Vous souhaitez commencer Kubernetes et vous êtes perdu parmi la masse d’informations provenant d’internet ? Cet article est fait pour vous !
Mon but est de vous donner une vision simple mais claire de Kubernetes en faisant nos premiers pas ensemble. Je me suis moi-même retrouvé dans cette situation où internet (magnifique outil soit dit en passant) m’a noyé d’informations et ne m’a pas directement permis de me propulser sur Kubernetes (à mon grand désarroi). J’ai passé des heures à parcourir, tester, visualiser, clarifier et élucider les concepts et pratiques que nombre de blogs tentent d’exposer.
Kubernetes, qu’est-ce que c’est ?
Kubernetes est un orchestrateur de conteneurs. Il ne se substitue pas à Docker, ils sont même complémentaires.
Docker fournit la virtualisation de type conteneur, met à disposition les variables d’environnement des conteneurs, permet de construire les images Docker, etc.
L’orchestrateur Kubernetes fournit la couche de résilience au dessus de Docker, met en cluster plusieurs serveurs Docker, permet le déploiement blue/green, l’isolation des comptes de service…
Kubernetes fournit ainsi un panel d’outils qui facilitent la mise en place d’infrastructures virtualisées autour de Docker.
Le flot d’informations
Kubernetes possède une multitude d’objets plus ou moins d’actualités et plus ou moins utilisés, ce qui amène à perdre une partie des lecteurs dans les blogs. Nous allons ici nous concentrer sur les objets basiques de Kubernetes, ceux qui vont vous permettre de commencer par le début.
Le fonctionnement
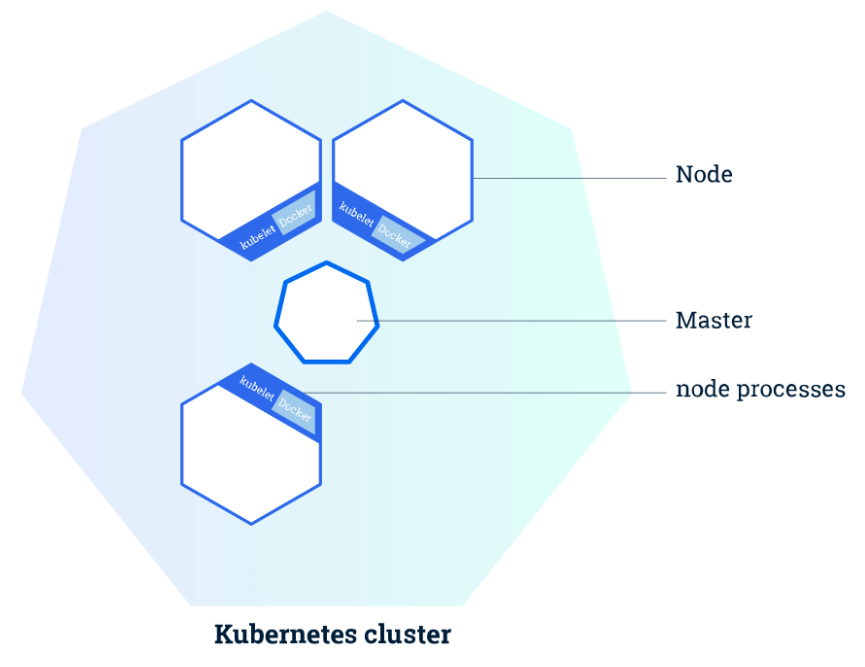
D’un point de vue infrastructure, un Cluster Kubernetes est constitué de 2 parties :
- Master : le serveur qui contrôle le cluster, c’est lui qui donne les instructions aux Worker Nodes ;
- Worker Node : le serveur qui héberge les applications.
Quand nous pilotons Kubernetes et ses objets en lignes de commandes, c’est au travers du Master que les instructions sont lancées.
Toutes les commandes envoyées et reçues (cli > master, master > worker) se font au travers des API fournies par Kubernetes. Les APIs se situent aussi bien sur le Master que sur les Slaves, mais nous ne pouvons accéder qu’aux API du Master, bien entendu !
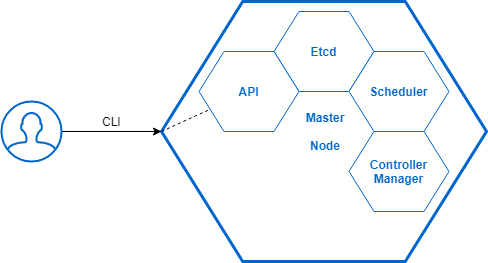
J’introduis rapidement les briques techniques du fonctionnement du Master Kubernetes :
- API : le endpoint commandé par le CLI
kubectlpour contrôler les objets Kubernetes ; - Etcd : l’espace de stockage où sont stockés les données persistantes nécessaires au fonctionnement de Kubernetes (les objets et leur état, la configuration en place, etc.) ;
- Scheduler : permet, entre autre, de répartir les conteneurs sur les Worker Nodes en prenant compte des performances des Worker et des exigences des conteneurs ;
- Controller Manager : zone d’identification et d’authentification des utilisateurs du Cluster Kubernetes.
Les objets basiques Kubernetes
Quand on commence avec Kubernetes, il faut connaitre 4 objets :
- Pod ;
- Deployment ;
- Service ;
- Ingress.
Ces 4 objets vous permettent de monter un simple site web sur n’importe quelle plateforme K8s (EKS, GKE, AKS, Rancher…).
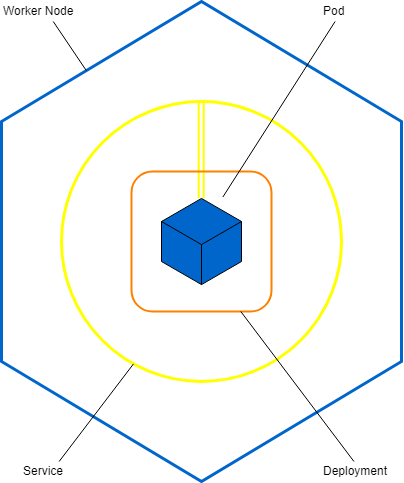
L’objet Pod
Description
Le Pod est le plus petit objet de Kubernetes. Un Pod contient un (ou plusieurs) conteneurs Docker. Gardez à l’esprit que la pluralité de conteneurs dans un Pod n’est pas forcément courante.
Conclusion basique : Un Pod = Un Conteneur
Avec ce postulat simple, on associe beaucoup mieux la notion de Pod dans Kubernetes.
Documentation officielle sur le Pod
Exemple
Voici un exemple de configuration pour le Pod d’un “Hello World!”, je le commente par la suite pour expliquer chacune des parties.
apiVersion: v1
kind: Pod
metadata:
name: hello-world
spec:
containers:
- name: hello-world
image: tutum/hello-world
imagePullPolicy: Always
ports:
- containerPort: 80
stdin: true
tty: true
livenessProbe:
httpGet:
path: /
port: 80
initialDelaySeconds: 10
periodSeconds: 10
Description des attributs :
apiVersion: Kubernetes fournit une API, les manifests créés sont envoyés à cette API, d’où l’importance de la versio (la version de l’API vient avec la version du Master) ;kind: le type de l’objet décrit dans les lignes qui suivent ;metadata: les données complémentaires à passer à notre objet, le seul champs nécessaire estnamepour décrire le nom de notre objet ;spec: la description complète de notre objet Kubernetes.
Les premiers attributs sont faciles à appréhender, la suite peut laisser pantois… Dans la section spec, voici quelques explications :
containers: décrit les conteneurs qui composent notre Pod, c’est une liste Yaml (il peut y avoir plusieurs conteneurs) ;container.name: le nom du conteneur, qui peut être (ou pas) le nom du Pod induit ;conainer.image: l’image Docker appelée pour générer le conteneur (puis Pod) ;container.ports: les ports d’écoute du conteneurs ;container.imagePullPolicy: la politique de récupération des images Docker, “Always” pour récupérer la toute dernière version du tag, même s’il change, et “Never” pour forcer la modification du tag pour récupérer l’image ;container.stdinetcontainer.tty: la faculté d’invoquer un TTY/Stdin pour pouvoir exécuter des commandes et entrer dans le conteneurs avec un shell ;container.livenessProbe: la sonde qui assure le bon fonctionnement du conteneur, et plus précisément du service embarqué par le conteneur.
L’objet Deployment
Description
L’objet Deployment est une surcouche au Pod qui permet d’ajouter des fonctionnalités comme le nombre de Pods régis par le Deployment.
Le Deployment intègre les fonctionnalités suivantes :
- Nombre de réplicas ;
- Nom de l’image Docker ;
- Ports d’écoute ;
- Healthcheck du conteneur ;
- Points de montage et volumes.
Les fonctionnalités du Deployment font penser à la notion de Service dans Docker Compose.
L’avantage du Deployment est de conserver la configuration des Pods intacte peu importe le nombre de réplicas déployés.
Documentation officielle sur le Deployment
Exemple
Voici un exemple de configuration pour le Deployment d’un “Hello World!”, je le commente par la suite pour expliquer chacune des parties.
apiVersion: apps/v1
kind: Deployment
metadata:
name: hello-world
labels:
app: hello-world
spec:
replicas: 1
selector:
matchLabels:
app: hello-world
template:
metadata:
labels:
app: hello-world
spec:
containers:
- name: hello-world
image: tutum/hello-world
imagePullPolicy: Always
ports:
- containerPort: 80
stdin: true
tty: true
livenessProbe:
httpGet:
path: /
port: 80
initialDelaySeconds: 10
periodSeconds: 10
On retrouve toute la partie spec.template.specdécrivant notre Pod.
Les attributs modifiés sont les suivants :
replicas: le nombre de pods à déployer (sous l’effigie de ce deployment) ;selector: les pods que ce deployment va contrôler ;selector.matchLabels: opérateur “match” sur les labels des Pods.
La notion de selector permet au Deployment de cibler les Pods qu’il va régir, ce qui permet à un deployment de contrôler des pods qu’il n’a pas généré (utilisation possible mais déconseillée).
Il existe plusieurs opérateurs dont “matchLabels” qui est le plus facile à utiliser.
Dans notre cas, les Labels servent à affilier des Pods à des Deployments. Leur utilisation va bien au delà, il servent également à répartir les objets sur des Worker Nodes (noeuds de travail de Kubernetes).
L’objet Service
Description
L’objet Service est une couche logique qui permet d’identifier le Pod ou Deployment associé et d’y apposer un port d’exposition.
Pour faire le rapprochement avec Docker, le paramètre -p (--port) dans docker run -p 80:8080 permet d’exposer le port 8080 du conteneur sur le port 80 du serveur. Dans Kubernetes, c’est le Service qui se charge d’exposer le port sur le serveur.
En réalité, le Service rend le port éligible à être exposé. Le Service expose le conteneur sur le Worker Node où il se trouve (type NodePort), et le rend accessible sur un port généré aléatoirement entre 30000 et 32767.
Conclusion intermédiaire : Un Service = Exposition du port sur le Worker Node.
Le type NodePort caractérise la façon dont le service va être exposé, il existe d’autres types mais celui-ci suffit à sa peine pour commencer. C’est le type NodePort qui rend le conteneur accessible sur le range de ports entre 30000 et 32767. Pour plus d’explications, la documentation officielle est disponible : Documentation complète sur l’exposition du service.
Documentation officielle sur le Service
Exemple
Voici un exemple de configuration pour le Service d’un “Hello World!”, je le commente par la suite pour expliquer chacune des parties.
apiVersion: v1
kind: Service
metadata:
name: hello-world
spec:
selector:
app: hello-world
type: NodePort
ports:
- port: 80
targetPort: 80
Les premières lignes n’ont plus de secrets pour vous. Pour ce qui est des attributs spécifiques aux services :
selector: le Pod ou Deployment visé à être interconnecté avec le service ;type: le mode d’exposition du service, qu’il soit public ou privé,ports: la liste des ports des Pods ou Deployments ;ports[0].port: le port de l’objet à exposer sur le serveur ;ports[0].targetPort: le port à atteindre dans le conteneur.
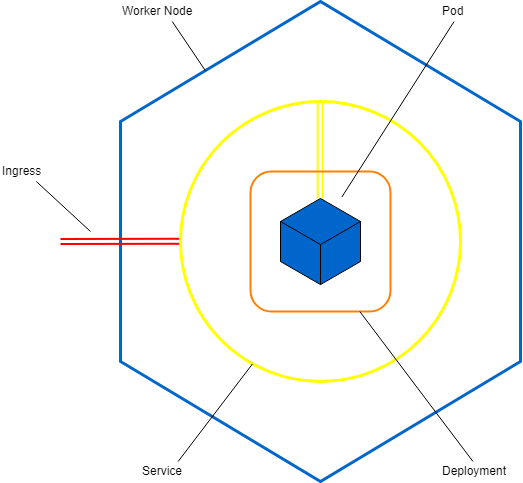
L’objet Ingress
Description
L’objet Ingress est l’objet Kubernetes qui autorise l’exposition du Service sur le port souhaité.
On parle de règles Ingress qui permettent l’exposition “réelle” des applications sur le Worker au travers de ports définis par l’utilisateur (pas de ports aléatoires) et bien souvent le port 80.
Une Ingress s’interconnecte naïvement sur un Service, ce qui rend son utilisation très simple.
Grâce à cet objet, l’application peut être pleinement exposée au grand public. Sans elle l’application est disponible (dans notre cas) uniquement sur le Worker Node.
Documentation officielle sur l’Ingress
Exemple
Voici un exemple de configuration pour l’Ingress d’un “Hello World!”, je le commente par la suite pour expliquer chacune des parties.
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: hello-world
spec:
backend:
serviceName: hello-world
servicePort: 80
Dans les options propres à l’Ingress :
backend: le backend représente la partie exposée de notre application et non visible des utilisateurs, dans la plupart des cas il s’agit du Service de l’application souhaitée ;backend.serviceName: le nom du service ciblé ;backend.servicePort: le port du service ciblé.
Mise en pratique
Création des objets
Maintenant que les présentations sont faites, nous allons pouvoir appliquer les exemples vus précédemment.
Connectez-vous au Cluster Kubernetes.
Créez un répertoire hello-world/ et collez-y les exemples précédents dans les fichiers respectifs :
hello-world/deployment.yamlhello-world/service.yamlhello-world/ingress.yaml
Le Pod de l’exemple ne nous sert pas étant donné qu’il est déjà décrit dans le Deployment.
Il ne reste plus qu’à appliquer les modifications :
kubectl apply -f hello-world/
…ce qui retournera :
deployment.apps/hello-world created ingress.extensions/hello-world created service/hello-world created
Bon… et comment on sait si tout se déroule bien ?
Visualisation des objets
Kubernetes fournit des commandes pour visualiser les objets à plusieurs niveaux, prenons l’exemple de l’objet Deployment :
kubectl get deployments: permet de visualiser tous les objets deployment du cluster ;kubectl logs deployment/hello-world: permet de visualiser les logs du conteneur géré par le deployment ;kubectl describe deployment/hello-world: permet de visualiser l’état de l’objet deployment depuis l’hyperviseur Kubernetes.

Les commandes getet describe sont opérables sur tous les objets : Pods, Deployment, Service, Ingress, …
La commande logs est disponible uniquement pour les objets : Pods, Deployment et dérivés de ces objets.
On obtient les résultats suivants :
kubectl get deployments
La sortie nous donne :
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE hello-world 1 1 1 1 50m
kubectl describe deployment/hello-world
Ce qui nous donne :
Name: hello-world
Namespace: default
CreationTimestamp: Mon, 15 Jul 2019 09:57:24 +0200
Labels: app=hello-world
Annotations: deployment.kubernetes.io/revision: 1
kubectl.kubernetes.io/last-applied-configuration:
{"apiVersion":"apps/v1","kind":"Deployment","metadata":{"annotations":{},"labels":{"app":"hello-world"},"name":"hello-world","namespace":"...
Selector: app=hello-world
Replicas: 1 desired | 1 updated | 1 total | 1 available | 0 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 0
RollingUpdateStrategy: 25% max unavailable, 25% max surge
Pod Template:
Labels: app=hello-world
Containers:
hello-world:
Image: tutum/hello-world
Port: 80/TCP
Host Port: 0/TCP
Liveness: http-get http://:80/ delay=10s timeout=1s period=10s #success=1 #failure=3
Environment: <none>
Mounts: <none>
Volumes: <none>
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing True NewReplicaSetAvailable
OldReplicaSets: <none>
NewReplicaSet: hello-world-6dbf7f75cf (1/1 replicas created)
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ScalingReplicaSet 51m deployment-controller Scaled up replica set hello-world-6dbf7f75cf to 1
Maintenant vous savez aborder les prémices de Kubernetes par un exemple, vous avez “presque” toutes les armes pour déployer vos applications sur les cluster Kubernetes.
Il vous manquera certainement une chose : où je déploie mes applications ? Cloud ou on-premise ?
C’est ce dont parlera le prochain article sur Kubernetes !
Liens utiles
Documentation Kubernetes :

