Vous avez installé Prometheus Operator dans votre cluster Kubernetes et vous vous demandez comment y brancher les exporters ? Vous avez frappé à la bonne porte. Cet article expose le mode de fonctionnement de l’opérateur Prometheus et explique sa mise en place et comment brancher les applications dessus au travers d’un exemple.
Les ingrédients de la réussite
Pour réaliser cette recette, nous aurons besoin :
- d’un cluster Kubernetes avec au moins 2 vCPU et 6 Go RAM
- du package manager Helm
- …et c’est tout
L’article a été rédigé sur base des versions suivantes :
- Kubernetes 1.14.7
- Helm 2
- Prometheus Operator 0.32
Nous aborderons au fil de l’article les objets Kubernetes suivants :
- Objets classiques :
- Pods, Deployment, Service
- Objets propres à Prometheus :
- Custom Resource Definition (CRD)
- Prometheus
- Prometheus Rule
- Service Monitor
- Alert Manager
- Pod Monitor
- Custom Resource Definition (CRD)
Architecture de Prometheus
Prometheus permet de collecter les métriques exposées par les applications ou celles qui lui sont envoyées. Les métriques sont persistées sur disque dans le format TSDB et sont requêtables au travers de l’outil. Il est possible de connecter Grafana aux données pour créer des graphes et des dashboards à thème.
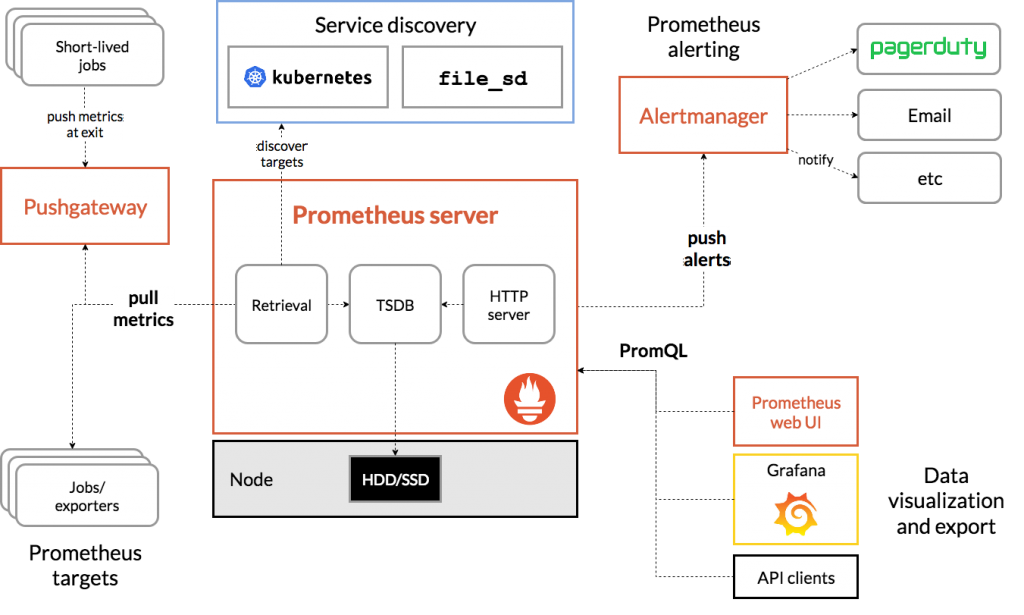
L’architecture Prometheus fonctionne au travers des briques suivantes :
- Prometheus server : agrège et stocke les métriques collectées ;
- Service Discovery : récupère à chaud les endpoints/targets où collecter les métriques ;
- Push Gateway : met à disposition une API où les applications peuvent exporter elles-mêmes leurs métriques, notamment utiles pour les applications restreintes ou les batchs applicatifs ;
- Alert Manager : permet de définir des alertes sur base de seuils et d’envoyer des notifications vers d’autres services (email, Slack, …) ;
- Grafana : permet de visualiser les métriques collectées à l’aide de graphes ;
- Exporter : récupère localement les métriques applicatives et les expose sur un endpoint/target.
La notion de target (ou endpoint) définit l’URL mise à disposition (par l’application) pour permettre à Prometheus de récupérer les métriques exposées.
Quelques explications
Kubernetes Operator
Kubernetes fournit de base une palette d’objets tels que le Pod, Deployment, ReplicatSet, Service, Ingress, CronJob, etc…
Ces objets natifs adoptent un comportement plutôt applicatif, au travers desquels il devient facile de publier une application (notamment grâce aux Pod, Service et Ingress).
Cependant, ces objets ne s’adaptent pas à toutes les problématiques. Bien entendu, on peut tout réaliser avec ces objets mais l’effort à déployer peut parfois être démesuré compte tenu de l’avantage qu’ils apportent.
C’est dans cette optique que Kubernetes permet de créer des objets personnalisés au travers de l’entité Custome Resource Definition (CRD).
Pour illustrer le propo, les objets de base conviennent parfois moins au contexte technique. Nous nous figurons dans ce schéma où l’intégration de Prometheus sur les modules applicatifs est plus simple grâce aux CRDs contre l’instanciation d’un Prometheus classique.
Pour aller au fond des choses, les objets CRD créés sont accessibles et altérables au travers de l’API de Kubernetes : api-server. C’est ce composant qui créé toute la personnalisation et l’indépendance des objets dans le cluster.
Vous pouvez lister les CRDs disponibles à l’aide de la commande suivante :
kubectl get crd
Prometheus Operator
Dans un schéma traditionnel, la récupération des métriques applicatives nécessite de modifier la configuration de Prometheus, ce qui permet d’informer l’outil de l’ajout d’un endpoint (=target) où collecter les informations.
Prometheus peut s’installer au travers d’un Operator. Cette méthode va créer des objets spécifiques, utiles uniquement à Prometheus, pour découvrir dynamiquement les endpoints, collecter les métriques et les stocker dans sa base.
L’outil Prometheus utilise les CRDs pour créer les objets suivants :
- Prometheus : instance qui agrège les métriques déjà collectées pour les insérer en base ;
- Prometheus Rule : la liste des règles définies et le système de chargement de la configuration à chaud (hot-reload) ;
- Service Monitor : la sonde Prometheus qui pointe sur les Services (objet Kubernetes) afin d’y collecter les métriques ;
- Alert Manager : instance qui gère les alertes sur les expressions définies en fonction des seuils ;
- Pod Monitor : la sonde Prometheus qui pointe sur les Pods (objet Kubernetes) afin d’y collecter les métriques.
Ces CRDs génèrent des APIs dans le cluster Kubernetes requêtables avec la commande kubectl get crd :
NAME CREATED AT alertmanagers.monitoring.coreos.com 2020-01-20T23:09:28Z prometheuses.monitoring.coreos.com 2020-01-20T23:09:46Z prometheusrules.monitoring.coreos.com 2020-01-20T23:11:53Z servicemonitors.monitoring.coreos.com 2020-01-20T23:11:06Z podmonitors.monitoring.coreos.com 2020-01-20T23:12:21Z
Prometheus peut s’installer de 2 manières : avec ou sans la création de CRDs, (objets propres à Prometheus).
Soyons clair, il est parfaitement possible, valide et convenable d’installer Prometheus au travers d’une installation classique. La “seule” contrainte qui va s’imposer se trouve sur le rattachement automatique des métriques applicatives et leur collecte dans la base Prometheus.
Les objets Monitor
Prometheus Operator utilise la notion de Monitor pour collecter les métriques nécessaires. Cette notion réside dans le fait d’abstraire aux applications la configuration d’export des métriques ainsi qu’à Prometheus la configuration des endpoints.
La création d’un Monitor va automatiquement re-configurer Prometheus, il n’est donc plus nécessaire de toucher à la configuration. Ce qui permet de gagner du temps sur sa mise à place, sur les erreurs potentielles, sur le mauvais paramétrage et les adresses erronées.
Le Monitor est apporté avec Prometheus Operator grâce aux CRDs qu’il installe sur le cluster. Il existe plusieurs types d’objets Monitor pour d’adapter à toutes les situations :
PodMonitor: s’applique sur les pods Kubernetes ;ServiceMonitor: s’applique sur les services Kubernetes.
L’utilisation de l’un ou l’autre réside dans le mode d’utilisation de l’application.
- Un site web WordPress utilise l’objet Deployment pour instancier les pods, ainsi que les objets Service et Ingress pour les exposer au monde entier. Cette configuration peut utiliser les 2 type de Monitor : ServiceMonitor et PodMonitor.
- Le middleware Kafka s’instancie via un StatefulSet et nécessite d’exposer (non plus le port 80/443 du cluster mais) un port physique du Worker pour être directement sollicité (aucun objet Service). Cette configuration peut uniquement utiliser le type PodMonitor étant donné que les pods sont directement attaqués.
Le selector de Monitor
Prometheus est nativement configuré pour récupérer les métriques exposées par les PodMonitor et ServiceMonitor ayant le labelrelease: Prometheus.
Cette configuration est très contraignante, surtout si vous installez vos applications avec Helm, qui utilise également ce même label pour marqué les objets.
Nous allons donc ajouter une configuration pour avoir la main sur les Monitor déployés.
On va demander à Prometheus de récupérer tous les Monitor (en plus des précédents) qui possède le label suivant :prometheus.io/monitor: "true"
Pour se faire, il faut sensiblement modifier la configuration de Prometheus dès son installation. Modifier le fichier values.yaml du Helm Chart stable/prometheus-operator.
La mise en palce est détaillée dans la section suivante.
prometheus:
[...]
prometheusSpec:
serviceMonitorSelector:
prometheus.io/monitor: "true"
Une fois mis à jour, tous les ServiceMonitor ayant ce label seront récupérés et les métriques collectées.
La cible du selector Monitor
L’outil sait maintenant récupérer dynamiquement les Monitor qui comportent ce label. Il ne reste plus qu’à savoir comment ajouter ce label au Monitor qu’on héberge.
Sur les applications (Helm Chart) qui embarquent un endpoint Prometheus, la configuration se fait dans le fichier de values et une section est dédiée à la métrologie Prometheus sous le nom de metrics.
On peut facilement ajouter le label personnalité au ServiceMonitor qui sera déployé avec l’application :
metrics:
enabled: true
[...]
serviceMonitor:
enabled: true
additionalLabels:
prometheus.io/monitor: "true"
Une fois configuré et re-déployée, Prometheus sera en mesure de récupérer les métriques exposées par l’application.
Synthèse

Mise en place de Prometheus Operator
Installation
La mise en place de Prometheus Operator sur Kubernetes avec le Chart Helm Prometheus Operator embarque la suite Prometheus ainsi que Grafana et fournit également des Dashboards par défaut pertinents et utiles.
L’architecture de l’outil reste la même sur l’approche applicative. Elle apporte cependant son lot de nouveautés sur la partie Kubernetes où de nouveaux objets sont spécialement créés pour son fonctionnement interne (cf. CRD à la section précédente).
Nous allons installer le Prometheus Operator avec les caractéristiques suivantes :
- Exposer l’adresse de Grafana : grafana.ineat-group.com
- Accéder à Prometheus : prometheus.ineat-group.com
- Parcourir Alert Manager : alertmanager.ineat-group.com
A partir des caractéristiques souhaitées, nous pouvons formaliser le fichier values.yaml suivant :
alertmanager:
enabled: true
ingress:
enabled: true
hosts:
- alertmanager.ineat-group.com
prometheus:
ingress:
enabled: true
hosts:
- prometheus.ineat-group.com
grafana:
enabled: true
ingress:
enabled: true
hosts:
- grafana.ineat-group.com
Installons l’outil à présent :
helm install --name prometheus-operator --namespace monitoring -f values.yaml stable/prometheus-operator
Une fois l’outil installé, vous pouvez consulter les métriques sur l’interface de Prometheus et créer des dashboards sur l’interface Grafana.
Utilisation
Rendez-vous sur l’interface Grafana et connectez-vous : admin/prom-operator.
Vous pouvez parcourir les dashboards déjà créés :
- Kubernetes / API server : affiche les métriques relatives à l’API Sever telles que le taux de sollicitation, les flux réseau, la consommation CPU et RAM, etc… ;
- Kubernetes / Pods : affiche les métriques des pods (unitairement) comme l’utilisation CPU et RAM, les I/O réseau et le nombre de restarts des pods ;
- Kubernetes / Compute Resources / Namespace (Pods) : affiche les métriques des pods d’un même namespace (paramétrable) ;
- etc…
Et créer les vôtres avec des graphes adaptés à vos besoins.
Nettoyer
Pour supprimer l’outil, vous devez désinstaller le helm chart et supprimer manuellement les CRDs générés :
helm delete --purge prometheus-operator kubectl delete --ignore-not-found customresourcedefinitions \ prometheuses.monitoring.coreos.com \ servicemonitors.monitoring.coreos.com \ podmonitors.monitoring.coreos.com \ alertmanagers.monitoring.coreos.com \ prometheusrules.monitoring.coreos.com
Ajouter des métriques externes
Nous allons partir du principe que votre application permet de remonter des métriques de type Prometheus (vous allez vite comprendre pourquoi).
Toutes les applications que nous créons ne sont pas éligibles nativement aux métriques Prometheus.
Mais pourquoi ??!!!
Parce qu’on ne leur a pas dit de le faire tout simplement.
En revanche, quand vous prenez une application développée par la communauté open source, vous allez très régulièrement trouver un endpoint Prometheus associé, pratique non ?
Nous allons, dans cette partie, utiliser une application qui expose déjà un endpoint compatible avec Prometheus. Cette application est toute simple et s’appelle WordPress.
Exemple avec WordPress
WordPress est un CMS qui facilite la mise en place d’un site, qu’il soit vitrine ou e-commerce.
WordPress est codé en PHP, il ne peut donc pas être autonome pour fonctionner, il a besoin d’un middleware intermédiaire pour interpréter le langage. Dans notre cas, WordPress se base sur le moteur Apache pour exposer son code aux utilisateurs.
Etant donné que nous sommes dans l’univers des conteneurs, l’application se base sur une image pré-construite pour se lancer.
- L’image est disponible sur le Dockerhub
- Bitnami met également à disposition une image WordPress basée sur le code de l’image de base présentée juste au-dessus
Chart Helm
Une image c’est bien, un chart c’est mieux !
L’image Docker ne nous fournit pas toute la configuration de l’application, et notamment la mise à disposition d’une base de données éphémère. Le chart Helm fournit cela et bien plus encore.
Le Chart Helm est disponible à cette adresse : https://github.com/helm/charts/tree/master/stable/wordpress
Jetez un oeil aux paramètres et créez votre fichier values.yaml pour ajuster la configuration.
Sinon vous pouvez parfaitement installer le chart tel qu’il est :
helm install --name wordpress --namespace wordpress stable/wordpress
Le tour est joué, vous avez une application WordPress qui tourne !
Sidecar metrics
Dans l’univers Docker, un sidecar est un conteneur rattaché au conteneur principal qui n’impacte pas directement l’application mais fournit certaines fonctionnalités (hot-reload de configuration, traitement externe programmé, exposition interne de données).
Le conteneur sidecar vit sa propre vie. Si il vient à tomber, l’application ne sera pas impactée par ce drame technologique.
Dans notre cas, le sidecar sert à exposer les métriques techniques de WordPress sans pour autant être exposées au monde entier. La dissociation de wordpress et du sidecar réside également dans l’utilisation des ressources systèmes et l’impact de l’un sur l’autre.
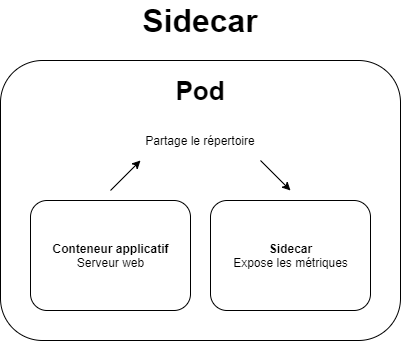
Pour notre plus grand bonheur, le chart Helm de WordPress fournit l’application WordPress, une base de données interne et le sidecar des métriques.
Attention ! Ne vous vous attendez pas à ce que le sidecar vous remonte des métriques fonctionnelles ou métiers, tout dépend de sa configuration. Dans le cas de WordPress, les métriques collectées sont purement techniques et sont en lien direct avec le middleware Apache.
Dans le langage Prometheus, le sidecar qui collecte les métriques s’appelle un exporter en anglais ou exporteur en français.
Exporter Prometheus
Le sidecar metrics mis à disposition dans le chart de WordPress fournit un endpoint compatible avec Prometheus. A la bonne heure !!!
- Le chart WordPress embarque un apache exporter
- Bitnami a également mis à disposition son apache exporter
L’exporter Apache collecte les métriques en lien avec :
- L’utilisation CPU
- L’utilisation des workers Apache
- Les accès direct au site
- La quantité de données envoyée
Il ne nous reste plus qu’à connecter Prometheus pour qu’il collecte les métriques exposées.
Prometheus Operator
Forts de ce que l’on a vu sur la théorie plus haut dans cet article, nous pouvons maintenant le mettre en place pour notre cas.
Quelques rappels préalables :
- L’objet Prometheus récupère les métriques exposées par les objets
ServiceMonitoret se base sur l’instructionserviceMonitorSelectorpour les cibler ; - L’objet
ServiceMonitorrécupère les métrique exposées par lesPodsvia un service et se base sur l’instructionselectorpour les cibler.
Configuration de WordPress
Il ne nous reste plus qu’à configurer le chart WordPress pour qu’il soit visible de Prometheus.
Dans le fichier values.yaml, la section metrics est dédiée aux métriques exposées par l’application.
On peut simplement exposer le endpoint et demander manuellement à Prometheus de collecter les données. Ou alors d’activer le ServiceMonitor pour que le Prometheus se configure comme un grand et récupère de lui même les métriques exposées, c’est ce qui nous intéresse ici.
Voici la section du values.yaml qui nous intéresse :
metrics:
enabled: true
image:
registry: docker.io
repository: bitnami/apache-exporter
tag: 0.7.0-debian-9-r50
pullPolicy: IfNotPresent
podAnnotations:
prometheus.io/scrape: "true"
prometheus.io/port: "9117"
serviceMonitor:
namespace: "wordpress"
additionalLabels:
prometheus.io/monitor: "true"
On retrouve plusieurs sous-section qui vont nous permettre d’ajuster au mieux la configuration :
- enabled : création/activation du sidecar de metrics ;
- image : récupération de l’image liée à l’apache exporter ;
- podAnnotations : les annotations ajoutées au pod qui serviront à affiner la configuration de Prometheus
- *prometheus.io/scrape : autorise Prometheus a collecter les métriques des pods ;
- prometheus.io/port : modifie le port par défaut de collecte des métriques Prometheus ;
- serviceMonitor : active la création de l’objet ServiceMonitor
- namespace : définit dans quel namespace créer l’objet ServiceMonitor
- additionalLabels : ajoute les labels au ServiceMonitor
* Attention, l’annotation
prometheus.io/scrapene fonctionne pas avec Prometheus Operator.
La partie podAnnotation permet de modifier le comportement par défaut de Prometheus vis-à-vis des Pods (où résident les sidecar metrics).
La partie ServiceMonitor définit où sera créé l’objet, et surtout le critère de visibilité qui permettra à Prometheus de le cibler (ou non) grâce à l’attribut serviceMonitor.additionalLabels.
Mise à jour de WordPress
Maintenant que la configuration est prête, il faut mettre à jour le chart sur le cluster Kubernetes.
helm upgrade wordpress stable/wordpress
Pour vérifier que la configuration est correcte et que les métriques remontent bien dans Prometheus, il faut aller jeter un oeil sur le dashboard de Prometheus : prometheus.ineat-group.com.
Rendez-vous dans le menu Status > Service Discovery :
Vous apercevrez, en plus des sondes déjà mises en place par l’Operator, une ligne dédiée aux métriques WordPress appelée “wordpress/wordpress/0” :
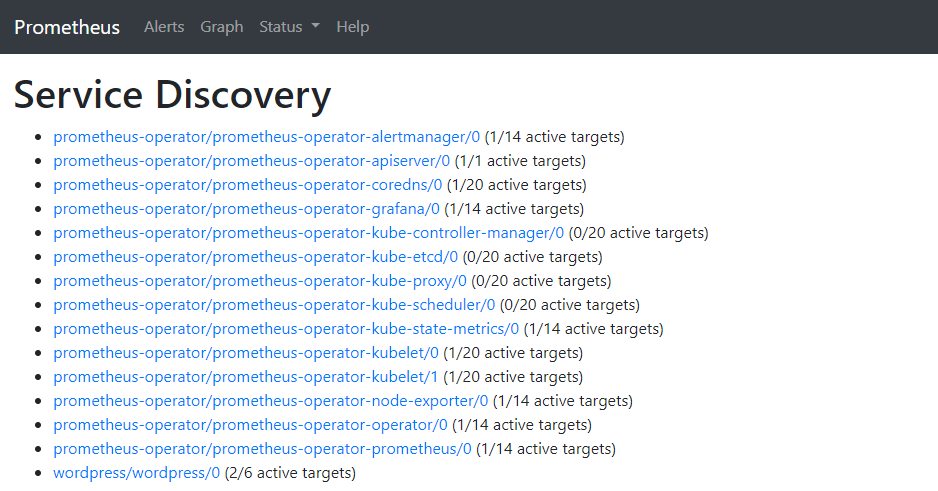
Si cette ligne s’affiche, c’est que vous avez correctement configuré la partie metrics de l’application. L’affichage est dynamique et la ligne apparaît toute seule sans devoir recharger la page.
Conclusion
Au travers de cet article, nous avons pu voir comment installer, configurer le Prometheus Operator et comment l’utiliser au travers d’un exemple compatible.
Vous savez dorénavant comment s’orchestrent les objets Prometheus et vous pourrez reproduire le schéma sur les applications que vous hébergez.
Bibliographie
Les sources des données utilisées tout au long de cet article sont précisées :

