles comme les backups/restores, le data rebalancing ou encore le resharding.
Actuellement, il n’existe pas d’interface graphique pour un usage BI afin de créer des dashboards pour exploiter la donnée. La plupart des clients développent leur propre alternative ou optent pour solutions éditeurs comme Tibco spotfire (ou Apache Superset en cours de test de notre côté).
Cas d’utilisations
Clickhouse fonctionne au mieux avec :
- Un petit nombre de tables contenant un très grand nombre de colonnes. Les requêtes peuvent utiliser un grand nombre de lignes extraites de la base de données, mais seulement un petit sous-ensemble de colonnes.
- Des requêtes relativement rares (généralement autour de 100 RPS par serveur).
- Des valeurs de colonne assez petites, généralement composées de nombres et de chaînes courtes (par exemple, 60 octets par URL).
- Un résultat de requête principalement filtré ou agrégé.
- Une mise à jour des données utilisant un scénario simple (généralement par lots uniquement, sans transactions compliquées).
L’un des cas les plus courants est l’analyse des journaux serveurs pour répondre aux enjeux suivants de manière efficace :
- l’analyse en temps réel des incidents avec des requêtes instantanées
- La surveillance des métriques d’un service, telles que les taux d’erreur ou les temps de réponse,
ClickHouse recommande l’insertion des données par lots assez volumineux (plus de 1000 lignes)
Vous pouvez également envisager d’utiliser ClickHouse comme entrepôt de données (Data Warehouse)
Stockage et requêtage
Dans ce chapitre, nous allons vous montrer comment Clickhouse fonctionne, comment il stocke ses données de façon à permettre un requêtage des plus efficaces.
Tout d’abord, regardons les méta données que nous pouvons facilement avoir sur une table !
Créons cette table (pour les types nous vous renvoyons à la doc officielle) :
CREATE TABLE hits_UserID_URL
(
`UserID` UInt32,
`URL` String,
`EventTime` DateTime
)
ENGINE = MergeTree
PRIMARY KEY (UserID, URL)
ORDER BY (UserID, URL, EventTime)
SETTINGS index_granularity = 8192; --Chaque groupe de 8192 lignes, l'index aura une entrée, nous y reviendrons par la suite
Insérons des données :
INSERT INTO hits_UserID_URL
SELECT
intHash32(c11::UInt64) AS UserID,
c15 AS URL,
c5 AS EventTime
FROM url('https://datasets.clickhouse.com/hits/tsv/hits_v1.tsv.xz')
WHERE URL != '';
- Ligne 6: nous voyons ici que les données peuvent directement être insérées via une url pointant vers un fichier tsv : “Tab separated values” !!
Regardons les métadatas stockées dans la base system:
SELECT part_type, path, formatReadableQuantity(rows) AS rows, formatReadableSize(data_uncompressed_bytes) AS data_uncompressed_bytes, formatReadableSize(data_compressed_bytes) AS data_compressed_bytes, formatReadableSize(primary_key_bytes_in_memory) AS primary_key_bytes_in_memory, marks, formatReadableSize(bytes_on_disk) AS bytes_on_disk FROM system.parts WHERE (table = 'hits_UserID_URL') AND (active = 1) FORMAT Vertical;
- Ligne 3 : Renvoie le chemin où sont réellement stockées les données
- Ligne 4 : Renvoie le nombre de lignes insérées dans la table
- Ligne 5 : Renvoie la taille des données de la table non compressées
- Ligne 6 : Renvoie la taille des données de la table compressées
- Ligne 7 : Renvoie la taille des données de clé primaire
- Ligne 8 : Renvoie le nombre de marques (nous y reviendrons par la suite)
- Ligne 9 : Renvoie la taille totale de la table sur le disque
part_type: Wide path: ./store/d9f/d9f36a1a-d2e6-46d4-8fb5-ffe9ad0d5aed/all_1_9_2/ rows: 8.87 million data_uncompressed_bytes: 733.28 MiB data_compressed_bytes: 206.94 MiB primary_key_bytes_in_memory: 96.93 KiB marks: 1083 bytes_on_disk: 207.07 MiB
Comment cela fonctionne ?
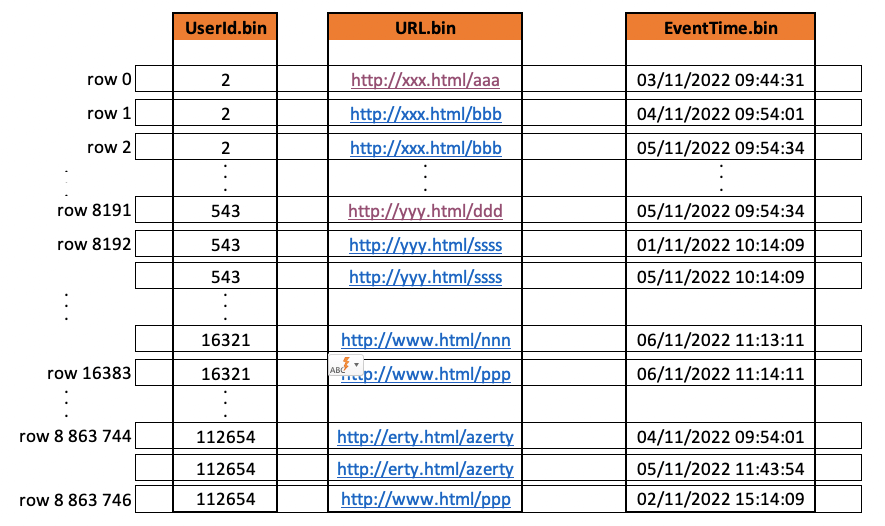
Clickhouse stocke les données sur le disque, triées par clé primaire (PRIMARY KEY) puis par les éléments de la clé de triage (ORDER BY). Si la clé primaire n’est pas spécifiée, elle sera constituée par les éléments de la clé de triage.
Voici comment se stockent les données lors de l’insertion :
Pour traiter la donnée, Clickhouse divise les colonnes en “granule” (compressé), c’est le plus petit dataset indivisible pour traiter les données :
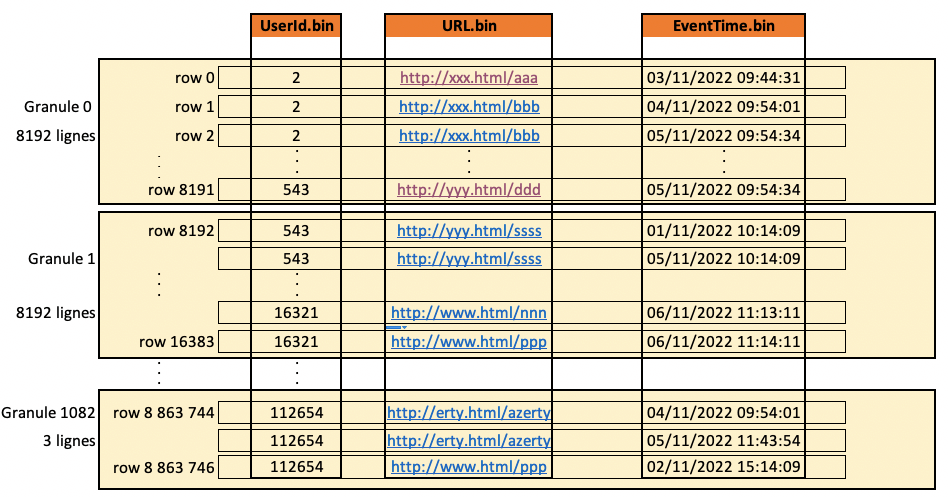
Lors de la création de la table, la propriété SETTINGS index_granularity = 8192; (valeur par défaut) permet de spécifier la taille des granules. Évidement, augmenter ou diminuer cette valeur permet d’influencer les performances des requêtes.
L’index primaire lié à la clé primaire possède une entrée par “granule”, cela constitue les marques. Chaque marque porte les données de la première ligne du granule associé :
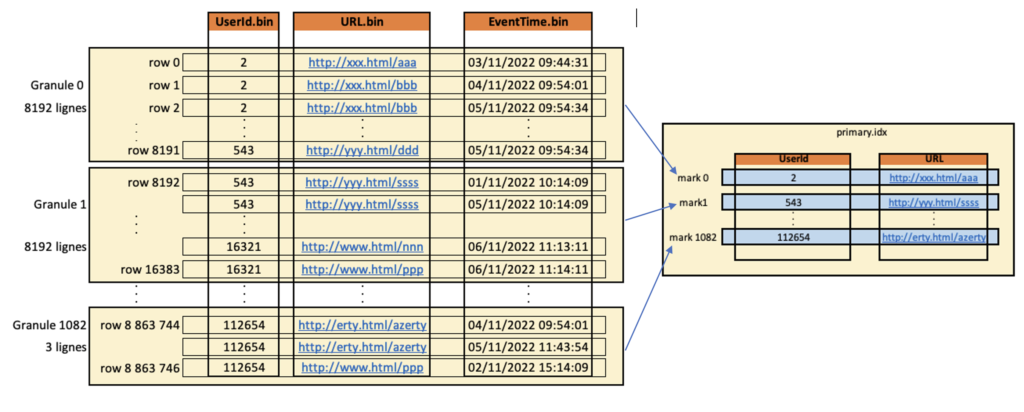
Clickhouse monte en mémoire le fichier d’index primaire (s’il n’y a pas assez de mémoire, Clickhouse remontera une erreur)
Lors d’un select, le fichier d’index permet de savoir dans quel(s) granule(s) se trouvent les données:
EXPLAIN indexes = 1 SELECT URL, count(URL) AS Count FROM hits_UserID_URL WHERE UserID = 854 GROUP BY URL ORDER BY Count DESC LIMIT 10;
...Executor): Key condition: (column 0 in [854, 854]) ...Executor): Running binary search on index range for part all_1_9_2 (1083 marks) ...Executor): Found (LEFT) boundary mark: 1 ...Executor): Found (RIGHT) boundary mark: 2 ...Executor): Found continuous range in 19 steps ...Executor): Selected 1/1 parts by partition key, 1 parts by primary key, 1/1083 marks by primary key, 1 marks to read from 1 ranges ...Reading ...approx. 8192 rows starting from 8192
Expression (Projection)
Limit (preliminary LIMIT (without OFFSET))
Sorting (Sorting for ORDER BY)
Expression (Before ORDER BY)
Aggregating
Expression (Before GROUP BY)
Filter (WHERE)
SettingQuotaAndLimits (Set limit & quota after reading from storage)
ReadFromMergeTree
Indexes:
PrimaryKey
Keys:
UserID
Condition: (UserID in [854, 854])
Parts: 1/1
Granules: 1/1083
Une fois le granule identifié, Clickhouse doit connaitre la localisation physique du granule 1
Un fichier mark stocke toutes les localisations physiques des “granules;” un fichier mark par colonne :
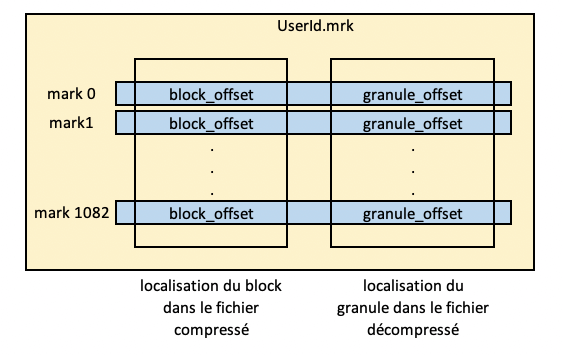
Grâce à ces fichiers mrk, Clickhouse peut localiser le bloc dans le fichier compressé (.bin), il peut donc le décompresser en mémoire puis, grâce au granule_offset, trouver le(s) granule(s) qui correspondent :
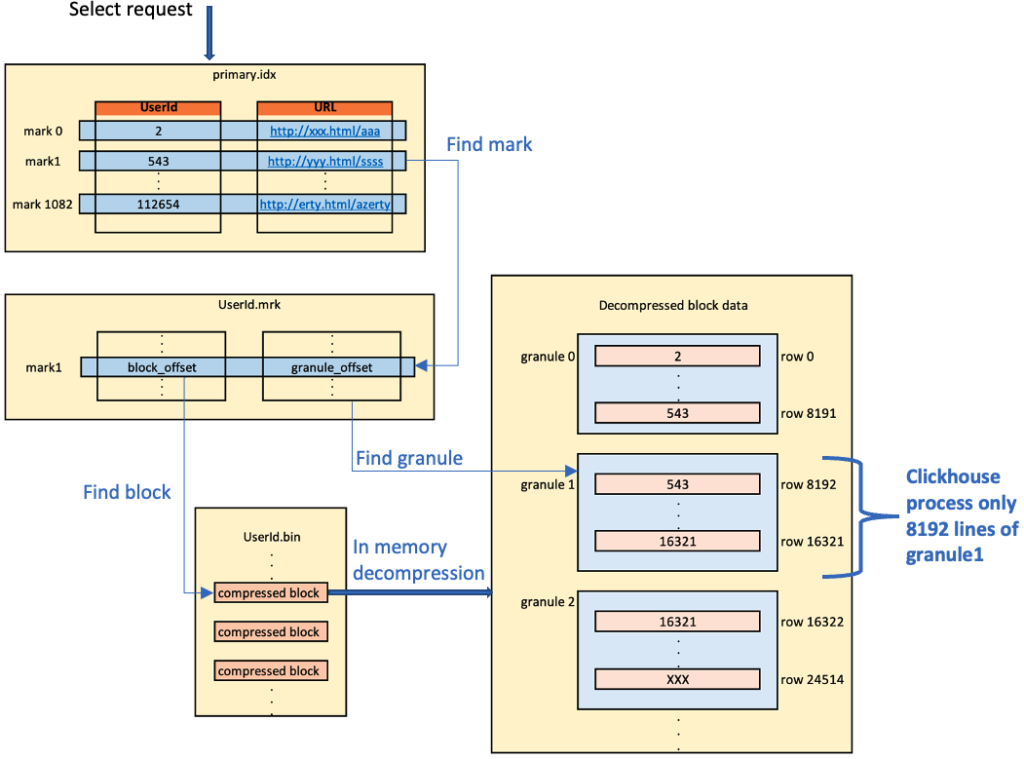
Pour résumer :
- Avec le fichier idx (en mémoire), on trouve le(s) granule(s)/mark(s)
- Avec le fichier mrk, on localise le(s) block(s) compressé(s)
- Clickhouse décompresse le(s) bloc(s) en mémoire
- Avec le fichier mrk, on localise le(s) granule(s) dans le(s) block(s) décompressé(s)
- Seule les données du(des) granule(s) décompressé(s) seront traitées par le moteur Clickhouse
Et au niveau du système de fichier ?
Au niveau du système de fichiers, les données vont être stockées de la façon suivante :
<path_to_data_folder>/<database>/<table>/<partition_key>_W_X_Y_Z/
- W : nombre minimum du bloc de données
- X : nombre maximum du bloc de données
- Y : niveau de fragmentation (profondeur du mergetree à partir duquel il est formé)
- Z : version de la mutation (si mutation il y a eu)
Cela sera plus parlant avec un exemple !
Créons une table et insérons 1 million de lignes :
CREATE TABLE hits_UserID_URL
(
`UserID` UInt32,
`URL` String,
`EventTime` DateTime
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(EventTime)
PRIMARY KEY (UserID, URL)
ORDER BY (UserID, URL, EventTime)
SETTINGS index_granularity = 8192;
INSERT INTO hits_UserID_URL
SELECT
intHash32(c11::UInt64) AS UserID,
c15 AS URL,
c5 AS EventTime
FROM file('https://d3uyj2gj5wa63n.cloudfront.net/xxx/xaa.tsv.xz')
WHERE URL != '';

Clickhouse a bien qu’un seul dossier 201403_1_1_0 qui porte :
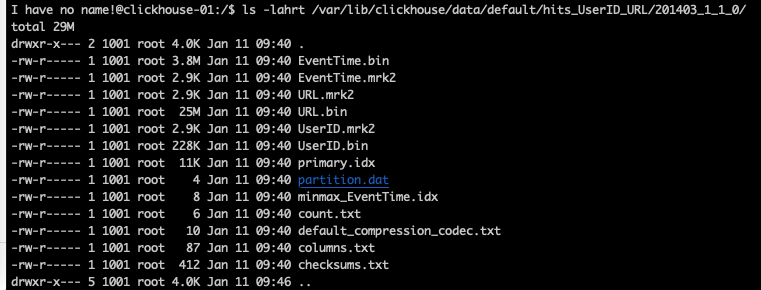
Insérons maintenant 2 millions de lignes :
INSERT INTO hits_UserID_URL
SELECT
intHash32(c11::UInt64) AS UserID,
c15 AS URL,
c5 AS EventTime
FROM file('https://d3uyj2gj5wa63n.cloudfront.net/xxx/xab.tsv.xz')
WHERE URL != '';
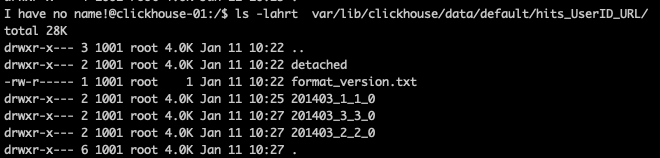
Clickhouse a maintenant créé 2 autres dossiers :
201403_2_2_0pour le deuxième bloc de données201403_3_3_0pour le troisième bloc de données
Chaque bloc contient max_insert_block_size de ligne (1 048 576 par défaut).
Le processus d’agrégation des fichiers passent en arrière-plan de façon asynchrone, mais il est possible de le forcer avec une requête OPTIMIZE
OPTIMIZE table hits_UserID_URL
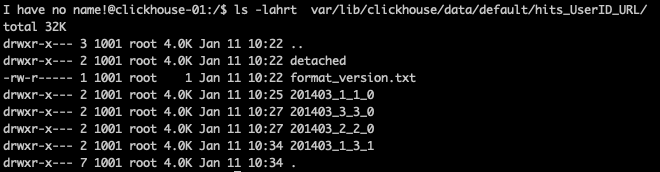
Clickhouse a créé une part/dossier 201403_1_3_1. Ce dossier porte donc les blocs de données 1, 2 et 3. Il a un niveau de fragmentation de 1.
Regardons les informations sur les parts de la base système :
SELECT * from system.parts where partition = '201403'

Nous voyons ici :
- Seule la part
201403_1_3_1est active - La part
201403_1_3_1a bien le nombre demarksde la somme desmarksdes autrespartsinactives - La part
201403_1_3_1a bien le nombre de lignes de la somme des lignes des autrespartsinactives - En revanche, pour les tailles sur disques de la
part201403_1_3_1, nous sommes très loin de la somme des tailles des autrespartsinactives !
Après quelques minutes et le passage d’un “nettoyeur”, les parts inactives vont être supprimées !

Architecture
Avec Clickhouse, il est facilement possible de créer des clusters.
Cluster sur 3 nœuds, 1 shard répliqué 2 fois
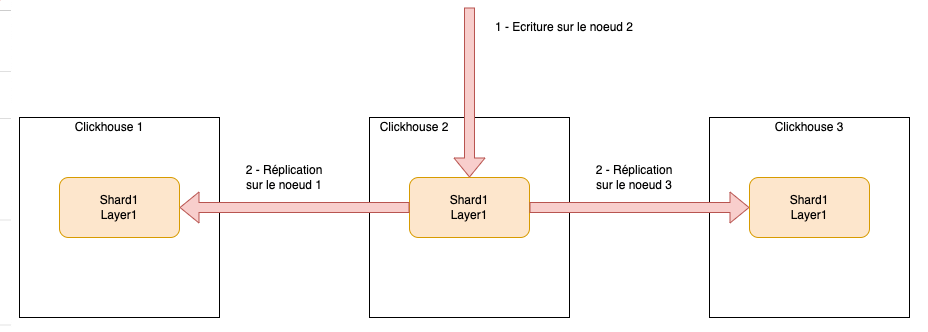
Dans cet exemple, peu importe sur quel nœud nous écrivons, la donnée sera automatiquement répliquée sur les 2 autres nœuds. De même pour le requêtage, peu importe le nœud requêté, il portera l’ensemble des données.
Cluster sur 6 nœuds, 3 shard répliqué 1 fois
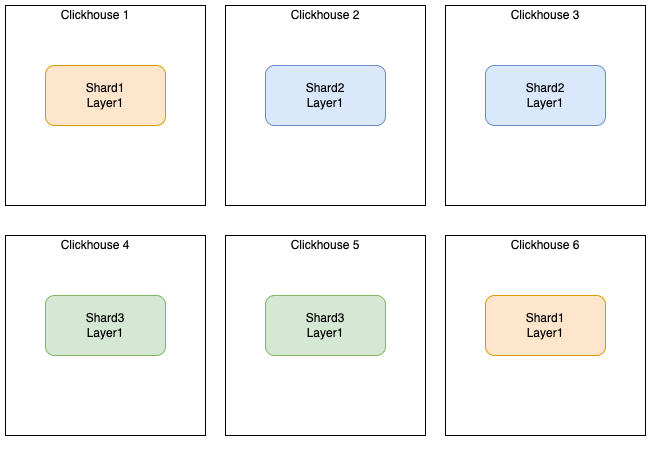
Dans cet exemple, il y a une réplication entre :
- le nœud 1 et 6
- le nœud 2 et 3
- le nœud 4 et 5
Lors de la création d’une table, si vous souhaitez que cette table soit créée sur tous les nœuds, il est nécessaire de spécifier l’instruction ON CLUSTER
CREATE TABLE ttt ON CLUSTER cluster_1(
id Int32,
data varchar
)
ENGINE = ReplicatedMergeTree('/clickhouse/tables/{layer}-{shard}/ttt', '{replica}') PARTITION BY id ORDER BY (id, data)
Lors du requêtage, si vous interrogez un nœud en particulier, vous n’aurez que les données du shard affectées au nœud… Cela peut avoir du sens si la répartition des données entre les shards suit une logique métier et que vous ne souhaitez avoir que les données d’un shard donné, mais dans la majorité des cas, on souhaite interroger l’ensemble des shards. Pour faire cela, il est nécessaire d’utiliser une DISTRIBUTED TABLE
CREATE TABLE ttt_all ON CLUSTER cluster_1 as ttt ENGINE = Distributed(cluster_1, default, ttt, rand())
Ici, nous créons une table distribuée sur tous les nœuds du cluster (ON CLUSTER). Cette table se connecte à la table ttt de la base de donnée default du cluster_1. La clé de répartition des données entre les shards est une fonction aléatoire : rand()
Quand on écrit sur cette table distribuée, il nous est impossible de savoir sur quel shard va être affectée la donnée, car la clé de répartition est aléatoire. (Nous aurions très bien pu mettre une clé de répartition “métier” afin de répartir logiquement les données entre les shard)
Quand nous requêtons la table ttt via sa table distribuée ttt_all, nous aurons les données de tous les shards. La table distribuée va agréger les données des différents shards.
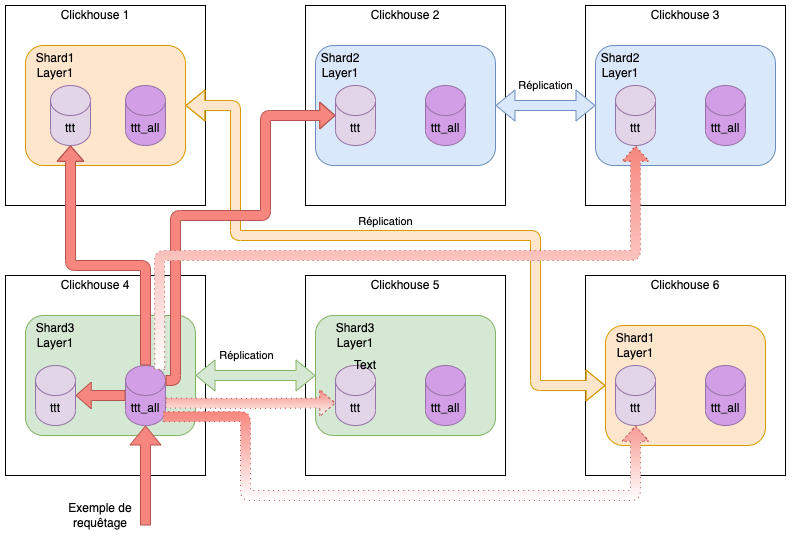
2 clusters sur 6 nœuds
Il est également possible de créer plusieurs clusters différents sur une même infrastructure :
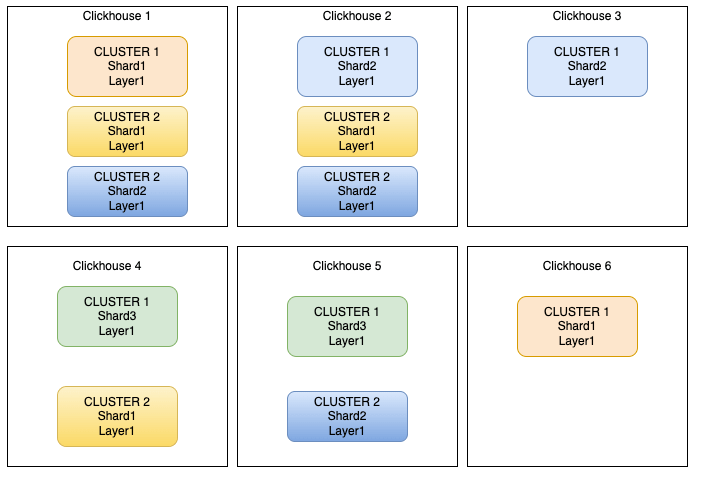
Ici, pour l’exemple, nous avons :
- Cluster 1
- Cluster sur 6 nœuds
- 3 shards répliqués une fois
- shard 1 sur les noeuds 1 et 6
- shard 2 sur les noeuds 2 et 3
- shard 3 sur les nœuds 4 et 5
- Cluster 2
- Cluster sur 4 nœuds
- 2 shard répliqués 2 fois
- shard 1 sur les nœuds 1, 2 et 3
- shard 2 sur les nœuds 1, 2 et 4
Conclusion
Nous l’avons vu, Clickhouse est une base de donnée colonne, puissante, fiable et résiliante.
Nous vous présenterons certaines de ses fonctionnalités dans un autre article. En attendant, je vous invite à aller consulter la documentation pour vous rendre compte plus précisément de l’ensemble de ses capacités.
Nous retrouvons, dans la roadmap de Clickhouse, pour ne citer que cela, la suppression de zookeeper pour la gestion des clusters (Clickhouse ne sera plus qu’un binaire autonome) ainsi que le support des transactions.
Pour résumer de façon simpliste, cette base est à utiliser si vous :
- Manipulez des données immuables ou presque (IOT, monitoring, reporting, …)
- Avez des très gros volumes de données qui se stockent dans de nombreuses colonnes
Ne pas l’utiliser si vous :
- Devez réaliser de nombreuses mis à jour de vos données (
UPDATE) - Avez des petites requêtes sur peu de ligne
- Souhaitez faire de l’indexation full-text
Vous trouverez certainement des articles où des entreprises ont, par exemple, en migrant d’Elasticsearch/OpenSearch à Clickhouse, réduit considérablement leurs coûts et ont fortement augmenter leur capacité de stockage et de requêtage.
Cependant, je pense qu’il faut faire attention à ces analyses. Il faut utiliser les outils pour ce qu’ils savent faire de mieux !
Dans le cas précédent, ElasticSearch et Clickhouse ne répondent pas aux mêmes problématiques. Elasticsearch est un moteur d’indexation (idéal pour faire de l’analyse full-text ) alors que Clickhouse est une base de donnée colonnes (idéale pour du DWH, reporting…).
Nous ne connaissions pas ce produit il y a quelques mois, mais l’étudier et l’utiliser nous a vraiment étonnés par l’ensemble de ses capacités, fonctionnalités et performances.
Sources
- https://clickhouse.com/docs/en/home/
- https://kb.altinity.com/
- https://www.youtube.com/results?search_query=altinity
- https://engineering.contentsquare.com/
Série d’articles Clickhouse
- Partie 1 : Vous le consultez actuellement
- Partie 2 : Clickhouse, les engines
- Partie 3 : Clickhouse, focus sur certaines fonctionnalités

