Serverless, Microservices, Conteneurs, Kubernetes, FaaS… Pour tirer parti au maximum de ces tendances, nos applications doivent être petites, rapides, tout en supportant l’outillage indispensable à l’heure actuelle : sécurité, observabilité, communication par messages, etc…
Dans ce contexte, l’écosystème Java peut-il alors encore être pertinent ?
Sorti il y a quelques mois, Quarkus est un nouveau framework Java développé par Redhat, dont le but est justement de réduire l’empreinte mémoire et le temps de démarrage des applications, tout en s’inspirant des meilleurs standards actuels pour proposer la meilleure expérience de développement possible.
Plus qu’un simple tour d’horizon de cette technologie, nous vous proposons dans cette série d’articles de découvrir l’étendue des fonctionnalités de ce nouveau venu dans le monde du développement Java, en créant une plateforme de collecte et d’agrégation de données issues d’un réseau de capteurs.
De quoi parle-t-on ?
Pour faire simple, nous parlons tout simplement d’un framework simplifiant le développement d’applications Cloud Native. En effet, le déploiement de microservices en environnement Cloud, de même que leur scalabilité nécessitent que ces applications aient une faible empreinte mémoire et démarrent rapidement. Ce prédicat rendait le développement de telles applications difficilement envisageable en Java, surtout face à des langages comme Golang ou Javascript qui semblent davantage s’épanouir dans un environnement conteneurisé, du fait de leur faible embonpoint.
Mais Quarkus change la donne, en apportant une stack Java taillée pour le développement de microservices, et permettant de générer des images HotSpot ou natives via GraalVM.
Supersonic Subatomic Java
Devise du framework, site officiel de Quarkus.
A Kubernetes Native Java stack tailored for GraalVM & OpenJDK HotSpot, crafted from the best of breed Java libraries and standards.
Le slogan de Quarkus est donc tout à fait approprié ! Une application construite avec Quarkus, et ayant en ligne de mire une exécution sous GraalVM, démarre en quelques millisecondes et ne pèsera qu’une dizaine de Mo.

Mais en dehors de ces optimisations intéressantes, notons également que Quarkus repose sur des technologies existantes et généralement maîtrisées par les développeurs : Hibernates, RestEasy ou encore Vertx (pour les fonctionnalités réactives et asynchrones). La courbe d’apprentissage est donc relativement faible.
De plus le passage d’un mode mode à un autre (ex : synchrone à asynchrone) se fait de façon transparente (ou presque). Les fonctions retourneront :
- la réponse telle quelle lors des appels synchrones
- un CompletionStage lors des appels asynchrones
- un Publisher pour le streaming de données ou appels réactifs
Il y a donc très peu de changements sur le code, et nous bénéficions d’une implémentation unique quelque soit le paradigme.
Pour en revenir aux technologies servant de socle à Quarkus, celles ci sont accessibles sous la formes d’extensions. Ainsi l’utilisation d’un client MongoDB ou des fonctionnalités réactives de Vertx nécessiteront l’ajout de dépendances à vos projets. Bien que le framework soit très jeune, le nombre d’extensions est déjà impressionnant !
Et ceci est loin d’être figé : dans le cas où nous souhaiterions ajouter le support de nouvelles briques à Quarkus, le développement de nos propres extensions est également possible… bien que la tâche ne soit pas complètement triviale, nous allons voir pourquoi.
La magie noire : comment ça marche ?
Le problème principal de Java dans notre contexte, est qu’il y a un overhead significatif au niveau du démarrage et de l’occupation mémoire, qui devient vite problématique lorsque le programme est petit comme dans le cas d’un microservice.
En effet, en plus du heap qui contient les données de notre programme, un morceau conséquent de mémoire est occupé par le metaspace, qui contient des informations sur la hiérarchie des classes, l’état de la compilation, le linkage dynamique, des statistiques sur les appels inter-classes… etc. Pour un microservice, il n’est pas rare de voir 80% de la mémoire occupée par le metaspace !
On a donc un fort pourcentage de la mémoire occupée par des données liées à la stack Java. Heureusement, il y a une solution : GraalVM ! Ce nouveau venu dans le monde des JVM, introduit une fonctionnalité particulièrement intéressante dans le monde Java : la compilation ahead-of-time. Il va nous permettre de faire un maximum de choses au moment de la compilation, réduisant ainsi le nombre d’opérations nécessaires au runtime et donc la quantité d’informations stockées dans le metaspace. On réduit par la même occasion le temps de démarrage, puisqu’un certain nombre des traitements effectués au démarrages seront eux aussi fait au moment de la compilation.
Malheureusement, l’utilisation du compilateur natif de GraalVM implique quelques restrictions : pas de reflection, pas de chargement dynamique de classes au runtime, etc. Comme la plupart des frameworks actuels utilisent copieusement ces fonctionnalités, pour tirer parti de la compilation ahead-of-time, il faut que le framework soit développé spécifiquement en prenant compte de ces limitations. Contrairement à son principal concurrent Micronaut (qui a été conçu en partant de 0), Quarkus se base sur des librairies établies et populaires auprès des développeurs (Microprofile, Hibernate, VertX) qui ont été adaptées pour fonctionner avec GraalVM.

Grâce à ce choix, et malgré ces quelques mois d’existence, Quarkus propose déjà un panel très large d’extensions !
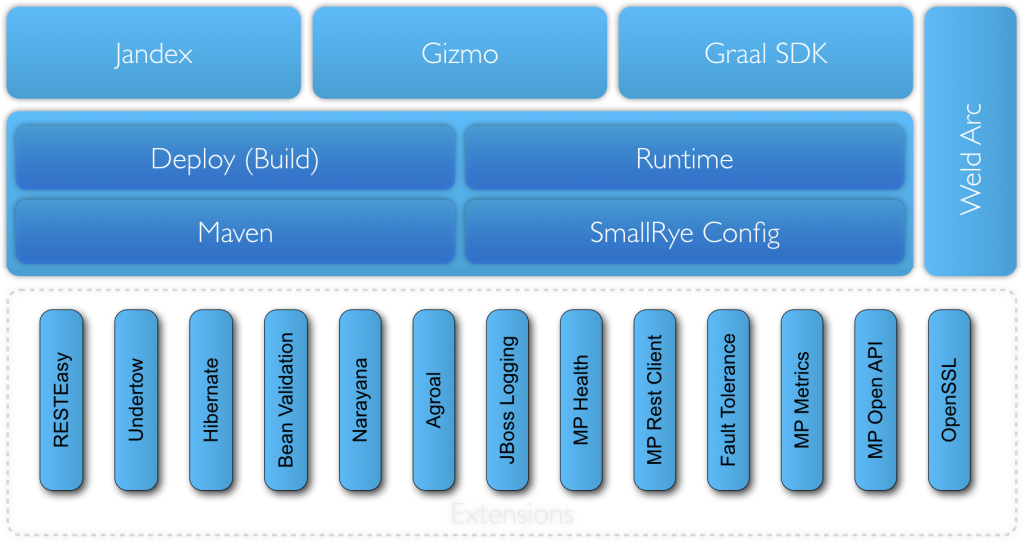
Pour mieux comprendre ce qu’implique le développement GraalVM natif, et les solutions apportées par Quarkus nous vous invitons à lire l’excellent article Write Your Own Extension de la documentation officielle.
Un cas concret : Quarkus au service de l’IOT.
Vous l’aurez compris, Quarkus permet de développer des applications démarrant rapidement tout en utilisant très peu la mémoire du système. Et la vrai force du framework c’est qu’il permet de réaliser cela très facilement, en s’appuyant sur des briques existantes et en uniformisant les différents paradigmes.
Et pour nous en rendre compte, passons à la pratique.
Quel sujet choisir pour notre projet fil rouge ? Nous parlions tout à l’heure de récupérer des données issues d’un réseau de capteurs, mais des capteurs qui mesurent quoi ?
Depuis quelques années, on observe une prise de conscience de la population au sujet de la qualité de l’air, notamment des effets négatifs sur la santé de la pollutions aux particules fines (allergies, maladie pulmonaires, etc…). Et si quelques initiatives existent — comme par exemple le projet Ambassad’Air à Rennes — on remarque un manque d’information locale et précise à ce sujet.
Bingo ! Nous avons notre cas d’usage 🙂 Nos capteurs relèveront la température et les particules fines présentes à l’intérieur et à l’extérieur de l’agence Ineat, l’idée étant de calculer des tendances et orienter notre mode de vie en fonction des données mesurées. Par exemple, si la température est élevée sur tel ou tel plateau, vaut-il mieux ouvrir les fenêtres ou faire fonctionner les ventilateurs ?
Architecture
Comme stipulé un peu plus haut, le projet consistera a développer une plateforme collectant des données issues d’un réseau de capteurs afin d’un tirer des statistiques et calculer des tendances. Nous pouvons donc imaginer deux briques Quarkus :
- l’une utilisée pour la collecte, le streaming et la sauvegarde des données brutes
- l’autre pour l’agrégation des données stockées en base, le calcul de tendances et la récupération des capteurs référencés, le tout restitué sous la forme d’une série d’APIs REST.
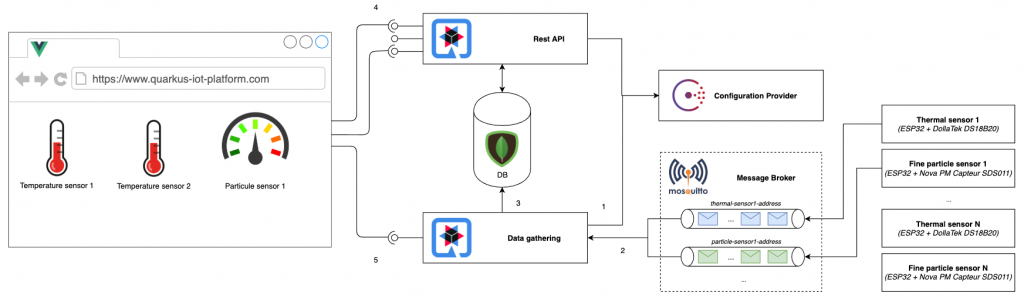
- Au démarrage, les deux briques récupèrent la configuration stockée dans Consul. Celle ci contient la liste des capteurs répartie par zone et type.
- Le module “Data gathering” écoutent les messages émis par les capteurs sur chaque topic. Chaque capteur aura son propre topic, qui sera de la forme {ZONE}/{TYPE}/{CAPTEUR} avec
{ZONE} = la zone où se trouve le capteur (par exemple “Accueil” ou “CDS”)
{TYPE} = le type de donnée relevé (Thermique ou Particule)
{CAPTEUR} = le nom du capteur - Les données mesurées sont périodiquement stockées en base de données MongoDB (plus tard nous migrerons sur une base orientée time series, mais pour le moment MongoDB est au catalogue Quarkus).
- Au lancement du Front, celui ci appelle une Api du module “Rest API” pour récupérer la liste des capteurs à afficher. En fonction du type de chaque capteur, tel ou tel widget sera initialisé.
- Dans un second temps, le Front se connecte au flux de données émis par “Data gathering” (en mode Server Sent Event) afin d’afficher en temps réel les données mesurées par les capteurs.
Initialiser un projet
Démarrer un nouveau projet Quarkus est relativement simple avec Maven. Ainsi pour créer notre application il suffirait de lancer :
mvn io.quarkus:quarkus-maven-plugin:0.20.0:create \
-DprojectGroupId=com.ineat \
-DprojectArtifactId=sensors-manager \
-DclassName="com.ineat.sensors.manager.DefaultResource" \
-Dpath="/sensors"
Un répertoire sera généré, contenant entre autres une ressource REST « DefaultResource » exposant un endpoint « /sensors », le fichier de configuration de l’application, ainsi que des squelettes de Dockerfiles permettant de packager notre projet en mode natif ou jvm.
On lancera l’application avec :
mvn compile quarkus:dev
Un simple appel à http://localhost:8080/sensors vous permettra de vérifier que tout fonctionne.
Profitez en pour tester le hot reload ! Faites une modification dans le code (modifier le message renvoyé par /sensors par exemple), enregistrez et appelez de nouveau http://localhost:8080/sensors : vous constaterez que les modifications sont prises à chaud, sans nécessiter une quelconque recompilation de votre part 😉
Quarkus propose déjà un panel très fournis d’extensions, dont certaines seront abordées au fil des articles. Nous ajouterons alors telle ou telle extension comme suit :
mvn quarkus:add-extension -Dextensions="groupId:artifactId"
Sachez enfin que le listing des extensions est accessible avec :
mvn quarkus:list-extensions
En attendant la suite …
Vous avez pu, au travers de cet article, avoir un bref aperçu du fonctionnement interne de Quarkus et des besoins qu’il adresse. Cependant nous n’avons fait que voir la partie émergée de l’iceberg, et sans mise en pratique difficile de prendre conscience de la puissance offerte par ce framework. Et c’est justement ce que nous aborderons durant le second article : après une première partie dédiée à la création des capteurs publiant température et taux de particules fines nous verrons comment collecter ces données depuis un bus MQTT, un bon exercice illustrant avec quelle facilité nous pouvons mettre en place les reactive streams avec Quarkus 🙂
- Site officiel de Quarkus – https://quarkus.io/
- Repository GitHub – https://github.com/quarkusio/quarkus
- Documentation officielle de GraalVM – https://www.graalvm.org/docs/
- Présentation de Quarkus au Devoxx 2019 – https://www.youtube.com/watch?v=JhAYfP99agc
- Listing des extensions Quarkus – https://quarkus.io/extensions/
- La création d’extensions Quarkus – https://quarkus.io/guides/extension-authors-guide

