Introduction
Notre participation au Config Management Camp 2020 nous a inspiré, à tel point qu’un article entier a été dédié à une conférence qui nous a marqué : Cloud native configuration management.
Vous pouvez retrouver notre retour sur la conférence générale ici.
Cet article relate l’état de l’art du Cloud native configuration management, c’est-à-dire les outils de configuration éligibles au cloud.
La conférence
La conférence de la journée était animée par Eric Sorenson, développeur chez Puppet, qui nous présente sa vision du Config Management en 2020 et au delà.

Eric a présenté le projet sur lequel il travaille actuellement : Project Nebula ; qui vise à simplifier le déploiement des applications sur les cloud providers.
L’animateur a présenté sa vision de la gestion de la configuration et des environnements. Il a exposé plusieurs théories simples qui visent à identifier et qualifier la maturité du contexte et des outils de gestion de configuration.
The 12-factors app
Beaucoup d’entre nous connaissent les 12 facteurs et ce qu’ils impliquent dans notre métier de tous les jours.
Ce schéma, quoi que complexe de prime abord, résume en réalité très bien les phases d’un projet de développement.
Il introduit même des notions de manière visuelle, chose que la plupart des guidelines en ligne ne mentionnent pas systématiquement.
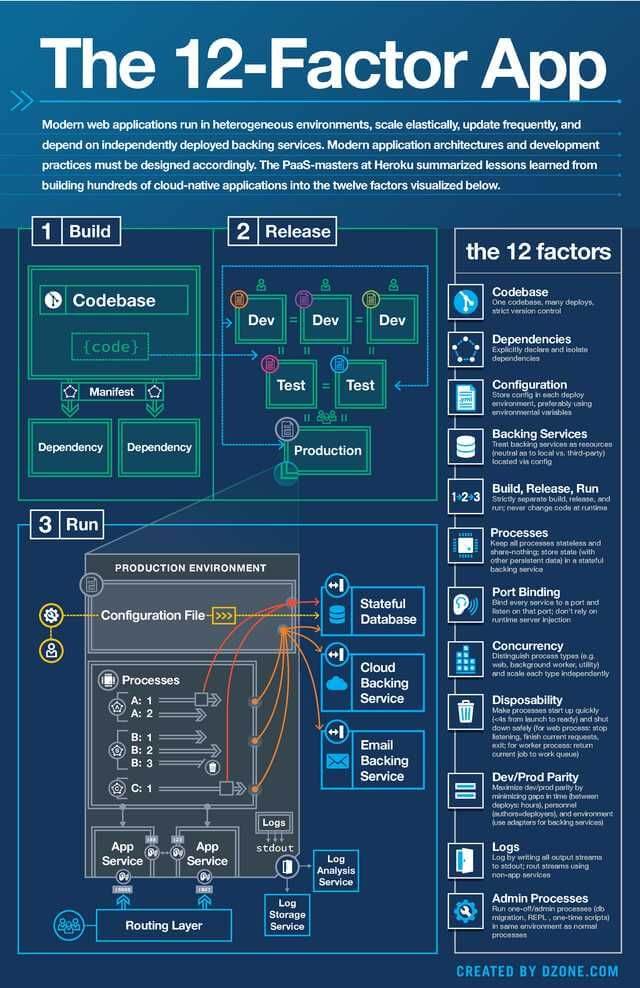
Ces facteurs introduisent les notions plus globales qui s’appliquent à la gestion de la configuration vis-à-vis des environnements via les déploiements :
Ephemerality
L’aspect temporel d’un environnement provient ou fait suite à la facilité à produire et reproduire un environnement consistant. Plus la génération est rapide et l’importance accordé à l’environnement est faible, plus il est dit éphémère. On retrouve ici le schéma dessiné par le conflit de tout SI : “Pet VS Cattle”.
Cardinality
La relation entre les éléments et leur dissociabilité constituent la cardinalité. Plus les composants d’une application sont éclatés dans un environnement, plus la cardinalité est forte.
Ainsi une application 3-tiers qui s’étale sur 3 serveurs (front, api, database) saura découpler le trafic sur chaque élément. Les mises à jour seront plus simples et les erreurs de découplage (le fameux localhost) sont impossibles.
Immutability
L’immutabilité permet de mesurer la reproductibilité de l’environnement à l’identique. Les environnements reproductibles, donc immutables, sont très souvent éphémères, et inversement. Cependant, certaines applications requièrent des modifications manuelles et humaines, mutant donc l’environnement applicatif.
Data…bility
Quelle est l’importance de la données pour une application ? Avec quelle facilité est-elle reproductible sur les différents environnements ? Ces questions permettent de mesurer la “Datability” qu’énonce Eric.
Le lien que crée la donnée avec l’application est compliquée et le sera encore plus avec le temps. Avec le temps, les base de données se complexifient, les modèles de données également.
Ce qui peut faire changer la donne est de prendre de l’avance sur la portabilité des données et créer des modèles portables, adaptables et reproductibles en tous temps et sur tous supports. Ces recommandations semblent évidentes, mais reposez-vous ces questions quand votre application aura passé sa première année en production. Vous pourriez être très surpris.
Courbe de complexité de la configuration
L’échelle de la complexité a été énoncée par Mike Hadlow et Cedric Charly et permet de positionner la constitution d’un outil de configuration sur une échelle relativement basique, mais tellement efficace.
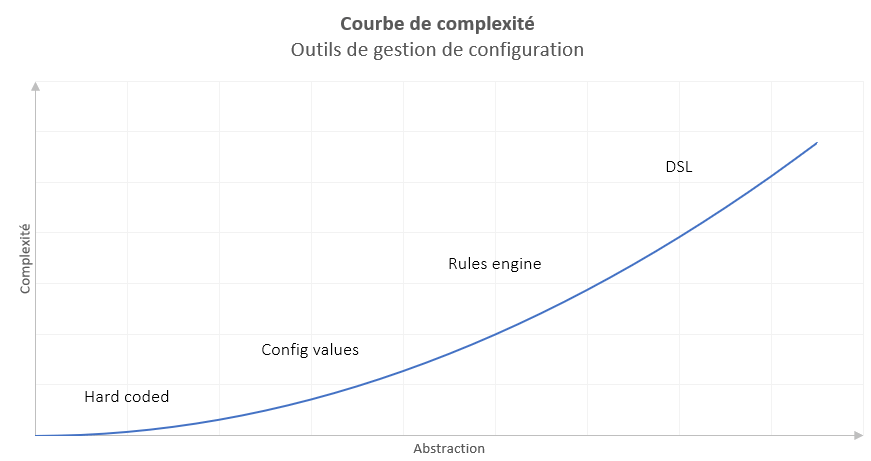
Ce graphe mérite quelques explications :
- Les outils maisons sont simples à réaliser sur des petits échantillons, mais non-envisageables sur des grosses configurations (contraintes de temps et de reprise par autrui) ;
- L’abstraction des outils DSL rendent l’écriture simple ;
- Mais la forte abstraction rend la compréhension difficile des actions appliquées par la configuration.
Il est donc important de bien choisir son outil en fonction des critères suivants :
- Niveau des utilisateurs qui opèrent ;
- Niveau d’abstraction souhaité ;
- Flexibilité dans l’outil et facilité à tordre le modèle de base ;
- Facilité à transposer la description vers l’action réalisée.
Taxonomie des outils de configuration cloud natifs
Les outils de configuration apportent leurs lots de complexité qui viennent avec les concepts introduits.
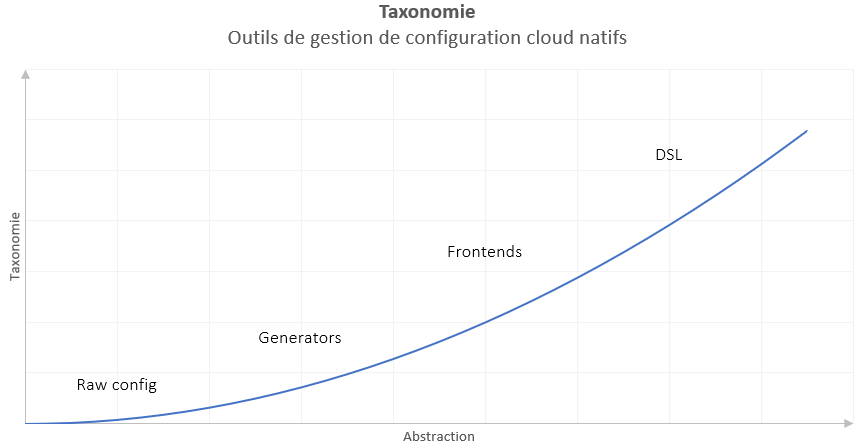
De manière logique, plus les outils apportent une couche d’abstraction, plus ces outils introduisent des nouveaux objets et concepts.
La première partie de cette première conférence rapportait sur l’état de l’art et la définition des bases de mesure sur la “configuration management”.
Cloud native configuration management : Beyond
Maintenant que les présentations sont faites, Eric Sorenson entre dans le vif du sujet et présente les outils avec leur potentiel avenir.
Kapitan
Kapitan est un outil de simplification de management de configurations servant au templating de celles-ci.
En utilisant une source unique “d’inventairisation” des ressources, basée sur “reclass” (recursive external node classifier), un seul point d’entrée est mis à disposition pour les différents outils qui seront utilisés pour le projet, tels que Kubernetes ou Terraform.
Kapitan utilise du Jsonnet, du Jinja2 ou du Kadet afin de créer les templates en Json ou YAML qui seront utilisés par nos outils ; mais l’outil permet aussi de générer la documentation associée aux cibles des déploiements qui sont effectués.
Kr8.rocks
Kr8.rocks est un outil permettant de générer des manifestes de composants Kubernetes pour les lier aux clusters qui leur seront associés, lesquels seront déployables.
Originellement, les composants pouvaient se résumer à un manifeste YAML ou un Chart Helm écrit en dur ; Kr8 fournit un moyen de gérer et d’adapter les différences de configuration en fonction du composant (ou du cluster Kubernetes) grâce au Jsonnet, qui leurs donne une forme de variabilisation.
Tanka
Tanka, une création open-source de Grafana Labs, est basé égaleme,t sur le langage Jsonnet pour créer des composants Kubernetes. Ayant pour optique de gérer la configuration des clusters, l’outil fourni une librairie intuitive d’utilisation pour remplacer les appels API habituels pour communiquer avec Kubernetes.
Initialement prévu pour complémenter l’outil “ksonnet” et permettre une modularité au niveau des configurations (contrairement au yaml statique), il remplace désormais celui-ci dont le projet à été interrompu.
Helm
Helm est l’outil le plus répandu et utilisé pour déployer programmatiquement sur Kubernetes. Simple d’utilisation, il se base sur des “Charts” en YAML pour déployer des stacks applicatives sur un cluster.
En proposant un système de templating et de dépendances, Helm fourni une configuration dynamique des ressources Kubernetes et déploie de manière fluidifiée les pods en passant par l’API de Kubernetes directement.
Pulumi
Pulumi est un gestionnaire d’infrastructure utilisant des langages de programmation contrairement à son homologue Terraform qui se base sur du Yaml. Ecrit initialement pour du TypeScript, il se décline dans les langages .NET, Python ou Go.
A l’instar de son concurrent, Pulumi permet de déployer sur les principaux fournisseurs de Cloud grâce à un système d’état (objet présent ou non).
Gyro
Gyro est un outil d’Infrastructure as Code et de configuration management opensource. Utilisant son propre langage, il permet de déployer et gérer les configurations des services Cloud, mais fournit aussi des workflows permettant de mieux contrôler les actions effectuées par celui-ci.
Un des avantages de Gyro nous permet de créer nos propres commandes dans l’outil ou encore ajouter nos propres providers clouds grâce au langage gyro extensible.
Cue
Cuelang (CUE pour les intimes : Configure, Unify, Execute) est un langage similaire au Jsonnet, basé sur du texte, permettant de configurer et surtout de valider les syntax des données qui seront utilisées en tant que Template par CUE.
Comme son SLUG l’indique, le principe de Cuelang est d’unifier, tester et valider la configuration de données en CUE, YAML ou JSON ainsi que d’automatiser leur utilisation grâce à un schéma unique.
Conclusion
Vous avez du remarquer au travers cet article combien le contenu est riche et d’actualité.
La section “théorique” permet de mieux visualiser les types d’outils et la section “technique” présente une large panoplie d’outils du marché.
Pour rappel, l’article général de la conférence est à retrouver ici.