
Pourquoi faire ?
En cas de perte de données sur ton GCP Cloud Storage Bucket, tu préfères “galèrer” pendant des heures et prier pour essayer de récupérer quelque chose, ou simplement restaurer grâce à une sauvegarde quotidienne ?
“Moi je pense la question elle est vite répondue…”
La question de la nécessité de backup pour des données sensibles sur un bucket ne se pose pas.
Il existe néanmoins une méthode dans GCP pour sauvegarder/backup les fichiers d’un bucket : activer le versionning. Cela créé une nouvelle version du fichier à chaque modification et archive l’ancienne version. Il est donc possible de restaurer le fichier en utilisant son numéro de version. C’est très bien pour un seul fichier… mais encore faut-il savoir lequel, s’il y a beaucoup de fichiers à restaurer, ça devient vite la galère… et s’il existe des relations entre les fichiers, ces relations n’existeront plus. Voici plusieurs arguments qui m’ont poussé à vouloir faire une sauvegarde entière du bucket tous les jours.
Le backup
Présentation globale
Nous utiliserons 3 services fournis par Google Cloud Platform:
- Cloud Scheduler : comme son nom l’indique, il s’agit d’un planificateur de tâches Cron. C’est ce qui nous permettra de déclencher notre traitement tous les jours à 5h.
- Cloud Pub/Sub : Service de messagerie asynchrone qui dissocie les services de production et de traitement des événements. Nous détaillerons plus loin son rôle dans notre architecture.
- Cloud Functions : Service qui permet d’exécuter une fonction en serverless. C’est l’équivalent de Lambda chez AWS et Functions chez Azure.
Le schéma ci-dessous représente l’architecture du backup:
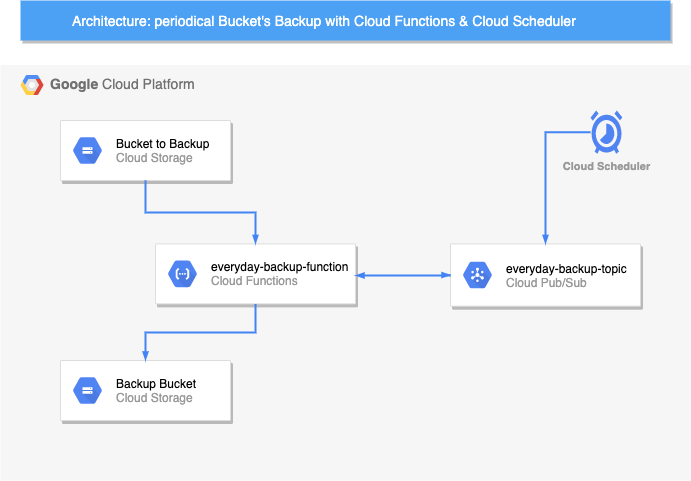
Nous allons configurer Cloud Scheduler pour qu’il publie un évènement tous les jours à 5h du matin.
Cet évènement sera envoyé dans un topic de Cloud Pub/Sub.
Puis nous allons créer une fonction dans Cloud Functions qui se déclenche quand un nouvel “event” est créé sur un topic ( tu auras deviné qu’on parle toujours du même topic ).
Cette fonction copiera le contenu d’un Bucket A dans un dossier du Bucket B. Le dossier sera nommé avec la date du jour. Vous avez tous compris ? Let’s do it !
Création du Bucket de sauvegarde
Commençons par nous préoccuper du bucket (nommé Google Cloud Storage ou GCS chez Google )
il existe 4 classes de stockage pour le GCS:
- Standard
- Nearline
- Coldline
- Archive
Le choix s’effectuera en fonction de la disponibilité, du coût du stockage et de la fréquence d’accès à la donnée. Ici nous allons choisir une sauvegarde Nearline qui est bien plus approprié pour du backup.
Pour sécuriser mon bucket, nous lui ajoutons un période de retention de 30 jours. C’est-à-dire que les fichiers présents sur notre bucket de sauvegarde ne peuvent pas être modifiés ou supprimés pendant 30 jours.
gsutil mb -c nearline gs://my-backup-bucket -l europe-west1 --retention 30d
Enfin, pour ne pas avoir des coûts de stockage trop importants, nous allons paramétrer une règle de cycle de vie. Tous les fichiers plus vieux de 1 mois seront supprimés.
echo '{
"rule":
[
{
"action": {"type": "Delete"},
"condition": {"age": 31}
}
]
}' > 31-days-delete.json
gsutil lifecycle set 31-days-delete.json gs://my-backup-bucket
Création de la Cloud Function
Occupons-nous maintenant de la fonction qui sera exécutée. Pour rappel, cette fonction sera déclenchée lorsque un évènement sera détecté sur le Topic Pub/Sub. Son job sera de sauvegarder le contenu d’un bucket dans un autre bucket en spécifiant la date de la sauvegarde
Dans la console GCP, allez dans Cloud Functions, puis “Create Function”
Vous pouvez paramétrer la fonction comme ceci :

il faut sélectionner le topic qu’il doit écouter. Si il n’existe pas, créez le en cliquant sur “Create Topic” . le Topic ID doit être unique, Vous pouvez lui donner le nom que vous souhaitez.
cliquez ensuite sur “Save” puis “Next”.

Sur la page suivante, nous allons y mettre le code de la fonction. le code est en Node.js. Vous pouvez laisser les 2 paramètres Runtime et Entrypoint par défaut.
Copiez-collez le code ci dessous respectivement dans index.js et package.json . Attention à remplacer <BUCKET_TO_BACKUP_NAME> et <BACKUP_BUCKET_NAME>:
/**
* Triggered from a message on a Cloud Pub/Sub topic.
*
* @param {!Object} event Event payload.
* @param {!Object} context Metadata for the event.
*/
const admin = require('firebase-admin');
admin.initializeApp();
const sourceBucket = admin.storage().bucket("<BUCKET_TO_BACKUP_NAME>");
const destBucket = admin.storage().bucket("<BACKUP_BUCKET_NAME>");
exports.helloPubSub = async (event, context) => {
console.log("backup started")
const d = new Date();
const dateStr = d.toLocaleDateString("fr-FR").replace(/\//g, '-');
console.log(dateStr);
const [sourceFiles] = await sourceBucket.getFiles();
const sourceFileNames = sourceFiles.map(
(file) => file.name);
console.log(dateStr, "# Total", sourceFileNames.length);
let promises = [];
for (let fileName of sourceFileNames) {
const copyFilePromise = sourceBucket.file(fileName).copy(destBucket.file(`${dateStr}/${fileName}`));
promises.push(copyFilePromise);
}
await Promise.all(promises);
console.log("backup ended")
return "DONE";
};
{
"name": "sample-pubsub",
"version": "0.0.1",
"dependencies": {
"@google-cloud/pubsub": "^0.18.0",
"firebase-admin": "8.0.0"
}
}
C’est tout ! Vous pouvez enfin déployer la fonction.
Création du Cloud Scheduler
Comme son nom l’indique, c’est ici que nous allons planifier la tache. Pour rappel, nous allons paramétrer le cloud scheduler pour qu’il poste un évènement dans le topic tous les jours à 5h du matin, ce qui déclenchera la fonction de sauvegarde.
Dans Cloud Scheduler, cliquez sur Create Job, puis remplir comme ci dessous. La partie Frequency doit être au format unix-cron.
Le formatage de l’expression cron est expliqué sur ce lien.
Le topic doit être le même que créé précédemment.
Le payload est le texte que contiendra l’évènement. Le format est libre, vous pouvez y mettre ce que vous voulez. J’ai choisi le même texte que le nom du topic.
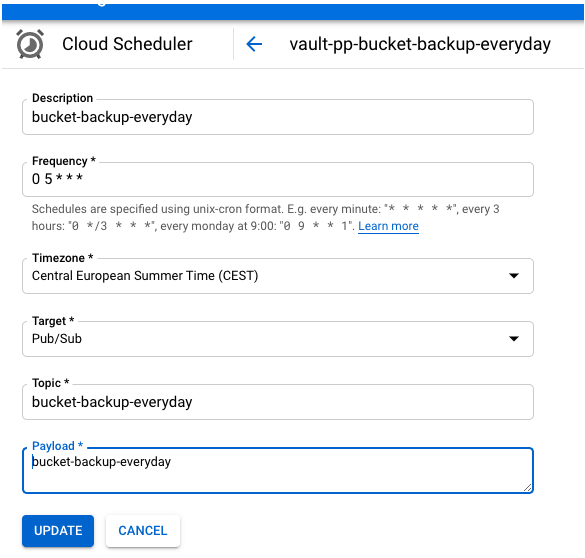
Et voila ! c’est terminé ! Maintenant testons ça!
Pour éviter de devoir attendre 5h le lendemain matin, vous pouvez lancer le job directement en cliquant sur Run Now (dans Cloud Scheduler).
Ensuite allons voir les logs:
Il faut d’abord retourner dans la fonction et cliquer sur view logs en haut. Les logs de la dernière heure s’affichent. Si tout s’est bien passé, vous devriez avoir ces logs :

Enfin, dans le bucket de backup, vous devriez retrouver la sauvegarde du jour.
gsutil ls gs://my-backup-bucket
La restauration
C’est bien d’avoir un backup, mais si on ne sait rien en faire… ça ne sert pas à grand chose 😀
Pour restaurer, il existe plusieurs façons de procéder.
Avec la console
Avec la console, vous pouvez utiliser le service Transfert Service qui vous permet de copier les fichiers d’un bucket à un autre :

En CLI avec gsutil
En ligne de commande, la commande est relativement simple en utilisant gsutil. Il faut par contre que votre “user” ait les droits lecture/écriture sur les buckets respectifs (source et destination) :
gsutil -m cp -r gs://my-backup-bucket/<M-DD-YYYY>/* gs://my-bucket-to-restore
Bonus: un script bash
Préparation et scripting
Dans le cadre de mon project actuel, nous utilisons rundeck pour permettre de lancer des jobs à distance. Un script Bash nous permet de réaliser les actions en cliquant sur un simple bouton dans l’interface rundeck..
Le script est également exploitable depuis votre poste, ou depuis un serveur bastion.
Pour permettre au script d’accéder au projet GCP et aux buckets, il faut d’abord créer un service-account :
gcloud iam service-accounts create <service_account_name>
j’ajoute ensuite les droits nécessaires au service account :
- Lecture sur le bucket de backup :
gsutil iam ch serviceAccount:<service_account_name>@<projectID>.iam.gserviceaccount.com:objectViewer gs://my-backup-bucket
- Lecture/écriture sur le bucket de destination:
gsutil iam ch serviceAccount:<service_account_name>@<GCP_projectID>.iam.gserviceaccount.com:objectViewer gs://my-bucket-to-restore gsutil iam ch serviceAccount:<service_account_name>@<GCP_projectID>.iam.gserviceaccount.com:objectCreator gs://my-bucket-to-restore
Enfin, je créé une clé JSON pour m’authentifier depuis l’extérieur du projet avec ce service-account :
gcloud iam service-accounts keys create --iam-account <service_account_name>@<projectID>.iam.gserviceaccount.com key.json
Cette clé JSON key.json est stockée par la suite dans un Vault. Le script réalise un appel à Vault pour récupérer cette clé et s’authentifier au projet GCP.
Je vous partage le fameux script ! Il n’est pas exploitable en l’état, il faut modifier les chemins, les noms de service-account et ainsi adapter les valeurs à votre situation.
#!/bin/bash
DIR="/home/rundeck/gcp_restore"
VAULT="/usr/bin/vault"
EMAIL_SA_GCP="<service_account_name>@<projectID>.iam.gserviceaccount.com"
mkdir -p $DIR
export CLOUDSDK_CONFIG=$DIR/.gcp_restore
export VAULT_ADDR=https://<vault_URL>
usage(){
echo "Usage: $0 [-m <list|restore>] [-h <help>]" 1>&2
exit 1
}
usage_list(){
echo -e "Usage: $0 -m list" 1>&2
echo -e "Options:" 1>&2
echo -e "\t-b <gcp backup bucket name>" 1>&2
echo -e "\t-p <gcp project ID>" 1>&2
echo -e "\t-v <my vault token>" 1>&2
exit 1
}
usage_restore(){
echo -e "Usage: $0 -m restore" 1>&2
echo -e "Options:" 1>&2
echo -e "\t-b <gcp backup bucket name>" 1>&2
echo -e "\t-r <gcp bucket to restore>" 1>&2
echo -e "\t-d <date to restore format M-DD-YYYY>" 1>&2
echo -e "\t-p <gcp project ID>" 1>&2
echo -e "\t-v <my vault token>" 1>&2
exit 1
}
while getopts ":b:r:m:d:p:v:" option; do
case "${option}" in
b)
BUCKET_BACKUP=${OPTARG}
;;
m)
METHOD=${OPTARG}
[[ "$METHOD" == "list" || "$METHOD" == "restore" ]] || usage
;;
r)
BUCKET_RESTORE=${OPTARG}
;;
d)
DATE_RESTORE=${OPTARG}
;;
p)
PROJECT_ID=${OPTARG}
;;
v)
MY_VAULT_TOKEN=${OPTARG}
;;
*)
usage
;;
esac
done
# Verification du parameter method indispensable au script
if [ -z "${METHOD}" ]; then
usage
fi
if [[ "$METHOD" == "list" ]]; then
# Verification du parametre obligatoire sinon affichage usage_list()
if [[ -z "${BUCKET_BACKUP}" ]] || [[ -z "${PROJECT_ID}" ]] || [[ -z "${MY_VAULT_TOKEN}" ]]; then
usage_list
fi
# récupération du service account dans Vault
$VAULT login -no-print ${MY_VAULT_TOKEN}
if [[ "$?" != 0 ]]; then
exit 1
fi
$VAULT read -field <VAULT_KEY_NAME> chemin/du/secret/dans/vault > $DIR/rundeck-restore-bucket-sa.json
# authentification via service Account & config sur le project id
gcloud auth activate-service-account ${EMAIL_SA_GCP} --key-file=$DIR/rundeck-restore-bucket-sa.json --project=${PROJECT_ID}
echo -e "\033[0;32mBackup availabe for:\033[0m in ${BUCKET_BACKUP}"
# Recuperation de la liste des backups
gsutil ls gs://$BUCKET_BACKUP | cut -d '/' -f4
# suppression service account
gcloud auth revoke ${EMAIL_SA_GCP}
rm -f $DIR/rundeck-restore-bucket-sa.json
elif [[ "${METHOD}" == "restore" ]]; then
# Verification des deux parameters obligatoire sinon affichage usage_list()
if [[ -z "${BUCKET_BACKUP}" ]] || [[ -z "${BUCKET_RESTORE}" ]] || [[ -z "${DATE_RESTORE}" ]] || [[ -z "${PROJECT_ID}" ]] || [[ -z "${MY_VAULT_TOKEN}" ]]; then
usage_restore
fi
# récupération du service account dans Vault
$VAULT login -no-print ${MY_VAULT_TOKEN}
$VAULT read -field <VAULT_KEY_NAME> chemin/du/secret/dans/vault > $DIR/rundeck-restore-bucket-sa.json
# authentification via service Account & config sur le project id
gcloud auth activate-service-account ${EMAIL_SA_GCP} --key-file=$DIR/rundeck-restore-bucket-sa.json --project=${PROJECT_ID}
gsutil -m cp -r gs://${BUCKET_BACKUP}/${DATE_RESTORE}/* gs://${BUCKET_RESTORE}/
# suppression service account
gcloud auth revoke ${EMAIL_SA_GCP}
rm -f $DIR/rundeck-restore-bucket-sa.json
fi
Utilisation du script
Le script a 2 possibilités d’usage: lister et restaurer. Le choix se fait par le biais de l’option -m :
-m list-m restore
Voici un exemple d’usage pour les 2 options :
- Option : lister
bash /home/rundeck/projects/scripting_ops/scm/restore_bucket.sh -m list -b my-backup-bucket -v <vault_token> -p <GCP_projectID>
- Option : restaurer
bash /home/rundeck/projects/scripting_ops/scm/restore_bucket.sh -m restore -b my-backup-bucket -v <vault_token> -p <GCP_projectID> -r my-bucket-to-restore -d 8-06-2020
Pour les 2, il faut un vault token. C’est un token qui permet de se connecter à Vault et de récupérer la clé du service-account.
Pour générer ce vault token, plusieurs possibilités s’offrent à vous, dont l’authentification par LDAP :
VAULT_ADDR=https://<VAULT_URL> vault login -method=ldap username=<LDAP_USERNAME>
Si vous ne stockez pas la clé du service account dans Vault, il faudra que vous adaptiez le script à votre cas d’usage.
Bilan
Pour mon cas d’usage, le versionning des fichiers dans mon bucket ne me suffisait pas comme méthode de sauvegarde. Je voulais un backup complet et quotidien. C’est ce que nous avons fait… et en utilisant uniquement des services proposés par Google Cloud Platform.
Maintenant vous en savez un peu plus sur :
- Les buckets (Google Cloud Storage), leurs différentes classes de stockage, la rétention et le cycle de vie des fichiers ;
- Pousser un évènement dans un topic Pub/Sub grâce à un job Google Cloud Scheduler ;
- Déclencher une fonction Google Cloud Function quand un nouvel évènement arrive dans un topic ;
- Créer un service-account, attribuer les droits sur un bucket et générer sa clé au format JSON pour l’utiliser dans un script.
Les backups sont des éléments indispensables dans le cadre d’un DRP (Disaster Recovery Plan). Nous pourrions imaginer un DRP multi cloud, et devoir restaurer notre backup de bucket chez un autre provider (AWS, Azure ou autre…). C’est ce que nous verrons dans un prochain article
Bibliographie
- Documentation sur les Service account : https://cloud.google.com/sdk/gcloud/reference/iam/service-accounts
- Utiliser IAM pour la gestions des droits d’un bucket: https://cloud.google.com/storage/docs/access-control/using-iam-permissions?hl=fr#gsutil_2
- Documentation GSUTIL: https://cloud.google.com/storage/docs/gsutil?hl=fr
- Documentation Pub/Sub: https://cloud.google.com/functions/docs/tutorials/pubsub
- Documentation Scheduler: https://cloud.google.com/scheduler/docs/quickstart

