Les “change stream” ou flux de changements en français, permettent aux applications d’accéder aux modifications de données en temps réel sans la complexité et le risque de suivre le journal des opérations. Les applications peuvent les utiliser pour s’abonner à toutes les modifications de données sur une seule collection, une base de données ou un déploiement entier, et y réagir immédiatement. Étant donné que les change streams utilisent le framework d’agrégation, les applications peuvent également filtrer des modifications spécifiques ou transformer les notifications à volonté. Elles sont proposées dans la version 3.6 et seulement disponibles pour les replicasets et le sharded clusters.
Nous allons dans cet article voir comment nous pouvons tirer profit des change streams à travers un cas d’utilisation de notifications pour application mobile.
Mais avant, faisons un petit tour d’horizon des caractéristiques de ces change streams.
Prérequis
- Les replicasets et les sharded clusters doivent utiliser le moteur de stockage WiredTiger.
- Les replicasets et les sharded cluster doivent utiliser le protocol pv1.
- Dans sa version 4.0 ou inférieure, les change streams sont disponibles seulement si la propriété
read concernest activée. Mongodb 4.2 fait l’impasse sur cette configuration et propose par défaut les change streams. - En production, il faut s’assurer que les applications ont les droits qui autorisent les actions
changestreametfind.
Ex: { resource: { db: , collection: }, actions: [ “find”, “changeStream” ] }
Un peu de théorie
Avant MongoDB 3.6, si nous voulions écouter ce qui changeait dans notre déploiement MongoDB, vous devions consulter la collection “oplog”, utilisée dans la réplication qui enregistrait les changements. Le processus de consultation de cette collection peut souvent aboutir à un code complexe, non pris en charge et peu robuste (chose que nous ne souhaitons pas voir en production).
Écouter les changements
Nous pouvons être notifiés des changements d’une collection, à l’exception de celles de system, et toutes autres collections dans local, admin et config.
Il est également possible d’écouter les changements d’une base de données entière ou d’un cluster, avec les même restrictions que pour une collection. Ex: dropDatabase, rename, etc.
Modifier les données de sorties d’un change stream
La modification des données de sortie d’un change stream se fait avec les pipelines d’agrégations. Les opérateurs suivants sont disponibles dans la version 4.2 de mongodb:
$addFields$match$project$replaceRoot$replaceWith$redact$set$unset
Des exemples sont disponibles ici.
Démarrer un change stream
Nous pouvons démarrer un change stream en utilisant simplement la fonction watch sur une collection mais aussi les fonctions resumeAfter et startArfter en leur passant un token disponible dans chaque événement de changement. Deux points d’attention :
- La fonction resumeAfter n’est pas possible après un événement invalide.
- La fonction startAfter démarre un nouveau change stream à partir du token passé en paramètre et s’applique même après un événement invalide.
Les événements de changements
Lorsqu’un changement intervient sur une collection, une notification ayant la structure suivante est générée :
{
_id : { <BSON Object> }, // l'identifiant qui contient le token
"operationType" : "<operation>", // le type de changement
"fullDocument" : { <document> }, // le document entier après changement, non renseigné si operation de delete
"ns" : {
"db" : "<database>", // la base de données concernée
"coll" : "<collection>" // la collection concernée
},
"to" : {
"db" : "<database>", // le nouveau nom de la base de données si renommage
"coll" : "<collection>" // le nouveau nom de la collection si renommage
},
"documentKey" : { "_id" : <value> }, // la clé du document qui a subit le changement
"updateDescription" : { // uniquement, si c'est une opération d'update
"updatedFields" : { <document> }, // les champs qui ont été modifiés
"removedFields" : [ "<field>", ... ] // les champs qui ont été supprimés
}
"clusterTime" : <Timestamp>, //
"txnNumber" : <NumberLong>, // le numéro de transaction
"lsid" : { // l'identifiant de session
"id" : <UUID>,
"uid" : <BinData>
}
}
Les types d’événements
- insert, créé lorsqu’un nouveau document est inséré dans une collection
- update, lorsque une mise à jour est effectuée sur un document d’une collection. Attention, les GUI mongodb font du
replaceplutôt que duupdatemême si on modifie uniquement un champ. - replace, lorsque l’on supprime un document puis on l’insert à nouveau avec la même clé.
- delete, lorsqu’un document est supprimé
Les événements ci-dessus sont ceux créés lorsqu’il y a une modification sur un document. D’autres types d’événements liés aux changements intervenant sur une base de données ou sur une collection existent.
Cas d’utilisation
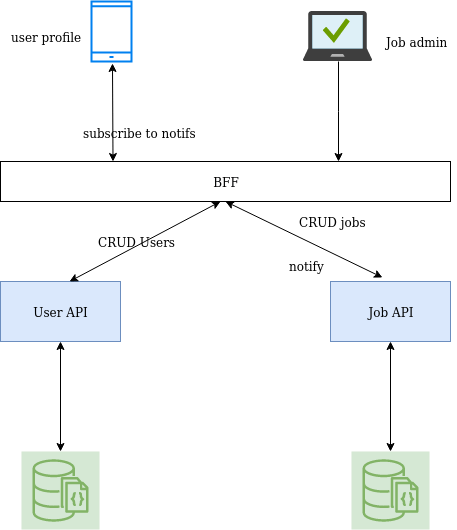
Imaginons que nous souhaitions créer un application permettant à un utilisateur de recevoir une notification lorsqu’un nouvel emploi est référencé par une entreprise X.
Deux services sont en charge de chaque besoin : l’un aura pour mission de gérer les utilisateurs et l’autre gérera les offres d’emploi et pourra émettre des notifications à destination d’un utilisateur (en fonction de son métier).
Voici ce que ça donne:
Nous allons ici utiliser Java, Spring boot, Mongodb, Docker, docker-compose. Assurez-vous de maîtriser un minimum ces technologies avant d’aller plus loin 🙂
Déploiement d’un replica set mongodb en local
Nous allons commencer par créer un fichier docker-compose.yml avec le contenu ci-dessous dans un répertoire de notre choix.
version: '3.6'
services:
# MongoDB Replica Set
mongo1:
image: "mongo:4.2.5-bionic"
container_name: mongo1
command: --replSet rs0 --oplogSize 128
volumes:
- rs1:/data/db
networks:
- localnet
ports:
- "27017:27017"
restart: always
mongo2:
image: "mongo:4.2.5-bionic"
container_name: mongo2
command: --replSet rs0 --oplogSize 128
volumes:
- rs2:/data/db
networks:
- localnet
ports:
- "27018:27017"
restart: always
mongo3:
image: "mongo:4.2.5-bionic"
container_name: mongo3
command: --replSet rs0 --oplogSize 128
volumes:
- rs3:/data/db
networks:
- localnet
ports:
- "27019:27017"
restart: always
networks:
localnet:
attachable: true
volumes:
rs1:
rs2:
rs3:
Rendez-vous ensuite dans ce répertoire et exécutez la commande :
docker-compose up -d
Pour configurer notre replica set nous devons exécuter la commande suivante:
docker-compose exec mongo1 /usr/bin/mongo --eval '''if (rs.status()["ok"] == 0) {
rsconf = {
_id : "rs0",
members: [
{ _id : 0, host : "mongo1:27017", priority: 1.0 },
{ _id : 1, host : "mongo2:27017", priority: 0.5 },
{ _id : 2, host : "mongo3:27017", priority: 0.5 }
]
};
rs.initiate(rsconf);
}
rs.conf();''
Création de notre service user API
Ce service aura pour simple rôle de permettre de créer, modifier et supprimer des utilisateurs. Voici donc les dépendances dont nous avons besoin
Ce lien vous aidera à initialiser le projet.
Une fois le projet créé, nous allons configurer une base mongodb et le repository user pour exposer une api CRUD.
Rajoutons dans le fichier application.properties les lignes suivantes :
spring.data.mongodb.uri=mongodb://localhost:27017 spring.data.mongodb.database=changestreams_users_db
Puis créons la classe entity User et le repository spring data Rest correspondant :
@Data
@NoArgsConstructor
@AllArgsConstructor(access = AccessLevel.PRIVATE)
@With
@Document(collection = "users")
public class User {
@Id
private String id;
private String name;
private String jobTitle;
}
@RepositoryRestResource(collectionResourceRel = "users", path = "users")
public interface UserRepository extends MongoRepository<User, String> {
}
Et voilà le tour est joué, nous venons de créer une api CRUD pour notre besoin grâce à la puissance de “Spring data REST” !
Création de notre service job API
Ce lien vous aidera à initialiser le projet.
Nous constatons ici l’ajout de la dépendance spring data reactive mongodb. En effet, dans ce service, utiliser le “driver” réactif de mongodb facilitera grandement le streaming des change streams et permettra d’exposer de l’event streaming en sortie de notre API.
Comme pour l’api user, nous spécifions le nom de notre base de données ainsi que l’uri de connexion.
server.port=8081 spring.data.mongodb.uri=mongodb://localhost:27017 spring.data.mongodb.database=changestreams_jobs_db
Création du service de streaming des jobs
@Slf4j
@Service
@RequiredArgsConstructor(onConstructor = @__(@Autowired))
public class JobChangeStreamService {
private final ReactiveMongoTemplate reactiveMongoTemplate;
public Flux<Notification> watchForJobsCollectionChanges() {
ChangeStreamOptions options = ChangeStreamOptions.builder()
.filter(newAggregation(Job.class, match(where("operationType").in("insert"))))
.build();
// return a flux that watches the changestream and returns a notification object
return reactiveMongoTemplate.changeStream("jobs", options, Job.class)
.filter(Objects::nonNull)
.map(event -> event.getRaw())
.map(doc -> new Notification()
.withType(doc.getOperationType().getValue())
.withJob(doc.getFullDocument())
)
.doOnNext(notification -> log.info("{}", notification))
.doOnError(throwable -> log.error("Error with the jobs changestream event: " + throwable.getMessage(), throwable));
}
}
Et pour finir un contrôleur pour exposer la ressource
@GetMapping("/jobs/watch")
public Flux<ServerSentEvent<Notification>> watchJobAdded() {
return jobChangeStreamService.watchForJobsCollectionChanges()
.map(job -> ServerSentEvent.<Notification>builder()
.data(job)
.build()
);
}
A noter qu’ici on retourne un flux d’objets ServerSentEvent, facile à exploiter avec des frameworks comme Angular et React.
Et voilà, nous sommes notifiés chaque fois qu’un job est ajouté.
Pour aller plus loin, on pourrait imaginer que l’utilisateur souscrit uniquement à un tag, et chaque fois qu’un job de ce tag est ajouté, il en est notifié.
Pour ce faire il suffit de modifier notre pipeline comme suit:
[{
$match: {
$and: [
{ "fullDocument.tag": "montag" },
{ operationType: "insert" }
]
}
}],
Conclusion
Dans cet article nous avons vu comment générer facilement des notifications pour une application plutôt simple.
Peu importe la qualité de votre réseau, il y aura des situations où les connexions échoueront. Pour vous assurer qu’aucune modification n’est manquée dans de tels cas, vous devez ajouter du code pour le stockage et la gestion de resumeTokens.
En cas de panne, le driver doit automatiquement effectuer une tentative de reconnexion. L’application doit gérer d’autres tentatives si nécessaire. Cela signifie que l’application doit prendre soin de toujours conserver le resumeToken.
Pour cela les fonctions resumeAfter et startAfter vous serons d’une grande aide.
Dans une application plus complexe avec beaucoup d’utilisateurs connectés et le besoin de connaître les notifications manquées, on pourra mettre en place une stack, avec Kafka par exemple, il est possible d’utiliser les change streams Mongo pour d’autres besoins (ceci fera l’objet d’un autre article ;)).
Liens utiles
Code source du cas d’utilisation

