Annoncé en nouveauté de la version 5 de Redis en octobre 2018, Redis Streams surfe depuis donc plus de deux ans sur la vague des architectures event-driven. Emboitant le pas à Apache Kafka (et d’autres), il propose lui aussi des fonctionnalités très intéressantes en termes de stream de données.
Si vous connaissez Redis, vous savez qu’il propose plusieurs structures de données et Redis Streams en est une à part entière. Comme d’autres “message-oriented middlewares” (ou MOM), cette structure est de type “append-only log” où chacun de vos enregistrements est immuable.

Contrairement à la structure Pub/Sub qui ne conserve pas les données et les met uniquement à disposition des “subscribers” qui sont connectés au moment de la publication, les Redis Streams sont conservés dans le temps.
Cet article est un petit tour d’horizon de Redis Streams, issu du cours Ru202 – Redis Streams, d’où proviennent les captures (merci Redis !). Je vous conseille vivement les cours en ligne proposés par Redis University si vous souhaitez monter en compétences sur cette solution : des vidéos pédagogiques, des quizz pour valider l’apprentissage, des petits exercices pour se faire la main et un “examen” relativement simple si vous avez bien suivi.
Passe moi la clé de Stream !
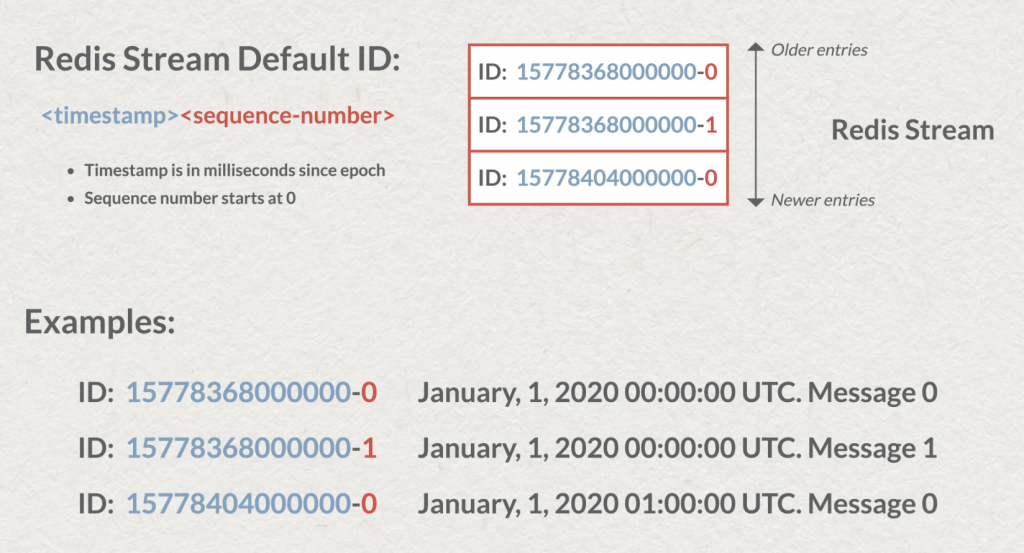
Chacun de vos stream sera caractérisé par une paire clé-valeur. Petite subtilité, chaque entrée possède un identifiant unique, par défaut : en préfixe le timestamp de sa création puis un numéro de séquence (en cas de multiples écritures au même instant). Ce qui peut être très intéressant pour réaliser des requêtes de type “range” et donc lire des messages dans un certain intervalle de temps.
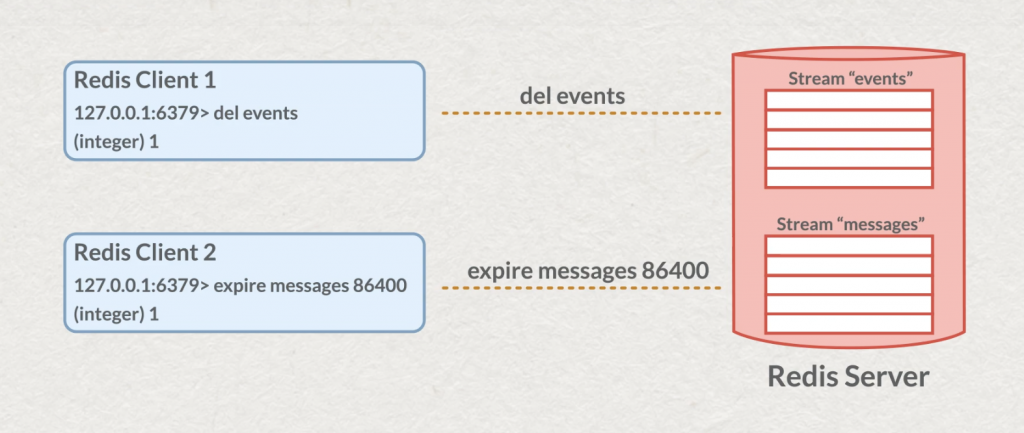
Comme toutes les structures de données de Redis sur lesquelles vous pouvez faire des “key based operation”, vous pourrez donc fixer par exemple un “Time To Live” ou supprimer entièrement le stream.
Les enregistrements contenus dans les streams peuvent contenir plusieurs champs. Comme d’autres MOM, plusieurs applications peuvent consommer la donnée, elles sont alors chacune identifiée comme un “consumer group”.
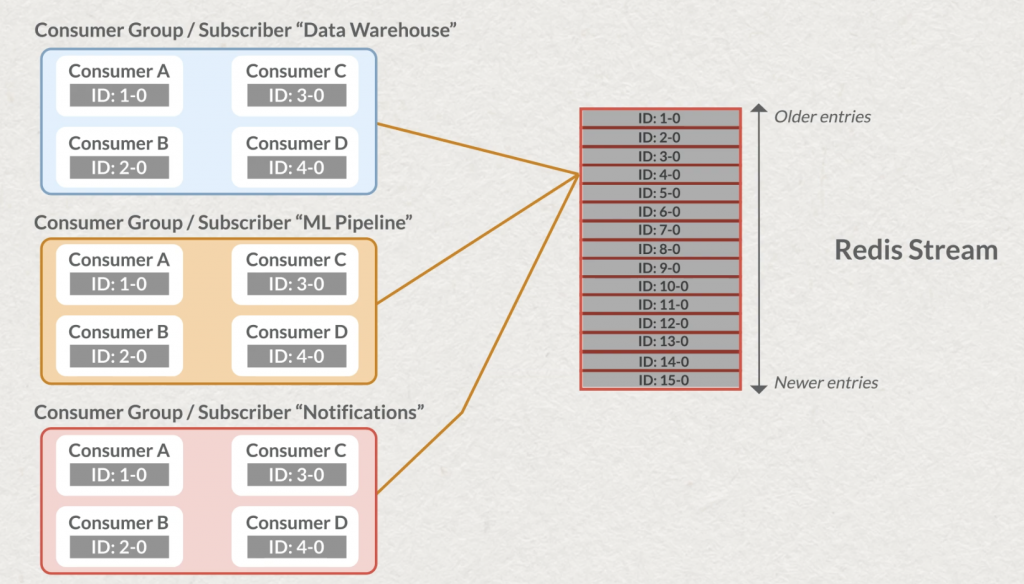
Il existe avec Redis des commandes dites “bloquantes” et d’autres “non bloquantes”. Les streams vous permettent de choisir entre les deux modes de lecture et donc attendre ou non, quand vous interrogez un stream, d’avoir de la donnée pendant un laps de temps ou de vous rendre la main immédiatement s’il n’y a rien de nouveau.
Production des données
L’API Producer permet à un ou plusieurs “producer” d’écrire de la donnée dans un stream.
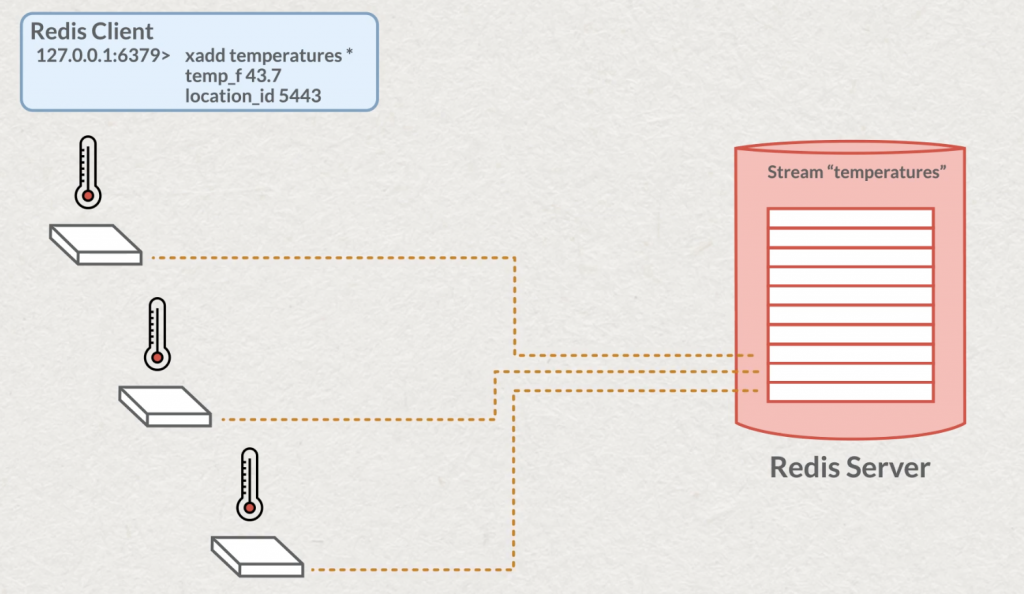
C’est la commande xadd qui nous permettra d’écrire des messages en spécifiant le stream dans lequel on souhaite insérer des données. Dans de rares cas, vous pourrez spécifier vous-même l’identifiant, mais il est recommandé de laisser Redis gérer cet identifiant et donc l’insertion dans l’ordre. Puis, comme pour la structure “hash” vous pourrez ajouter votre liste de clé/valeur, toutes représentées par une string et de capacité maximale d’un demi gigabyte.
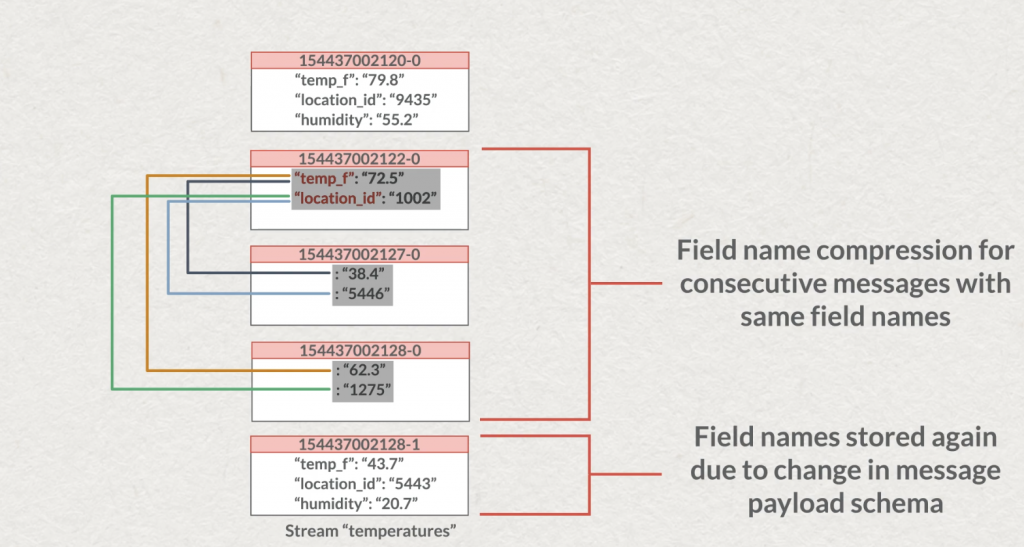
Redis reste agnostique des données que vous poussez, il ne tentera aucun process sur vos données que votre chaîne représente finalement du texte, un nombre, un hash, un Json compressé… peu importe. Vous gérez votre modèle de données. Petite subtilité encore, si plusieurs de vos messages possèdent successivement les mêmes champs, Redis, pour réduire la taille des données, supprimera la valeur des champs (comme illustré ci-dessous). Ce qui peut être utile par exemple dans le traitement de messages cadencés à intervalle régulier, mais dont la valeur n’a pas forcément varié (ex: des capteurs de températures).
Si vous connaissez la notion de complexité O(n) des commandes Redis, sachez que l’écriture d’un stream est une opération de complexité O(1) (complexité fixe) et qu’elle garantie une écriture sous la milliseconde en termes de latence. À chaque opération d’écriture réussie, le retour de la commande sera l’identifiant généré par Redis. C’est pourquoi lorsque vous générez un grand nombre de messages, vous pourrez retrouver des clés composées d’un timestamp en milliseconde et d’un numéro de séquence de 0 à x messages qui sera écrit dans ce laps de temps (comme rappelé en introduction). Exemple ici avec 10 écritures:
127.0.0.1:6379> 10 XADD ilabstreamtest * field1 value1 field2 value2 field3 value3
"1615411668019-0"
"1615411668020-0"
"1615411668020-1"
"1615411668021-0"
"1615411668021-1"
"1615411668021-2"
"1615411668021-3"
"1615411668021-4"
"1615411668024-0"
"1615411668024-1"Si vous souhaitez garantir l’ordre des messages du côté de la production de données en gérant votre propre séquence incrémentale, c’est tout à fait possible, mais si un de vos producteurs de données tente d’insérer un message avec une clé antérieure à la dernière, il recevra une erreur du serveur.
A tout instant vous pouvez connaître le nombre de messages contenus dans mon stream avec la commande XLEN.
127.0.0.1:6379> XLEN ilabstreamtest
(integer) 10Pour vérifier que Redis compte correctement les messages à disposition dans le stream, nous effectuons la suppression de deux messages via leur identifiant, puis à nouveau un comptage.
127.0.0.1:6379> XDEL ilabstreamtest 1615411668021-1 1615411668024-0
(integer) 2
127.0.0.1:6379> XLEN ilabstreamtest
(integer) 8Une autre manière de supprimer des messages est de tronquer le stream en spécifiant un nombre maximum de messages. La commande permet deux types de suppression, aussi je vous renvoie à sa documentation. Attention, plus vous tronquez, plus l’opération (bloquante) sera longue.
127.0.0.1:6379> XTRIM ilabstreamtest MAXLEN 4
(integer) 4
127.0.0.1:6379> XLEN ilabstreamtest
(integer) 4Tout va bien, notre serveur local fonctionne et compte correctement 😉
Lire par paquet, en avant et en arrière
Une fonctionnalité intéressante dans des cas de reporting ou même de batch est de pouvoir lire le stream à un endroit précis. Même si nous sommes dans une logique stream, certains applicatifs peuvent avoir à faire des lectures parcellaires ou n’ont pas la possibilité de réagir en temps réel ou même n’en ont pas l’intérêt, car ce sera une vue partiellement ou totalement agrégée qui les intéressera.
La commande XRANGE et XREVRANGE vous permettra de le faire dans le sens qui sied à votre cas d’utilisation. Nous pouvons donc interroger le stream par paquet en partant d’un endroit précis. Comme dans ce premier exemple en lui demandant de partir du premier message avec l’argument : “-“. Cet exemple est tiré de l’université Redis Streams et possède un streams “numbers” fini de 100 éléments, les 100 premiers nombres.
127.0.0.1:6379> xrange numbers - + Count 5
1) 1) "1615827307631-0"
2) 1) "n"
2) "0"
2) 1) "1615827307633-0"
2) 1) "n"
2) "1"
3) 1) "1615827307633-1"
2) 1) "n"
2) "2"
4) 1) "1615827307633-2"
2) 1) "n"
2) "3"
5) 1) "1615827307633-3"
2) 1) "n"
2) "4"Je pourrai donc ensuite repartir de mon dernier id de message connu : “1615827307633-3” et l’ordre étant garanti récupérer les 5 messages suivants. Vous remarquerez que la commande est inclusive, les messages renvoyés commencent à l’identifiant que vous aurez fourni en entrée.
127.0.0.1:6379> xrange numbers 1615827307633-3 + Count 5
1) 1) "1615827307633-3"
2) 1) "n"
2) "4"
2) 1) "1615827307633-4"
2) 1) "n"
2) "5"
3) 1) "1615827307633-5"
2) 1) "n"
2) "6"
4) 1) "1615827307633-6"
2) 1) "n"
2) "7"
5) 1) "1615827307634-0"
2) 1) "n"
2) "8"Bien entendu la commande inverse aura une petite subtilité dans l’ordre des arguments et l’ordre dans lequel les valeurs seront renvoyées :
127.0.0.1:6379> xrevrange numbers + - Count 5
1) 1) "1615827307645-2"
2) 1) "n"
2) "100"
2) 1) "1615827307645-1"
2) 1) "n"
2) "99"
3) 1) "1615827307645-0"
2) 1) "n"
2) "98"
4) 1) "1615827307644-10"
2) 1) "n"
2) "97"
5) 1) "1615827307644-9"
2) 1) "n"
2) "96"Vous ferez tout de même attention à la manipulation de cette commande. Sur un stream conséquent dans lequel des nouveaux messages sont continuellement écrit, la complexité des commandes est en O(n).
Lire en temps réel
Cette fois-ci, nous utiliserons la commande XREAD, qui va nous permettre depuis un id de message d’en lire un certain nombre, et de recommencer indéfiniment… À notre charge (nous, consommateur) de retenir le dernier identifiant lu, Redis nous garantira la lecture de message dont l’identifiant est supérieur.
127.0.0.1:6379> xread COUNT 5 STREAMS numbers 1615827307633-3
1) 1) "numbers"
2) 1) 1) "1615827307633-4"
2) 1) "n"
2) "5"
2) 1) "1615827307633-5"
2) 1) "n"
2) "6"
3) 1) "1615827307633-6"
2) 1) "n"
2) "7"
4) 1) "1615827307634-0"
2) 1) "n"
2) "8"
5) 1) "1615827307634-1"
2) 1) "n"
2) "9"
Contrairement à d’autres message-oriented middlewares, c’est à vous de retenir le dernier message lu, pas au serveur Redis. En cas de crash de l’application, il vous faudra avoir partagé/conservé cette information. Vous pouvez tout de même la stocker dans Redis, mais la lecture/écriture est à votre initiative. Cette fois, comparée à XRANGE la commande XREAD est exclusive, le message lu est celui juste après l’identifiant fourni.
La commande permet aussi un mode bloquant qui vous permettra d’attendre un nombre défini de secondes pour obtenir un nombre de messages. Reprenons, pour illustrer le blocage un identifiant d’une fin de stream, je vais lui demander 5 nouveaux messages pendant 3 secondes, mais qui n’arriveront jamais.
127.0.0.1:6379> XREAD COUNT 5 BLOCK 3000 STREAMS numbers 1615827307645-2 (nil) (3.05s)
Dans un véritable use case de stream continu, cette commande avec un timeout infini bloquera votre application jusqu’à ce qu’il y ait un nombre suffisant de messages à lire. Une fois traité, vous pourrez de nouveau appeler la commande en rappelant le dernier identifiant que vous avez traité, ou rappeler la commande initiale dans le cas d’une erreur et d’un pattern de retry.
Pour démarrer la lecture d’un stream au moment où votre application se connecte pour la première fois (vous n’avez pas besoin des messages précédents), l’argument ‘$’ en fin de commande vous enverra les messages écrits dans le stream juste après votre XREAD.
Ce que nous venons de voir pour un consommateur, s’applique bien évidemment à plusieurs et chacun à leur rythme.
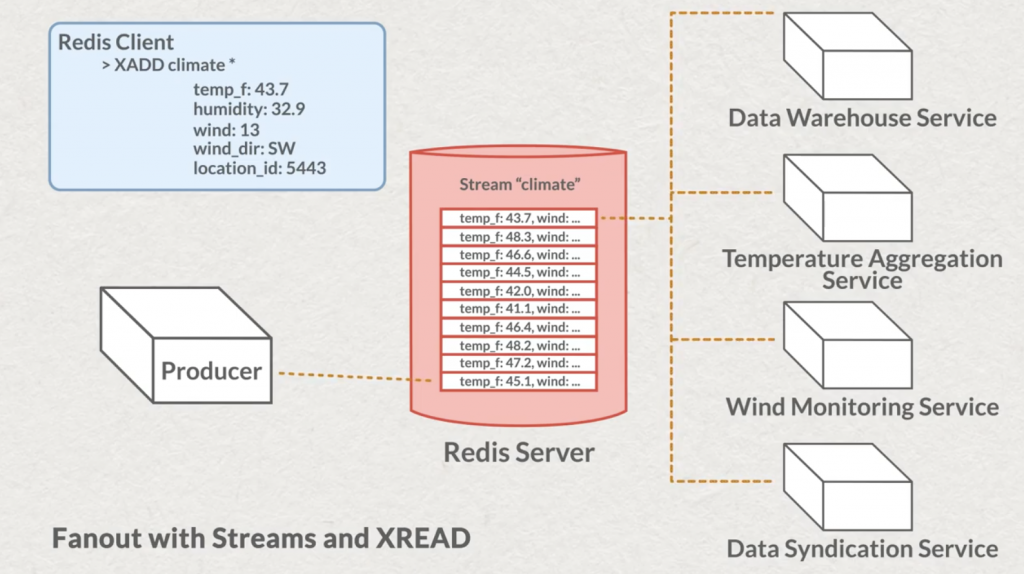
Chaque consommateur pourra récupérer autant de messages qu’il le souhaite et mettre le temps qu’il faut pour les traiter. Les lectures au fil de l’eau des consommateurs sont bien décorrélées.
Plus vite consumer !
Parfois certains streams ont un taux d’écriture plus élevé que la capacité de lecture des consommateurs. Cela signifie que les écritures, dans le temps vont s’empiler et que le lag des consommateurs va augmenter. La parallélisation et le partitionnement seront alors vos amis.
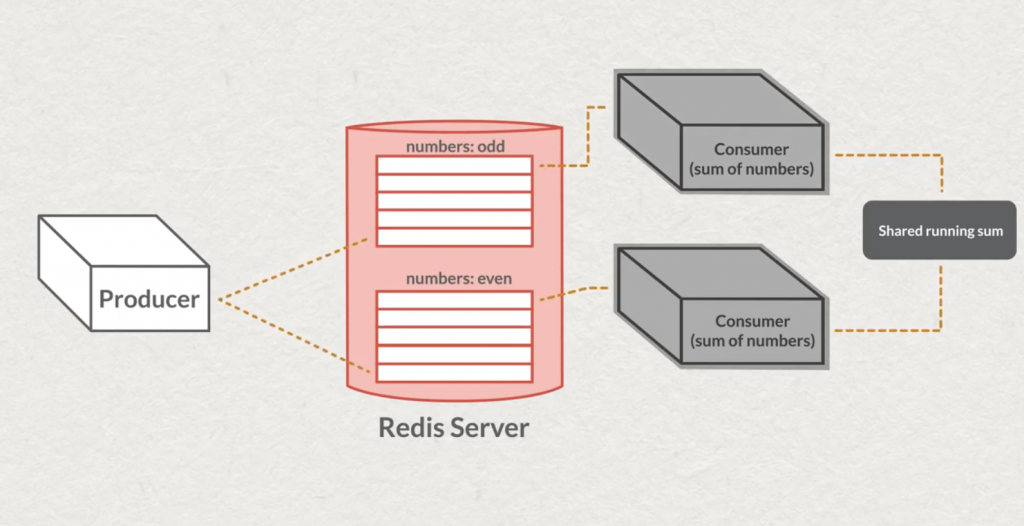
Si vous connaissez par exemple Apache Kafka, vous connaissez la notion de partitionnement et de “consumer group”. Redis n’échappe pas à ce pattern, et c’est la commande XGROUP qui va nous aider.
À chaque création d’un “consumer group”, nous spécifions un identifiant de message à partir du quel le groupe pourra commencer à lire les messages du stream.
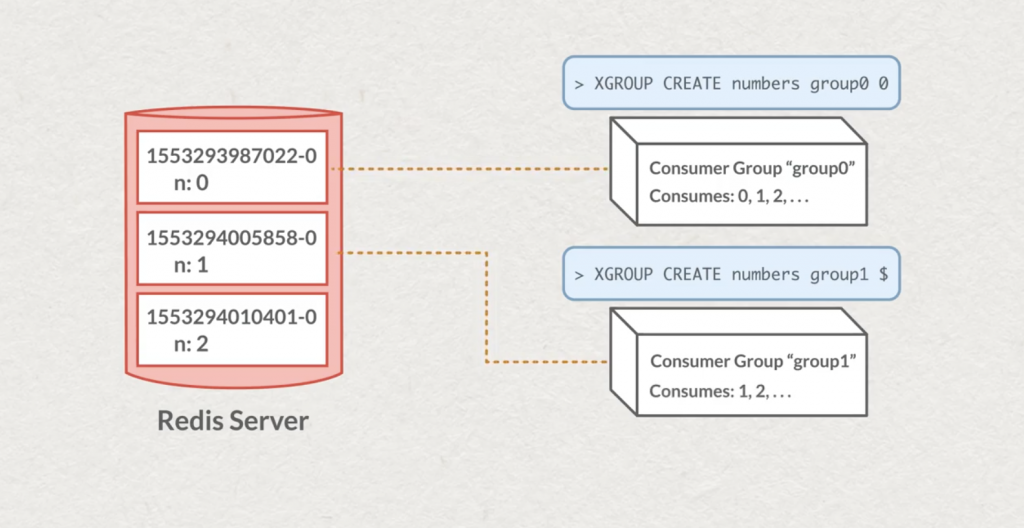
Ensuite, chaque groupe de message sera indépendant dans sa lecture. La commande XINFO pourra nous aider à connaître l’état d’un groupe et où il en est dans sa lecture. Pour lire les messages dans un groupe, exit la commande XREAD, c’est la commande XREADGROUP qu’il vous faudra utiliser. Là aussi, comme dans d’autres technologies de Stream, il faudra retenir le dernier message “traité” par le groupe. C’est une structure à part entière dans Redis qui va s’en charger : PEL “Pending Entries List”.
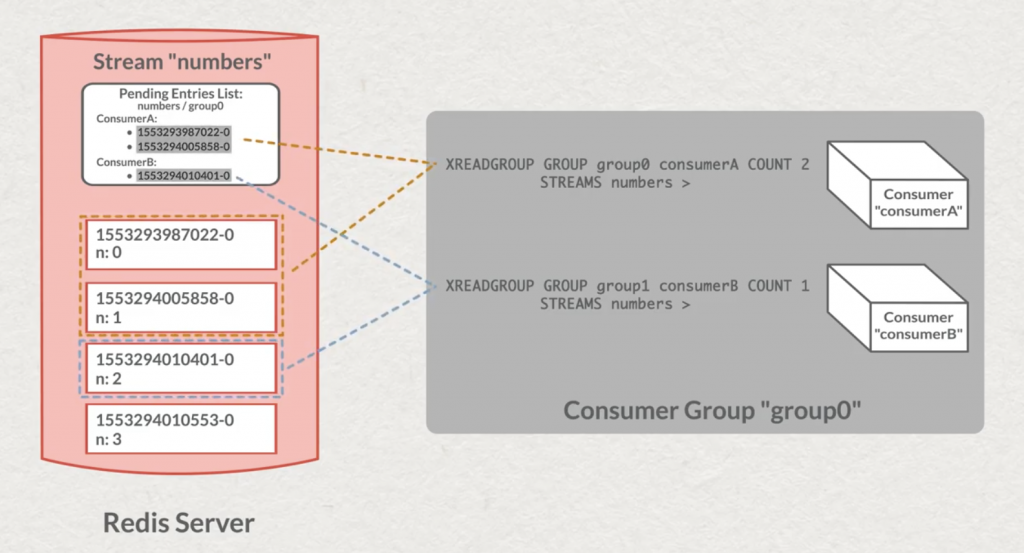
Ensuite, c’est au consommateur d’effectuer un “acknowledgement” auprès du serveur pour spécifier qu’il a lu et traité le message. C’est grâce à la commande XACK que nous pourrons notifier le serveur. Il saura alors que nous avons traité les messages et qu’il faut les retirer de la PEL.
Votre consommateur n’est plus en ligne
Nous venons de voir qu’un consommateur dans un groupe réalise un ACK des messages qu’il vient de récupérer. Seulement que se passe-t-il s’il s’éteint (pour x raison ) avant d’avoir réalisé cet acquittement ?
Reprenons l’exemple du cours avec un streams de nombres. Deux consommateurs lisent les messages à leur rythme. La commande XINFO sur notre streams nous donne leur “état” de lecture.
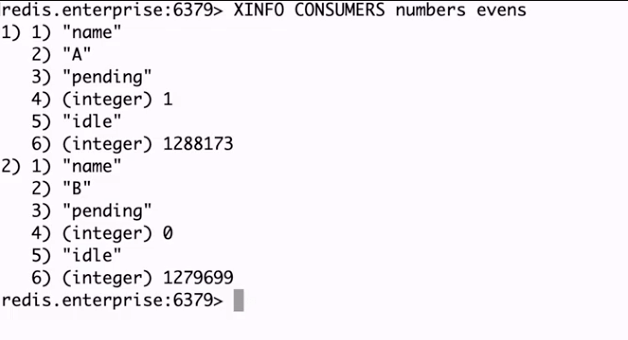
Le consommateur A a un message en mode “pending”, tandis que le consommateur B n’en a aucun.
La commande XPENDING nous donnera donc les informations sur ce message “pending” du consommateur A de notre groupe “evens”. Un autre usage de XPENDING vous donnera des informations sur les identifiants de messages (je vous laisse lire la documentation de Extended form of XPENDING).
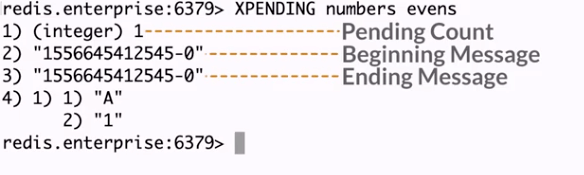
Supposons que notre consommateur A ne dépile plus les messages, la commande XCLAIM nous permettra de réaffecter ses messages “pending” vers le consommateur B.

La commande XAUTOCLAIM facilite désormais l’utilisation de XPENDING et XCLAIM.
Voilà nous sommes déjà à la fin de notre stream. Nous avons couvert une bonne partie des commandes qui vont vous permettre de manipuler des Redis Streams. Contrairement à Apache Kafka, RabbitMQ je n’ai pas encore eu l’occasion d’implémenter de véritables cas d’usages avec Redis Streams. Cependant s’il est déjà dans la stack technique de mon projet et que le besoin d’une structure de type Stream était nécessaire, je me pencherai sérieusement sur cette option.
Je vous laisse découvrir par vous-même les cours sur la Redis University et vous faire votre propre opinion.
Et vous, vous streamez sur quoi ?