
Si vous avez déjà mis en place des tests end 2 end pour vos APIs (synchrone ou asynchrone), vous n’êtes pas sans savoir que cela peut se révéler coûteux voire complexe (mise en place de votre socle technique, implémentations des cas de tests, maintenance, complexité du code, etc)
La promesse de Zerocode est de faciliter cette mise en œuvre sans produire de code, ou presque.
Adapté pour un écosystème java
Zerocode est un projet opensource méconnu qui propose une approche déclarative de vos scénarios de tests et s’occupe pour vous d’exécuter le code source adapté pour communiquer avec vos APIs.
Zerocode est développé en java et s’appuie sur Junit 4 pour l’exécution des tests. Le framework supporte néanmoins JUnit5 au travers de sa dépendance zerocode-tdd-jupiter.
Le framework permet de tester notamment des API REST, SOAP ou des flux Kafka.
Sa documentation, parfois éparse, propose un chapitre Getting Started afin de vous aider à écrire rapidement votre premier test. Si vous avez des questions ou des blocages, sachez que la communauté saura vous aider sur le slack dédié au framework.
Assurez-la non-régression de nos échanges Kafka
La raison pour laquelle j’ai commencé à m’intéresser à ce framework est le use-case de mon projet actuel.
Le produit sur lequel je travaille (stack Java / Maven / Spring / Kafka avec AVRO schema) consomme des messages (fiches produit) Kafka, et, à partir du message reçu, doit appliquer de nombreuses règles de gestion pour produire une réponse en retour (prix de cession de ce produit après un parcours supply complexe).
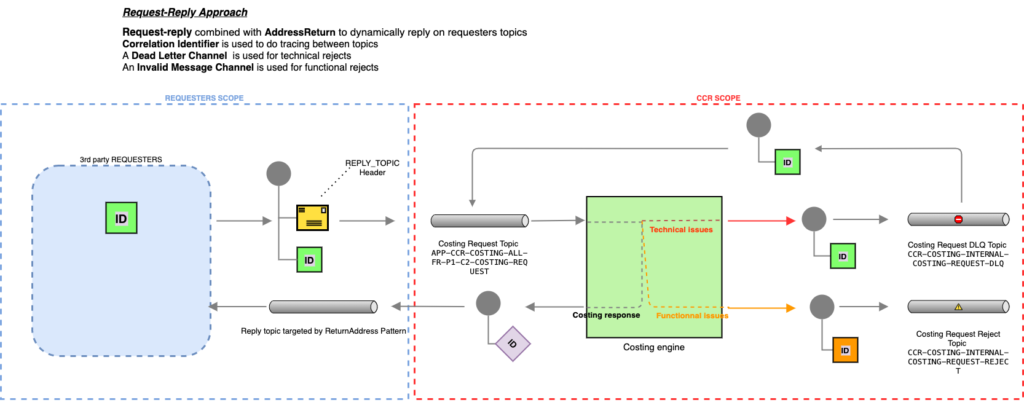
Mon idée dans la mise en place des tests end2end était de simuler des envois de messages en conditions réelles afin de m’assurer que mon composant costing engine produise les réponses attendues et que les évolutions de ce composant au fil du temps n’engendrent pas de régressions fonctionnelles.
De plus, je souhaitais trouver un moyen peu coûteux de produire des tests e2e (pas ou peu de développement à produire, maintenance facilité, pas de complexité, pas de dette technique, etc)
Voici quelqu’un des scenarios que je souhaitais tester :
- Une fiche produit complète et conforme génère correctement un message au demandeur initial avec le prix de cession du produit
- Une fiche produit complète, mais non conforme (données qui ne respectent pas nos règles de gestion) génère un message d’erreur fonctionnelle
- Une erreur technique survenue pendant le traitement génère un message d’erreur technique
- Une fiche produit complète et conforme, provoquant des calculs de taux de change, génère un message contenant le détail des taux de changes appliqués.
- Etc
En résumé, la moindre évolution de ce composant devrait donner naissance à un nouveau scenario e2e.
En quoi Zerocode fut le candidat idéal ?
- Une stack technique similaire à la nôtre : Java / Junit / Kafka / Maven
- Un framework basé sur
jUnitqui nous permet donc de bénéficier des capacités de ce dernier et de son intégration avec des outils comme Maven (un simplemvn verifysuffit à déclencher le lancement des tests) - Le support de Kafka, forcément, avec la possibilité de produire et/ou consommer des messages
- La possibilité d’externaliser le paramétrage de lancement des tests, mais aussi le contenu des scénarios ; indispensable dans un contexte d’entreprise (paramétrage par environnement, injection des informations de connexion depuis un secrets manager, etc)
- Et surtout, la définition des scénarios de manière déclarative via des fichiers
JSONouYAML; facile, et très pratique en termes de productivité et de maintenance.
Mais alors, comment mettre en œuvre un scenario Zerocode adapté à notre contexte ?
Je vous invite à parcourir la documentation concernant le testing Kafka
Dans notre cas, nous devons
- Produire un message dans le topic écouté par notre composant, avec la donnée censée provoquer le comportement que nous souhaitons tester
- Consommer le message produit par notre composant dans un topic de retour et y définir les assertions permettant de valider notre scénario.
Nos scenarios (fichiers déclaratifs) contiendront donc deux steps et seront associés à un test java grâce à l’annotation JsonTestCase.
Voici une version très simplifiée du contenu de nos scenarios mettant en avant des fonctionnalités intéressantes de Zerocode :
{
"scenarioName":"Produce a message with headers to a Kafka topic",
"steps":[
{
"name":"produce_to_kafka",
"url":"kafka-topic:${SYSTEM.ENV:CCR_CONSUMER_TOPIC},
"operation":"PRODUCE",
"request":{
"recordType":"JSON",
"records":[
{
"key":101,
"value":{
"SupplierCode":"1101756001",
"SupplierPrice": 4.07
},
"headers":{
"REPLY_TOPIC": "${SYSTEM.ENV:REPLY_TOPIC}",
"REQUEST_ID": "ineat_zerocode_scenario"
}
}
]
},
"assertions":{
"status":"Ok",
"recordMetadata":"$NOT.NULL"
}
},
{
"name":"consume_from_kafka",
"url":"kafka-topic:${SYSTEM.ENV:REPLY_TOPIC}",
"operation":"consume",
"request":{
"consumerLocalConfigs":{
"recordType":"JSON",
"commitSync":true,
"maxNoOfRetryPollsOrTimeouts":3
}
},
"validators": [
{
"field": "$.records[?(@.headers.CORRELATION_ID == 'ineat_zerocode_scenario')]",
"value": [
{
"value": {
"CostingErrors.SIZE": "$EQ.0",
"CostingResult": "$NOT.NULL",
"CostingResult.CalculationPrice" :"$CUSTOM.ASSERT:com.ineat.zerocode.validation.utils.CcrNumberComparator#isBetween:{\"min\":0.60, \"max\": 1.79}",
"CostingResult.CalculationDetails.SIZE": "$GT.0",
"CostingResult.ExchangeRate" : [ "$CONTAINS.STRING:USD-EUR", "$CONTAINS.STRING:CNY-EUR" ],
"CostingResult.CalculationDetails[?(@.Code=='ECO_CONTRIBUTION_VALUE' && @.Value == '1')].SIZE": 1
}
}
]
}
]
}
]
}
@TargetEnv("kafka_servers/kafka_test_server.properties")
@RunWith(ZeroCodeUnitRunner.class)
public class IneatZerocodeTest {
@Test
@JsonTestCase("kafka/ineat_zerocode.json")
public void testProduce() throws Exception {
// No code needed here.
}
}
# =-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=
# kafka bootstrap servers comma separated
# e.g. localhost:9092,host2:9093
# =-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=
kafka.bootstrap.servers=${SYSTEM.ENV:BROKER_URL}
kafka.producer.properties=kafka_servers/kafka_producer.properties
kafka.consumer.properties=kafka_servers/kafka_season_consumer.properties
# --------------------------------------------------------------------
# Optional local consumer properties common/central to all test cases.
# These can be overwritten by the tests locally.
# --------------------------------------------------------------------
consumer.commitSync=true
# If this property is set to true, all records are shown in the response.
# When dealing with large number of records, you might not be interested
# in the individual records, but interested in the recordCount
# i.e. total number of records consumed
consumer.showRecordsConsumed=false
# That means if any record(s) are read, then this counter is reset to 0(zero) and the consumer
# polls again. So if no records are fetched for a specific poll interval, then the consumer
# gives a retry retrying until this max number polls/reties reached.
consumer.maxNoOfRetryPollsOrTimeouts = 1
# Polling time in milli seconds i.e how long the consumer should poll before
# the next retry poll
# Polling time in milli seconds i.e how long the consumer should poll before
# the next retry poll
consumer.pollingTime = 3000
Entrons dans le détail du contenu du fichier de scenario ineat_zerocode.yaml :
Lignes 6 à 7
La première étape consiste à produire (produce) un message dans le topic ciblé par la variable d’environnement CCR_CONSUMER_TOPIC.
Vous pouvez injecter des variables externes dans vos scenarios ou vos fichiers de configurations.
https://github.com/authorjapps/zerocode/wiki/Reading-System-Properties-and-Environment-Variables-in-Zerocode-Test-Steps
Lignes 11 à 23
La propriété records permet de définir le contenu des messages Kafka à produire, au format JSON.
Dans cet exemple, nous utilisons deux headers techniques qui vont permettre à notre composant de produire sa réponse :
- Le header
REPLY_TOPICpermet d’appliquer le pattern REQUEST-REPLY. Cela permet de communiquer avec n’importe qui en lui demandant sur quel topic nous devons lui répondre.- Nous n’avons ainsi pas besoin de gérer le cycle de vie des topics de retour ; c’est à la charge de nos demandeurs
- cela nous permet également, dans le cadre des tests e2e, de pouvoir envoyer les réponses dans un topic dédié, qui sera utilisé dans l’étape suivante du scenario !
- Le header
REQUEST_IDpermet d’appliquer le pattern Correlation Identifier- le message de retour contiendra un header
CORRELATION_IDavec ce même identifiant pour permettre d’associer la requête envoyée à la réponse produite.
- le message de retour contiendra un header
Lignes 31 à 32
Cette étape permet de consommer (consume) un message en provenance du topic ciblé par la variable d’environnement REPLY_TOPIC.
Si vous avez suivi, le message produit demande à notre composant de répondre sur le topic ciblé par cette même variable d’environnement
Ligne 40
Zerocode fournit deux approches pour valider un message, les
https://github.com/authorjapps/zerocode/wiki/Validators-and-Matchersvalidatorsou lesmatchers.
Nous utilisons les capacités des validators pour ne vérifier que le contenu du message qui nous intéresse.
En effet, dans un monde événementiel, de nombreux messages peuvent arriver dans le topic durant la phase de test. Il est donc important que le scenario valide les assertions sur le message adapté.
La ligne 42 (“field”: “$.records[?(@.headers.CORRELATION_ID == ‘ineat_zerocode_scenario’)]”) permet de ne traiter que le message reçu ayant un header CORRELATION_ID égal àineat_zerocode_scenario.
Zerocode supporte les capacités de JSONPath dans ses assertions. Nous utilisons d’ailleurs cette capacité pour valider la présence d’une valeur dans un tableau (ligne 51)
https://github.com/authorjapps/zerocode/wiki/When-JSON-Path-Matching-returns-value-or-values-as-an-array
Lignes 45 à 52
Zerocode fournit un bon nombre de tokens et de matchers que vous pouvez utiliser dans vos scénarios.
- Les tokens permettent de générer ou récupérer de la donnée dans vos scénarios et fichiers de configurations
- Les matchers permettent de comparer les valeurs des champs que vous voulez tester
- Vous pouvez également créer vos propres matchers en vous basant sur ces exemples (comme le démontre la ligne 48)
- Enfin, la ligne 51 démontre comment valider la valeur d’un champ dans une structure poussée (type tableau d’objets, etc) grâce à JSONPath. Comme JSONPath returnera toujours des tableaux avec les éléments trouvés, il est nécessaire d’utiliser
.SIZE(voir ici) de Zerocode pour valider que le tableau contient un match.
Je vous conseille d’abord décrire votre filtre via un outil en ligne comme https://jsonpath.com/.
Essayez avec le filtre
https://jsonpath.com/$.phoneNumbers[?(@.type=='iPhone' && @.number == '0123-4567-8888')]par exemple.
Envie d’essayer ?
Le projet hello-kafka-stream-testing contient bon nombre de scenarios avec la possibilité de lancer rapidement kafka en local pour commencer à s’amuser.
Un projet équivalent existe également pour la partie APIs synchrones.
Le support de Kafka, mais sans AVRO
Si vous utilisez Kafka dans un contexte d’entreprise, vous utilisez peut-être AVRO pour gérer vos schémas de message.
Zerocode ne supporte pas l’écriture de scénario qui PUBLIENT des messages qui se basent sur des schémas AVRO (fichiers AVSC) mais cela fonctionne pour la consommation de topics contenant des messages en AVRO.
Vous pouvez néanmoins vous en sortir en surchargeant la classe BasicKafkaClient du framework.
Nous mettons ce Gist à votre disposition qui répond à cette problématique.
https://gist.github.com/M3lkior/aa4f2b21a46f2d45c84b09b5b0331930
Tips & tricks
- N’hésitez pas à mettre une rétention des messages faibles (5 minutes par exemple) sur vos topics e2e afin qu’ils soient vidés entre deux lancements de vos tests
- Définissez du retry/pollingTime sur vos scénarios pour laisser le temps aux messages d’arriver en mode CONSUME
- Exploitez le rapport html généré par Zerocode (allez voir dans votre dossier target ;)) pour faciliter l’analyse de vos résultats. Vous pouvez également exposer ce rapport sur un GhPages afin de pouvoir le partager avec votre équipe
- Rejoignez le slack de Zerocode si vous avez des questions

