
Google est une des références en ce qui concerne le machine learning. Dans un précédent article, je vous présentais une de leurs solutions : Teachable Machine qui permet de créer des modèles de classification d’images, de sons ou de postures sans coder ! Les entraînements sont effectués localement, les données doivent être stockées sur votre machine ou sur un drive. Cette solution est idéale pour prototyper à moindre coût ou pour effectuer un projet DIY, mais existe-t-il une solution équivalente industrialisée ?
Aujourd’hui, nous allons donc parler d’AutoML Vision. Cette solution intégrée à Google Cloud Platform est similaire à Teachable Machine ; c’est-à-dire qu’elle permet de créer un modèle sans coder ! Cette solution est uniquement centrée sur la reconnaissance d’images. Pour l’entraînement, vous bénéficiez de la puissance des machines mises à disposition par GCP. En effet, la plateforme contient des infrastructures spécialisées pour l’entraînement (GPU) et pour effectuer de la prédiction (TPU). Pas d’inquiétude, je reviendrais sur ces points un peu plus tard.
Il existe plusieurs déclinaisons de la solution AutoML :
- AutoML Natural Language : catégorisation du texte, des intentions, des sentiments
- AutoML Tables : effectuer de la prédiction sur des données
- AutoML Translation : traduction personnalisée
- AutoML Video Intelligence : catégorisation des paysages, plans, recherche d’objets dans des vidéos
- AutoML Vision catégorisation des images
C’est sur cette dernière déclinaison que la création de notre modèle de reconnaissance sera effectuée.
Création du dataset
Afin de comprendre le fonctionnement, nous allons utiliser l’interface graphique.
Sachez-que la préparation des données est également disponible avec la commande gsutil afin de déposer les fichiers sur Cloud Storage.
La première étape consiste à créer un projet dans GCP, puis de sélectionner Vision dans la catégorie Intelligence artificielle du menu latéral gauche :
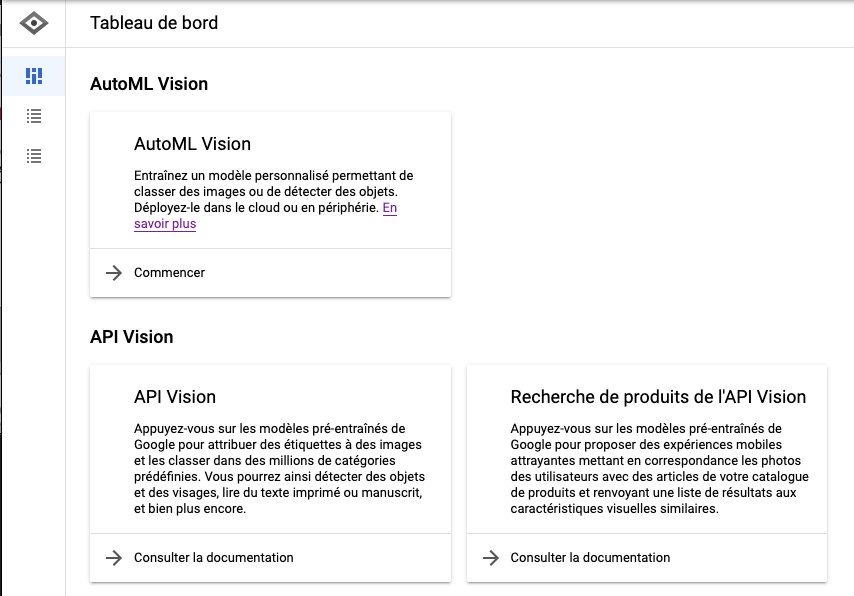
Un tableau de bord va alors apparaître avec deux catégories distinctes :
- AutoML Vision : pour créer des datasets, entraîner vos modèles, puis les exporter et/ou les déployer
- API Vision : pour utiliser l’API Google existante avec des modèles qui se mettent constamment à jour
Dans notre cas, nous souhaitons faire un modèle sur-mesure c’est-à-dire : détecter quelques personnages d’un manga de mon enfance Dragon Ball (comme dans l’article précédemment avec Teachable Machine).
Pour commencer un modèle personnalisé, cliquer sur le bouton Commencer pour créer votre premier dataset (ensemble de données) :
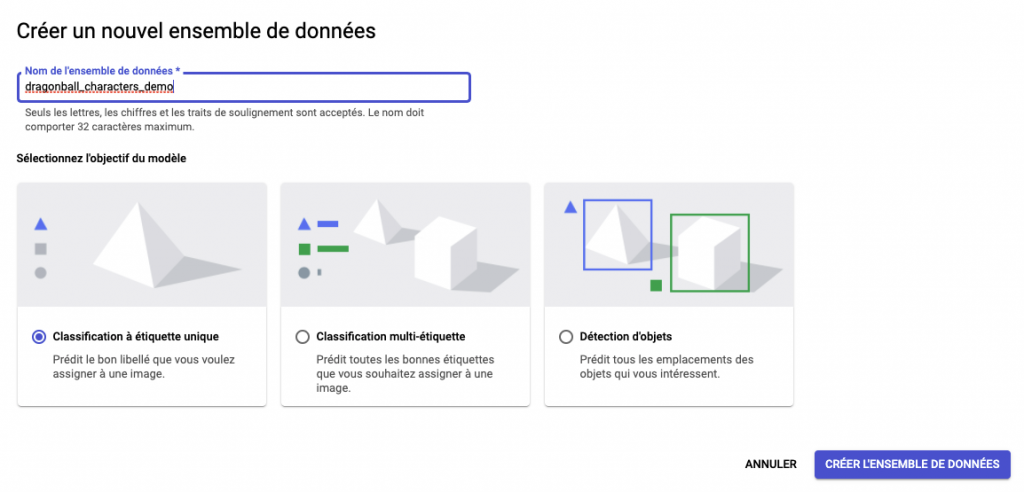
Lors de la création plusieurs choix sont possibles :
- Classification à étiquette unique
- Classification multi-étiquette
- Détection d’objects
Ce choix s’effectue selon le type de modèle dont vous aurez besoin. Dans mon cas, je souhaite détecter et classifier un seul personnage par image. Je vais donc sélectionner Classification à étiquette unique :
C’est ici que tout commence, l’enrichissement du dataset ! Cliquer sur le bouton créer l’ensemble de données.
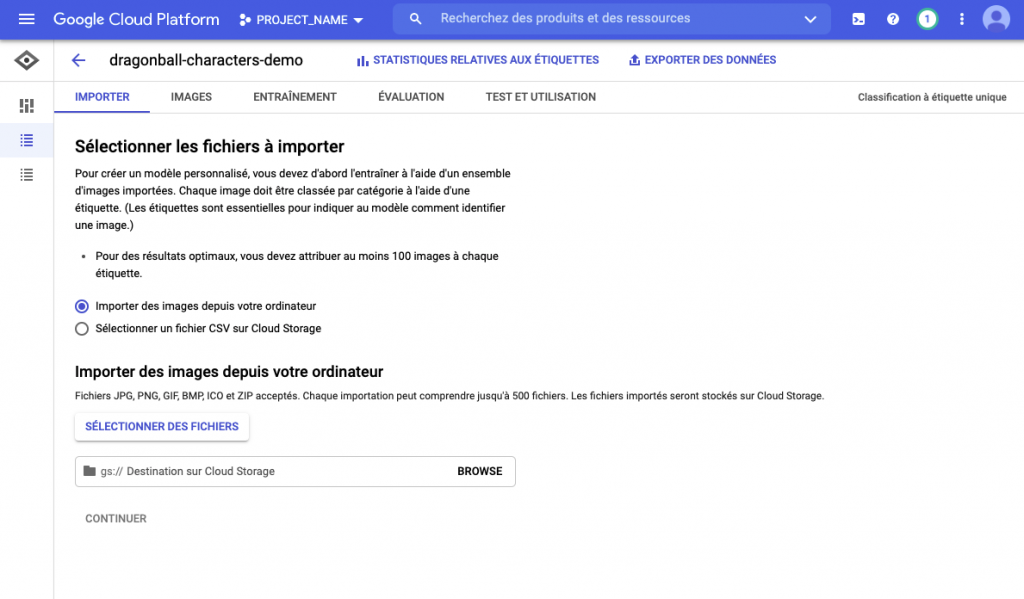
L’interface ci-dessus nous indique qu’un minimum de 100 images est recommandé par étiquette. Une étiquette est en réalité une classe pour notre classification. Selon le type de modèle, vous aurez la possibilité d’en appliquer une ou plusieurs par image.
Cette étape est très importante, car il faut fournir suffisamment de données pour que l’entraînement soit efficace. N’hésitez-pas à consulter le site Kaggle pour enrichir votre dataset.
Dans mon cas, une de mes étiquettes (classes) ne contient pas assez d’images et j’ai donc perdu en précision sur mon modèle à cause de ce manque de données. Cependant AutoML a l’avantage de pouvoir très facilement ré-entraîner son modèle par la suite.
Il est temps d’importer vos images, selon la quantité de données cela peut être fastidieux 🥺 . Sélectionner un lieu de destination dans Cloud Storage créé pour l’occasion.
Pour l’importation, je vous conseille de transférer vos images par type d’étiquette. L’interface permet de sélectionner toutes les images sans étiquette, puis d’appliquer une étiquette sur l’ensemble des images sélectionnées. Bien pratique lorsqu’on a des milliers d’images à étiqueter 😆.
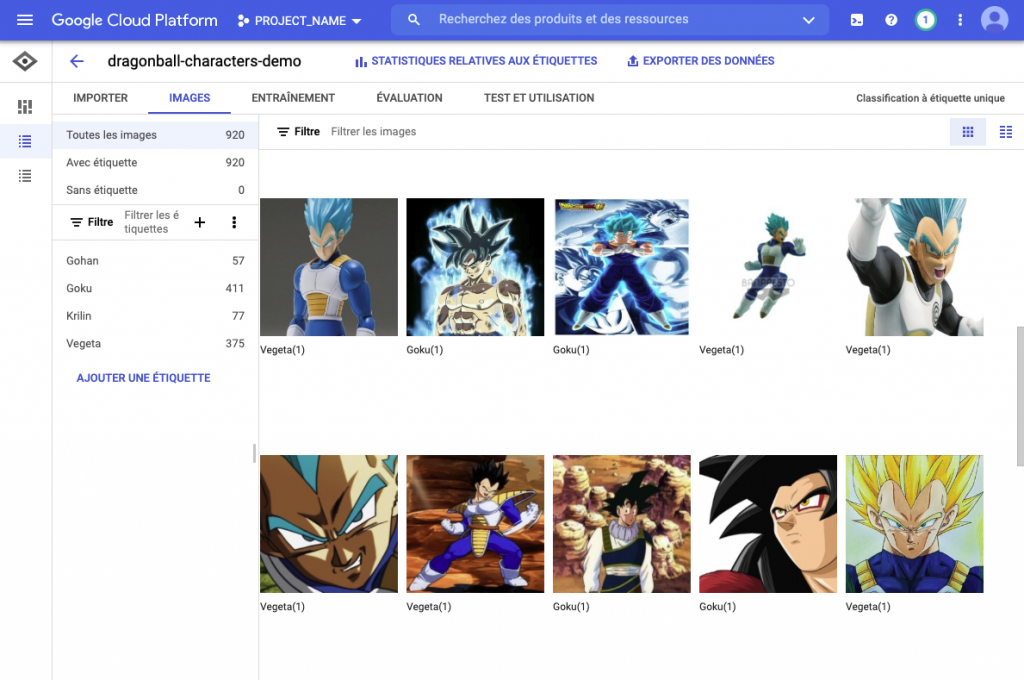
Ci-dessus constatez-que que l’on retrouve la liste des étiquettes à gauche puis la liste des images avec le(s) étiquette(s) affectée(s) à droite.
Le bouton exporter des données permet d’exporter les images et un CSV pour pouvoir ré-importer votre dataset dans un nouveau dataset.
Maintenant que le dataset est prêt, le modèle est prêt à être entrainé.
Entraînement du modèle
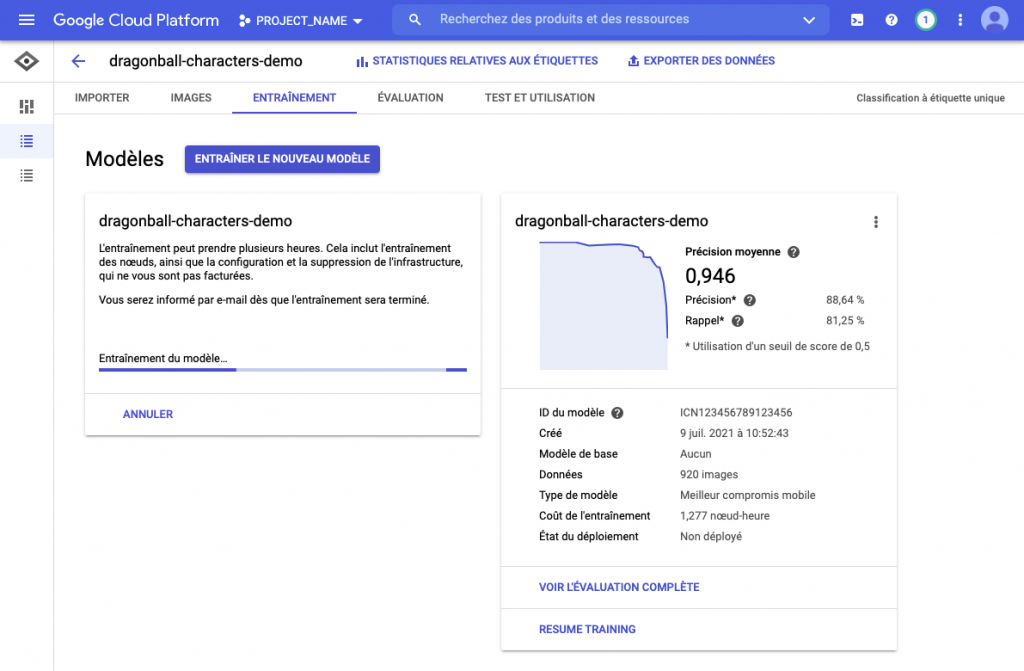
L’onglet entraînement permet de récupérer un récapitulatif des modèles précédemment entraînés avec leurs précisions, coûts nœud-heure, états [non]-déployés) et d’effectuer un nouvel entraînement.
Pour commencer un entraînement, cliquer sur le bouton entraîner le nouveau modèle :
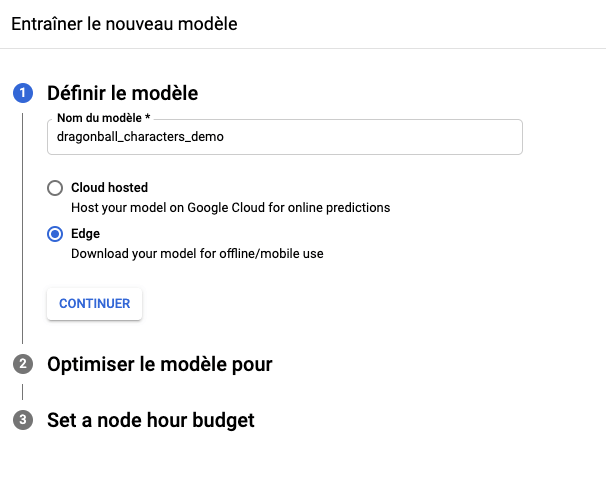
Un menu latéral droit va apparaître pour permettre de configurer plusieurs informations :
- Nom du modèle
- hébergé ou non le modèle (Edge s’il est embarqué sur mobile)
- Choisir l’optimisation du modèle et par conséquent son poids. Pour rappel plus un modèle est léger moins il est précis.
- Définir le budget alloué pour l’entraînement (nombre de nœuds par heure)

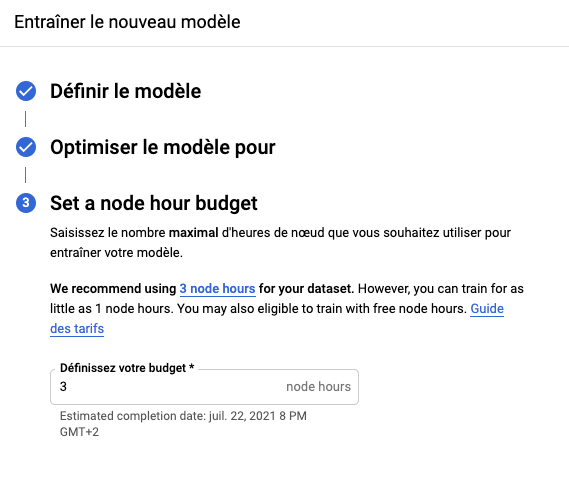
Après plusieurs heures d’entraînement (2 heures et 30 minutes dans mon cas) le modèle est prêt à être exploité. Voici une petite estimation du budget en heures de nœud indiqué dans la documentation selon la quantité d’images :
- < 500 images : 1 heure
- 500 images : 2 heures
- 1000 images : 3 heures
- 5000 images : 6 heures
- 10 000 images : 7 heures
- 50 000 images : 11 heures
- 100 000 images : 13 heures
- 1 000 000 images : 18 heures
Il se peut que le modèle soit optimisé plus tôt que prévu, dans ce cas l’entraînement s’arrête avant le temps estimé. Cela évite une formation inutile, car la précision n’évolue plus, mais aussi une surfacturation.
L’onglet évaluation permet d’avoir une visualisation des données : la précision et le rappel. Ici le modèle a une précision de 88.64% et un rappel de 81.25%.
Petite précision sur les deux valeurs :
- Précision : plus elle est élevée moins il y a de faux négatifs
- Rappel : plus elle est élevée moins il y a de faux positifs
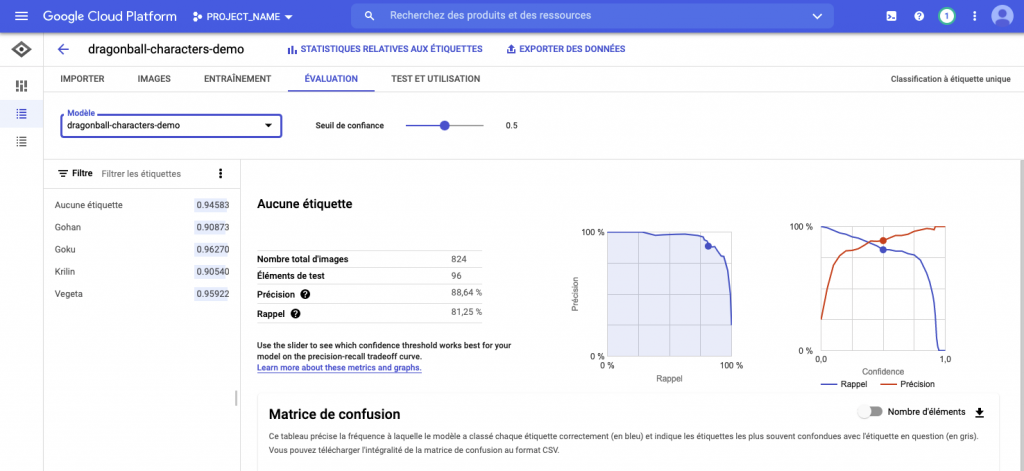
Les différents graphiques, ainsi que la matrice de confusion permettent de vérifier la véracité du modèle. Si le modèle vous convient, celui-ci peut-être exporté dans différents formats :
- TF lite (mobile, raspberry, …)
- Tensorflow.js (front web)
- CoreML (format .mlmodel spécifique sur iOS, macOS)
- Container (format .pb qui peut être monté dans un conteneur spécialisé exposant une API REST)
- Coral
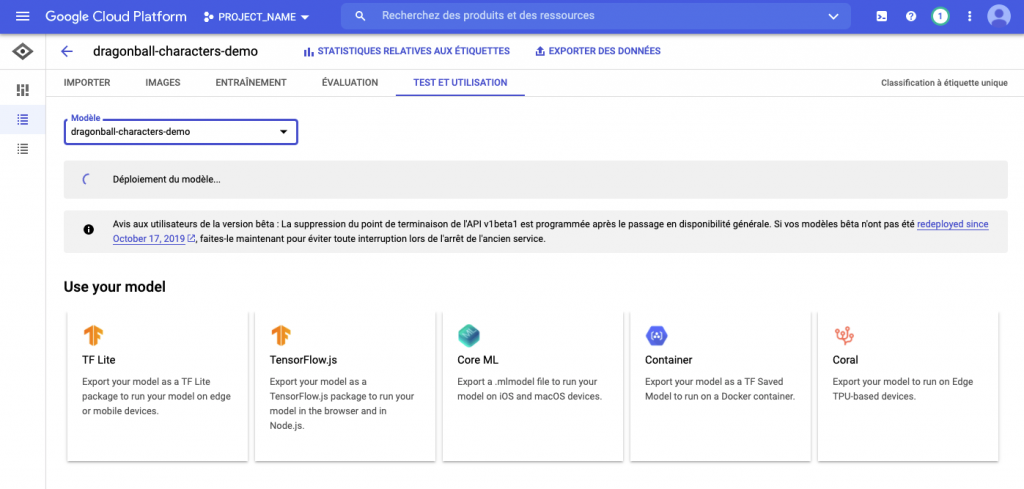
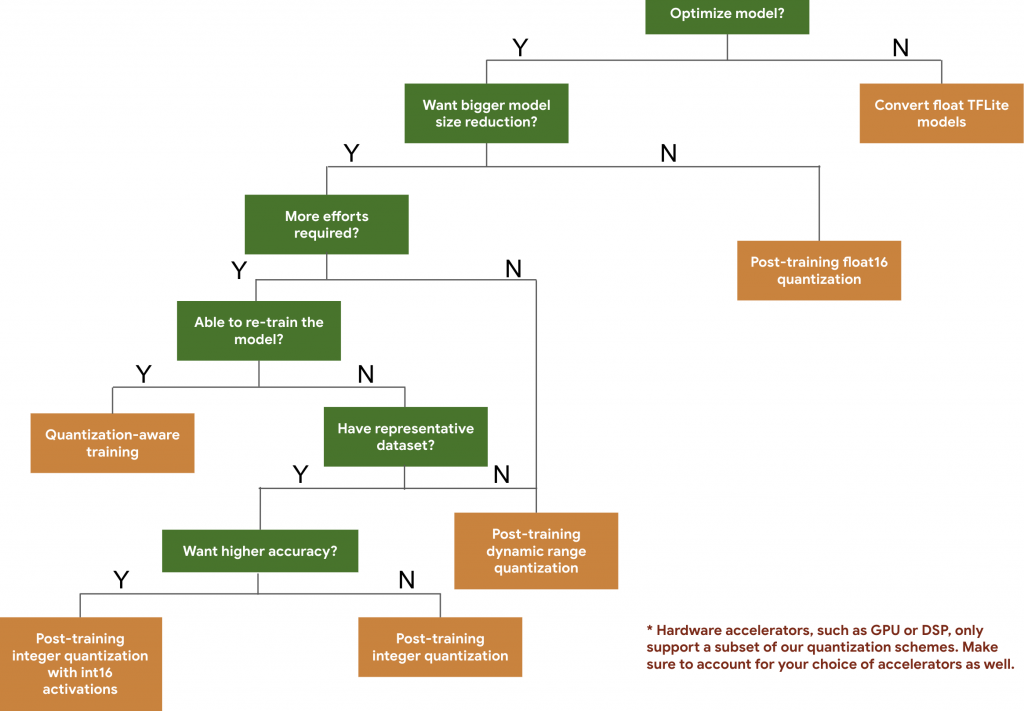
Lors de l’exportation, vous remarquerez que AutoML Vision edge exporte des modèles quantifiés. Cela permet de réduire la taille du modèle sans effectuer une dégradation de précision, de latence processeur et matériel. Il sera donc important d’adapter votre code d’utilisation en conséquence (float32 pour les modèles non quantifiés VS uint8 modèle quantifié).
Démonstration du modèle
Petite démonstration du modèle exécuté sur une application mobile flutter :
Déployer un modèle
AutoML Vision permet de déployer votre modèle sur une infrastructure TPU : Tensor Processing Unit. C’est d’ailleurs ce type d’architecture qui est utilisé par des outils tels que Google Photos ou encore l’assistant Google.

Votre modèle peut ensuite être déployé sur ce type d’architecture optimisé, pouvant ensuite être contacté par une API REST. Pour cela il suffit de cliquer dans le menu de votre modèle, puis déployer un modèle.

Une popin va ensuite apparaître :
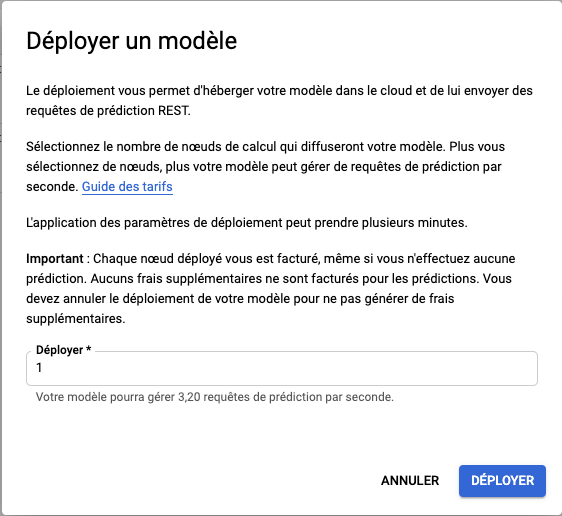
Vous définissez le nombre de nœud nécessaire selon votre trafic (3.20 requêtes par seconde par nœud) et vous obtenez une API Vision personnalisée. Cependant, attention aux coûts non négligeables de ce type de service !
Pour contacter l’API rien de plus simple, il suffit de lancer la requête suivante :
curl -X POST \
-H "Authorization: Bearer "$(gcloud auth application-default print-access-token) \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
https://automl.googleapis.com/v1/projects/project-id/locations/us-central1/models/model-id:predictLe contenu de la requête contiendra votre image en base64 :
{
"payload": {
"image": {
"imageBytes": "VOTRE IMAGE BASE 64"
}
}
}Attention : n’oubliez-pas de créer un compte de service spécialisé en dehors de cet article !
Puis on obtient le résultat suivant :
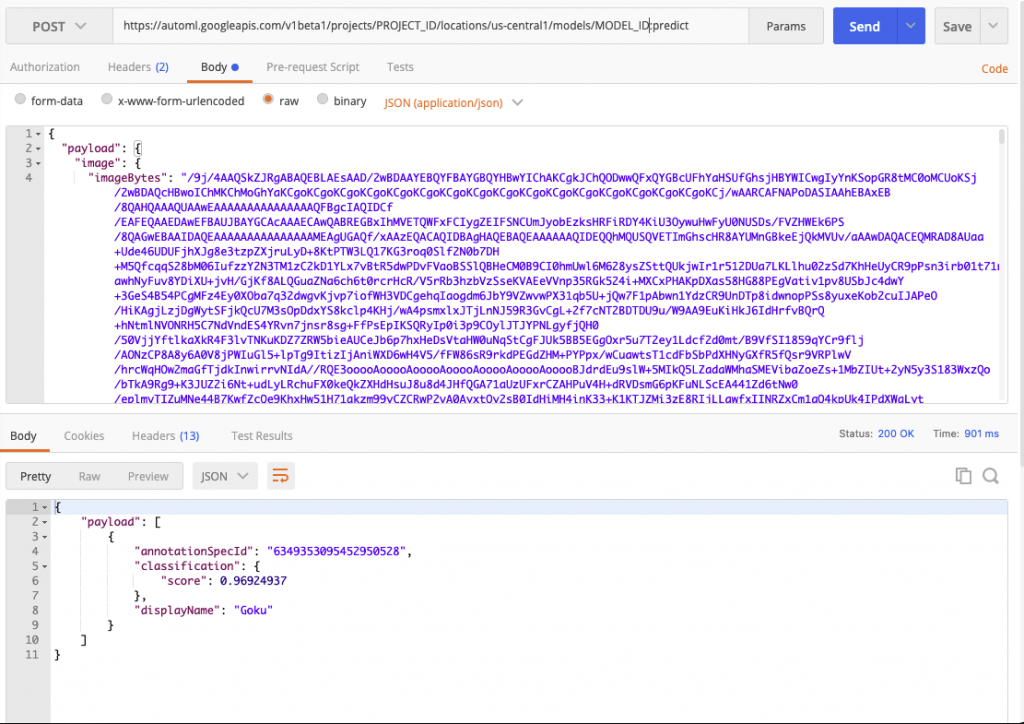
L’API retourne le résultat de la classe “Goku” ainsi que le score associé : 0.96 soit 96% de certitude.
Conclusion
Grâce à AutoML Vision vous avez toutes les cartes en main pour créer votre propre modèle de classification et même allez bien loin !
En mai 2021, Google a annoncé Vertex AI : une plateforme MLOps. Celle-ci s’inscrit dans un scope beaucoup plus large ; en effet plusieurs outils vont permettre d’automatiser, superviser, optimiser, déployer un modèle. Voici dans quoi va s’inscrire AutoML :

- diffusion, partage et réutilisation des fonctionnalités de ML (Vertex Feature Store)
- alerting sur les écarts de données, concepts et autres incidents
- pipelines de modélisation continue (Vertex Pipelines)
- diffusion de modèle sur des APIs containerisées (Vertex Prediction)
- visualisation de suivi (Vertex TensorBoard)
- …
La plateforme est compatible avec différents framework tels que TensorFlow, PyTorch mais aussi scikit-learn.
Vertex AI n’est pas obligatoire, libre à vous de choisir le cadre dans lequel vous souhaitez vous inscrire. Vous êtes maintenant prêts pour classer, trier, reconnaître toutes les images que vous souhaitez, même si ce n’est pas du Manga !