
Ineat était une nouvelle fois présent au Devfest Lille pour la troisième édition, mais petite nouveauté cette année : nous sponsorisions l’évènement !
Quels changements depuis l’édition précédente ?
Bien des changements ont eu lieu cette année, et pour vous qui n’avez peut être pas pu venir à Devfest le 14 Juin dernier nous vous proposons un petit topo des principales transformations opérées cette année.
Un thème et un lieu atypiques
Cette année, le thème retenu par les organisateurs était les séries TV. Chaque sponsor pouvait donc choisir une série dont l’univers servait d’habillage à leur stand. Et quoi de mieux que le Kinépolis de Lomme pour accueillir cette édition ! Outre le lien avec le thème, le cinéma offre un grand espace permettant de circuler assez facilement et d’avoir une certaine zone de confort autour des stands. Les salles de conférences sont ici des salles de diffusions dotées de fauteuils…très confortables !
La logistique
Rien à dire concernant la distribution des sacs de conférenciers remplis de goodies et correctement distribués. Côté déjeuner on notera une vraie amélioration : le sachet repas. Un repas froid était organisé lors de l’édition 2018 pour que les participants puissent se restaurer. Le self service offrait certes un moment très convivial mais parfois assez anarchique : beaucoup de personnes souhaitaient se servir en même temps, pas très pratique. L’arrivée des sachets repas est donc une bénédiction. Ceux-ci étant répartis en fonction des goûts de chacun (végétarien, poulet, …), la récupération de notre entrée/plat/désert n’en est que plus rapide. Moins d’attente avant de pouvoir se servir, donc plus de temps à passer sur les stands, CQFD 😉
Des formats de conférences différents
Contrairement à l’année dernière, aucun codelab n’a eu lieu. Cependant l’édition 2019 s’est rattrapée sur le nombre de conférences et la diversité des sujets. Le format quickies a par ailleurs été expérimenté. Ces conférences de 20-30 minutes sont plutôt efficaces puisqu’elles permettent de découvrir une technologie rapidement, et de se concentrer sur l’essentiel.
Et Ineat ?
Nous étions présents en force cette année, beaucoup plus de participants Ineatiens par rapport à l’année dernière. Et pour la première fois nous sponsorisions Devfest ! Nous avions donc notre propre stand (aux couleurs de Game of Thrones) où vous pouviez nous rencontrer et déguster quelques glaces 🙂 .

Les conférences
Web Components can do that ?
CR : Nicolas Fourré
Cette présentation de Philippe Charrière (alias @k33g_org) nous présente la librairie LitElement. LitElement est une librairie développée par l’équipe de Polymer, elle permet de créer des WebComponents basés sur le standard HTML et donc utilisables dans différentes applications / différents framework Front-End. Cette librairie est basée sur l’utilisation de sa grande soeur LitHTML qui est une librairie de templating HTML dans des fichier JavaScript, une sorte de JSX pour les amoureux de ReactJS.
Une fois les présentations faites avec la librairie, il nous explique comment il a utilisé cette dernière pour faire un petit projet qui liste toutes les fonctions AWS Lambda temps réel sur son compte. Il présente comment créer un WebComponent avec LitElement… Voilà à quoi ça ressemble:
import { LitElement, html } from "lit-element";
export class MainApplication extends LitElement {
render() {
return html`
<section class="container">
<div>
<h1 class="title>Hello World</h1>
</div>
</section>
`;
}
}
customElements.define("main-application", MainApplication);
Styliser les composants
Là c’est le drame car il y a plusieurs procédures pour appliquer le style CSS à un WebComponent créé via LitElement, la première est l’utilisation de la méthode css de LitElement, on va alors intégrer le style CSS directement sous forme de “string” dans notre fichier JS (qu’on pourra malgré tout externaliser, puis importer dans notre composant). Ça ressemblera à :
import { css } from 'lit-element';
export const style = css`
.container {
min-height: 100vh;
display: flex;
justify-content: center;
align-items: center;
text-align: center
}
.title {
font-family: "Source Sans Pro";
display: block;
font-weight: 300;
font-size: 100px;
color: #35495e;
letter-spacing: 1px;
}
`
On peut également utiliser des feuilles de style CSS externes qu’on viendra linker dans notre composant mais attention, si on a X WebComponent, la feuille de style sera chargée X fois, ce qui est très mauvais pour les performances de votre site.
Faire communiquer vos composants
Pour faire passer des informations au WebComponent, on utilise les attributs HTML qu’il faudra déclarer dans notre composant via un getter sur les “properties”.
export class MainApplication extends LitElement {
static get properties() {
return {
myTitle: { attribute: 'my-title' }
}
}
render() {
return html`
<section class="container">
<div>
<h1 class="title>${this.myTitle}</h1>
</div>
</section>
`;
}
}
customElements.define("main-application", MainApplication);
En revanche, pour faire remonter les informations d’un composant vers son parent, on utilise les évènements JavaScript avec un écouteur sur le parent via la méthode addEventListener et dans le composant une méthode dispatchEvent pour envoyé un évènement qui sera alors intercepté par l’écouteur. Ce qui est assez simple et efficace tout en étant du pur JavaScript.
Passer en production
Et la c’est pas si simple que ça, il faut utiliser le CLI de Polymer (l’équipe est la même) pour pouvoir builder notre WebComponent. Mais une fois cette étape passée et le fichier polymer.json bien configuré tout fonctionne.
En conclusion, cette librairie à l’air assez facile d’utilisation et permet de créer des WebComponents en utilisant les standards du web. Reste à tester cette librairie sur vos projets.
Pour en savoir plus n’hésitez pas à consulter le repo démo de Philippe Charrière sur LitElement : https://gitlab.com/bots-garden/presentations/breizhcamp-2019/lit-element-bz-2019.
Auto ML Vision : Le PAAS du machine Learning
CR : Mehdi Slimani
Au fil des années Google a développé de nombreux outils autour du machine learning. Si vous n’avez aucune connaissance sur les perceptrons, la descente de gradient, les réseaux de neurones, les modèles à convolution alors Auto ML Vision est fait pour vous !
Cette solution permet de créer un algorithme de classification d’images sans aucun code. Pour un algorithme plus précis il faudra alors développer votre propre modèle sur Tensorflow.
Après une introduction des différentes spécificités du machine learning, Patrice De Saint Steban ( @patoudss – Zenika ) nous a présenté comment développer une application type “Shazam séries”.
Première étape : développer le modèle sur Cloud AutoML
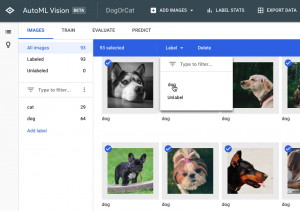
L’interface permet d’entraîner un algorithme automatiquement avec un dataset créé par vos soins. C’est l’étape la plus importante car plus votre dataset sera de qualité, plus il sera facile de classifier vos images. Lors de cette présentation Patrice a classifié plusieurs images de différentes séries TV : Game of Thrones, Friends etc…
Deuxième étape : intégrer le modèle dans son application Web, Mobile etc…
L’interface Auto ML Vision permet d’exporter un modèle avec différentes valeurs de compression. Le type de compression influence la pertinence des résultats. En effet plus un modèle sera compressé moins il sera pertinent. À vous de faire le choix selon votre besoin.
Pour cette présentation une interface web avait été développée et déployée avec Cloud Run. L’utilisateur pouvait uploader une image qui était exécutée dans Tensorflow JS. Le résultat affichait le nom de la série liée à l’image.
Pour conclure, Auto ML permet de faciliter l’intégration du machine learning dans vos applications. Celui-ci se découpe en 3 partie mais ici seul la solution AutoML Vision a été présentée. C’est pour cela nous reviendrons très prochainement avec un article traitant des parties suivantes : AutoML Natural Language, AutoML Translation.
Tests de propriétés : Écrivez moins de tests, trouvez plus de bugs
Speaker : Julien Debon
CR : Rémi Duriez
Suivant la keynote d’ouverture, l’une des premières sessions – présentée par Julien Debon (@Sir4ur0n) – est consacrée aux tests de propriétés.
Sont appelées propriétés des comportements constants que doit avoir notre programme en lui fournissant une grande variété de données. Là où un test unitaire nécessite une donnée fixe en entrée et est exécuté une seule fois, un test de propriété sera donc joué à de multiples reprises avec des données aléatoires.
Quickcheck est la bibliothèque utilisée pour programmer ces cas de tests. Originellement en Haskell, elle est déclinée pour beaucoup d’autres langages, et c’est en Java avec JUnit-QuickCheck que la démonstration de code nous est faite.
Quatre propriétés nous sont présentées en live coding et permettent de se familiariser avec les nouvelles méthodes de test.
La propriété d’idempotence, qui assure qu’une méthode appliquée plusieurs fois aura toujours le même résultat.
@Property
public void idempotence(List<String> anyStrings) {
List<String> result1 = cut.removeSmallWords(anyStrings);
List<String> result2 = cut.removeSmallWords(result1);
assertThat(result1).isEqualTo(result2);
}
La propriété d’invariance, qui assure un résultat identique quelques soient les entrées.
@Property
public void invariant_31_12(short anyYear) {
assertThat(cut.isNewYearEve(LocalDate.of(anyYear, 12, 31))).isTrue();
}
@Property(trials = 1000)
public void invariant_not_31_12(LocalDate anyDate) {
assumeThat(anyDate.getMonthValue() != 12 || anyDate.getDayOfMonth() != 31).isTrue();
assertThat(cut.isNewYearEve(anyDate)).isFalse();
}
La propriété d’analogie, qui assure un même résultat pour deux fonctions différentes, ce qui est particulièrement intéressant dans une logique de refactorisation de code.
@Property
public void analogous_legacy_vavr(Option<User> anyMaybeUser) {
List<Sport> legacy = cut.friendsSportsOrderByName_legacy(anyMaybeUser.getOrNull());
List<Sport> vavr = cut.friendsSportsOrderByName_vavr(anyMaybeUser);
assertThat(vavr).isEqualTo(legacy);
}
La propriété d’inverse, qui assure que l’état d’origine peut être rétabli par une fonction, applicable aux convertisseurs de devises par exemple.
@Property
public void inverse_add_remove(Price anyPrice) {
Price priceWithTaxes = cut.addTaxes(anyPrice);
Price priceWithoutTaxes = cut.removeTaxes(priceWithTaxes);
assertThat(priceWithoutTaxes).isEqualTo(anyPrice);
}
Les objets passés en paramètres de ces méthodes sont générés avec des valeurs aléatoires lors de l’exécution des tests. Il est néanmoins possible d’écrire ses propres classes de génération d’objets, en étendant le Generator de QuickCheck. On voudra par exemple surcharger la génération de notre objet Price pour que son élément value soit un nombre aléatoire mais positif. Ou surcharger la méthode de réduction (shrink), qui permet en cas d’échec du test sur une valeur de trouver une autre valeur en erreur plus simple et plus compréhensible pour le développeur.
Parmi les gains rapportés par Julien, on peut voir en ce type de test une manière de tester une application avec un jeu de données bien plus large, en moins de lignes de code. En effet, passer par un générateur d’objet épargnerait d’utiliser des mocks individuels pour ses tests. Il est cependant conseillé d’y voir un complément aux tests unitaires traditionnels plutôt qu’un remplacement.
Vous pouvez retrouver l’ensemble du code présenté ici.
Il faut sauver le soldat Jenkins !
Speaker : Nicolas de Loof
CR : Mathias Deremer-Accettone

Aujourd’hui encore Jenkins est reconnu comme une solution fiable de CI / CD, et ce malgré son architecture interne datant de plus de 10 ans.
Néanmoins Jenkins ne semble pas être la solution optimale pour la production d’applications Cloud Ready. En effet construire et déployer ce type de projet implique généralement d’ajouter du code spécifique aux Jenkinsfiles, d’installer les bons plugins…bref des tâches chronophages pouvant complexifier le travail des équipes.
C’est en partant de ce constat que Jenkins X est apparu, et c’est dans ce contexte que Nicolas De Loof nous parlera des fonctionnalités apportées par cette version taillée pour le déploiement d’applications au sein de clusters Kubernetes. Avant de nous offrir un tour d’horizon des fonctionnalités offertes par le nouveau venu, notre speaker nous rappelle les limites de Jenkins et les contraintes imposées par le Cloud lors des phases de build et déploiement. Il redonnera également des définitions de concepts plus ou moins nouveaux comme “GitOps” : une approche qui consiste a appliquer les flux Git aux opérations de build, mais également un modèle d’exploitation pour Kubernetes et le Cloud Native.
Nicolas entre ensuite dans le vif du sujet. Nous apprendrons que Jenkins X repose sur des outils comme Helm, Docker ou encore Skaffold pour construire et déployer des applications sur Kubernetes.
Bon nombre de facilitants sont donc intégrés et la construction de la chaine de build s’en trouve allégée. Nous noterons cependant que tout n’est pas magique, et certains fichiers sont toujours nécessaires pour que cela fonctionne. Citons par exemple les jenkins-x.yaml, qui sont d’une certaine façon les remplaçants des Jenkinsfiles classiques privilégiant la description sous la forme de Yaml des étapes de construction du projet. Le talk est illustré avec une démo présentant avec quelle facilité il est possible d’intégrer un projet sur Jenkins X.
Partons du principe qu’il soit nécessaire de déployer le projet sur un cluster GKE, cluster qui devra être créé pour l’occasion. Nous débuterons par la création de ce cluster, opération qui est grandement facilité par la commande jx (CLI fournit par Jenkins X). Après avoir créé un nouveau projet sur la GCP, et lié un compte de facturation, nous lancerons la commande :
$ jx create cluster gke --skip-login --default-admin-password=my_password -n kubernetes_cluster_name
Ici on précise que le type de cluster à créer est gke, ainsi que le mot de passe admin et le nom à donner à notre cluster via l’option -n.
Nous pourrons ensuite importer notre application avec la commande :
$ jx import --url https://url/projet.git
Cette commande permet d’ajouter notre projet à l’usine de build directement en passant l’url du repository Git. Un build sera lancé automatiquement, impliquant la construction de l’application, la génération d’une image docker à partir du Dockerfile situé à la racine du projet, l’upload de cette image sur une registry Docker, le dépôt d’un tag sur le repository Git du projet… en somme toutes les étapes listées dans le jenkins-x.yml. Nul besoin de phases de développement complexes dans un Jenkinsfile écrit en Groovy : l’ajout de nouvelles steps se fait avec la commande jx, qui posera une série de questions à l’utilisateur afin de collecter les informations qui lui seront nécessaires et ajouter le YAML nécessaire dans le fichier jenkins-x.yml. L’intérêt ici est que le déploiement sur GKE est également automatique, et une fois le projet importé via jx, chaque push sur le repository Git provoquera le lancement du pipeline de Build (l’intégration des Webhooks est là aussi simplifiée). En d’autres termes, les développeurs n’ont plus vraiment besoins de comprendre l’ensemble des rouages internes de Kubernetes.
L’exemple ici est relativement simple, et jx propose bien d’autres fonctionnalités et supporte de multiples Cloud Providers. Jenkins X semble donc revenir dans la course en comblant ses manques sur les aspects Cloud, et est de nouveau concurrentiel face aux autres solutions comme CircleCI.
La programmation réactive avec Spring Webflux
Speakers : Jeoffrey Haeyaert et Julien de Sousa
CR : Cédric Freville
Cette conférence avait pour objectif de nous faire découvrir les concepts de la programmation réactive en alliant théorie et live démo. Il s’agit d’un paradigme commençant à faire beaucoup d’émules auprès des développeurs, et quoi de mieux qu’un talk sur le sujet pour découvrir les raisons de cet engouement ? Chaque précepte de la programmation réactive (streams, back pressure, non-blocking…) ont été abordés et illustrés avec des exemples concrets s’appuyant sur le framework Spring Webflux (et Reactor).

Mais avant de rentrer dans le vif du sujet et montrer du code source, les speakers ont redonné les bases de la programmation réactive et présenté Webflux, qui fut créé pour pouvoir gérer des appels HTTP non bloquants en se basant sur la bibliothèque Reactor.
Quelques rappels théoriques
Le projet Reactor fournit les classes Mono<T> et Flux<T> qui permettent de travailler avec des opérateurs de la bibliothèque ReactiveX. Ce qu’il faut surtout retenir de ce laïus, c’est que Reactor est une bibliothèque de flux réactive, et par conséquent tous les opérateurs proposés par ses classes sont non bloquants.
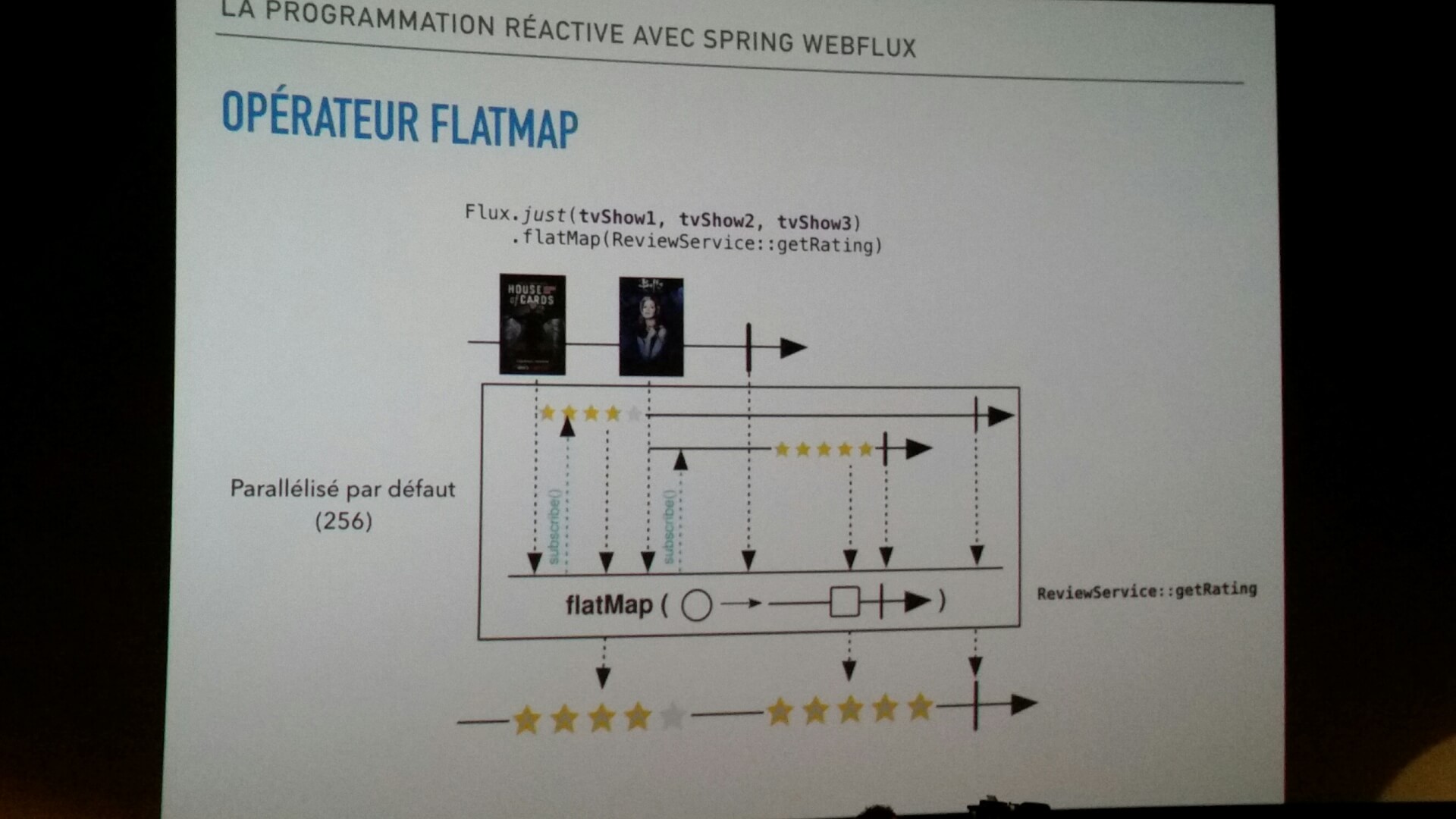
Jeoffrey et Julien ont poursuivi leur présentation avec une description des problématiques adressées par les flux réactifs. On apprend que ce projet vise à proposer un standard pour implémenter des flux asynchrones (“non blocking back pressure”). En effet, lorsqu’on manipule un flux, l’envoi de fortes volumétries de donnée a souvent tendance à être beaucoup plus rapide que la consommation. Par conséquent il faut impérativement veiller à ne pas envoyer trop de données afin d’éviter d’engorger et de bloquer le flux.
Avec l’arrivée de Java 9, Oracle a ajouté de nouvelles interfaces qui s’apparentent fortement à celles proposées par les flux réactifs. Attention cependant, l’API Flow de Java 9 n’émet pas de signal pour gérer les backpressures.
Mais qu’est-ce que le concept de Backpressure ?
On lit souvent ce terme sur des blogs ou dans la presse spécialisée mais concrètement qu’est ce que c’est ? Le talk nous aura apporté une réponse simple et claire à cette question.
Le phénomène de « backpressure » survient lorsque le flux est surchargé.
Comme le rappelle le Manifeste Réactif, un système ne doit pas échouer, bloquer ou perdre des données lorsqu’il est fortement sollicité. Il est donc nécessaire que le flux réactif signale au Publisher qu’il est soumis à certaines contraintes, et ainsi réduire la charge. Ainsi, le Publisher peut choisir parmi plusieurs stratégies pour réduire la pression et ne pas planter le système. L’une des solutions pour avoir des backpressures non bloquantes est de s’orienter vers un modèle orienté “pull”. De cette façon, le Subscriber demande au Publisher un certain nombre de messages, en attendant de nouvelles demandes avant d’en envoyer d’autres.
Un peu de pratique
Passée l’étape des rappels théoriques sur la programmation réactive, nos deux speakers énumèrent les composants constituant un flux réactif.
-
Publisher : l’entrée de notre flux qui va produire et émettre des signaux vers le(s) Subscriber(s).
-
Subscriber : le consommateur du flux.
-
Processor : permet de transformer l’objet publié dans le Publisher en objet consommé par le Subscriber.
-
Subscription : décrit l’action de souscrire à un Publisher avec un Subscriber (utilisé pour demander de la donnée mais également pour annuler une demande).
Et vient enfin la partie préférée de la plus part des conférenciers : la démo.
Les speakers ont illustré leurs propos avec beaucoup de code, et nous avons pu constater avec quelle simplicité il était possible d’écrire un controller Spring en réactif (surtout quand on est habitué à Spring Boot). À titre d’exemple voilà ce que cela pourrait donner :
@RestController
@RequestMapping("/products")
public class ProductReactiveController {
private final ProductRepository productRepository;
@GetMapping("/{id}")
private Mono<Product> getProductById(@PathVariableString id) {
return productRepository.findProductById(id);
}
@GetMapping
private Flux<Product> getAllProducts() {
return productRepository.findAllProducts();
}
}
On comprend rapidement ici que les Mono sont utilisés pour récupérer 0 ou 1 élément, là ou les Flux retournent 1 à n éléments.
Mono<String> mono = Mono.just("Alex");
Mono<String> mono = Mono.empty();
Flux<String> flux = Flux.just("A","B","C");
Flux<String> flux = Flux.fromArray(newString[]{"A","B","C"});
Flux<String> flux = Flux.fromIterable(Arrays.asList("A","B","C"));
La séance se terminera par un exemple de récupération de données depuis une base MongoDb, le tout en réactif. Petite précision apportée par Julien : il faut nécessairement utiliser un driver spécifique compatible reactive lors de la mise en oeuvre.
Côté entité cela donnera :
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.springframework.data.mongodb.core.mapping.Document;
@Document@Data
@AllArgsConstructor
@NoArgsConstructor
public class Product {
private String id;
private String name;
}
Et au niveau du repository :
import org.springframework.data.mongodb.repository.ReactiveMongoRepository;
public interface ProductRepository extends ReactiveMongoRepository<Product, Long> { }
Un talk très intéressant et très bien illustré !
Des microservices aux migroservices
Speaker : François Teychene
CR : Julien Lazewski
Pour sa conférence, François Teychené nous présente ce qu’il nomme les migroservices et nous explique en quoi ils peuvent constituer une étape intermédiaire nécessaire lors de la transformation d’un monolithe en microservices.
Quelques rappels
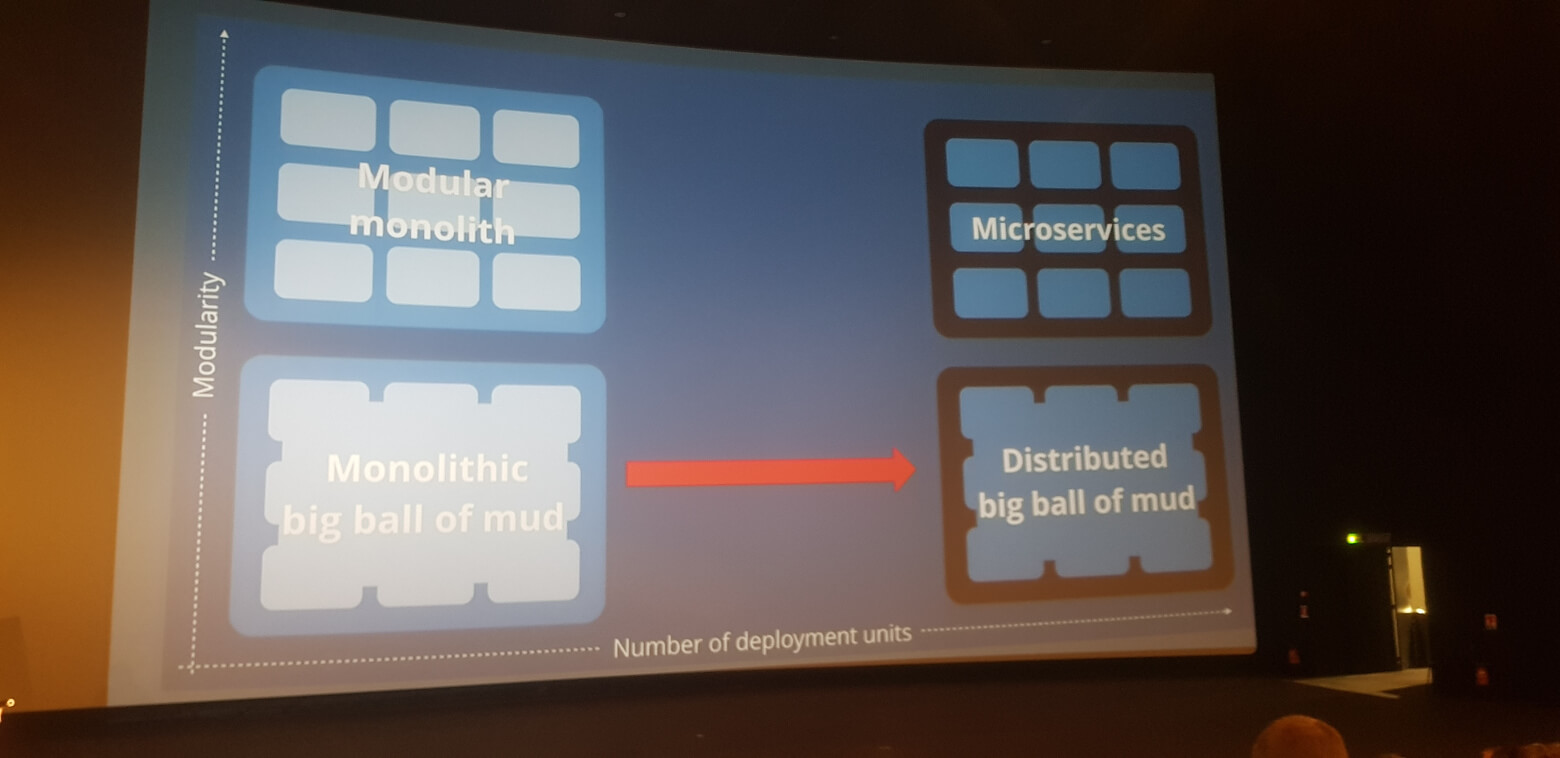
Un monolithe est une application qui, par définition, n’est pas scindée en plusieurs couches, modules ou services. Cela implique des difficultés pour maintenir et faire évoluer le produit. Ce type d’architecture applicative apparaît pendant les années 2000 ; on parle alors d’architecture en lasagnes (layered monolith) qui a émergé pour pallier aux nombreux inconvénients des architectures appelées spaghetti (copy & paste), très en vue durant les années 90. C’est dans le but de scinder les monolithes, et de diminuer leur complexité de maintenance et d’évolution que, pendant les années 2010, les architectures dites ravioli (microservices) ont vu le jour.
Objectifs des microservices
En théorie, les microservices apportent de la scalabilité et permettent des évolutions rapides en réduisant la complexité, qui se mesure via 3 aspects :
- la complexité fonctionnelle
- la complexité technique
- la dette technique
Toujours en théorie, la mise en place d’une architecture microservices, en remplacement d’un monolithe, permettrait de réduire la complexité fonctionnelle et la dette technique (car on isole l’application en raviolis, indépendants les uns des autres). Seule la complexité technique est censée augmenter “légèrement”. Par ailleurs, en bonus, cela permettrait des releases rapides et la mise en place facilitée d’une résilience.
L’architecture microservices semble parfaite, en apportant une réduction de la complexité globale d’une application ainsi que certains bonus.
Problématiques
Il a été constaté que les premières étapes de la transformation en microservices d’une application amenaient, souvent, en réalité, des évolutions de complexité bien différentes à ce qui était attendu. En effet, on a pu observer, à de nombreuses reprises, une complexité fonctionnelle stagnante et une augmentation sensible de la complexité et de la dette techniques. Ci-après quelques exemples de problématiques relatives à la transformation d’un monolithe en microservices pouvant être une des causes de ces décalages.
-
Résilience
Pour permettre aux microservices de communiquer entre eux, de nombreux échanges réseaux sont nécessaires. Or, le réseau est le facteur le moins stable de tout système :
-
- non fiable
- temps de latence non nuls
- bande passante limitée
- équipements hétérogènes
- …
Tout appel réseau se doit donc d’être résilient et il faut garder en tête que de trop nombreux appels peuvent amener une certaine latence.
-
Erreurs
Une fois la problématique réseau résolue, comment en traite-t-on les erreurs ? Celles-ci ne doivent en aucun cas être cachées (et simplement consister en une erreur 500 qui remonte à travers les différentes briques jusqu’à l’utilisateur final), sinon comment savoir quel traitement a puou non, être effectué ? Comment sait-on ce qu’il faut rétablir pour faire un rollback cohérent ? Que doit-on faire si deux microservices au milieu de la chaîne de traitements n’ont pas réussi à communiquer correctement ? Ou qu’ils l’ont fait partiellement ?
Toutes ces questions doivent avoir une réponse et celle-ci ne peut pas être simplement technique. Ces problèmes potentiels doivent être identifiés et une solution doit leur être apportée dès la phase de design/conception.
-
Technologies transverses
De très nombreuses technologies permettent de concevoir des microservices et il n’y en a pas forcément une qui prévaut vis-à-vis des autres. Et c’est très compliqué car, quand on a le choix parmi toutes ces technologies, on se retrouve avec une problématique de compréhension et on essaie de tout mixer ensemble.

Une fois le choix réalisé, on se rend compte, la plupart du temps, que ce sont aujourd’hui des technologies qui coûtent cher à mettre en place.
-
Périmètre fonctionnel
La facilité de transformation d’un monolithe en microservices dépendra de l’état de ce monolithe, d’un point de vue fonctionnel. En effet, la simple transformation technique d’une application mal organisée fonctionnellement résultera en des microservices mal organisés.
Par ailleurs, le microservice doit avoir un périmètre fonctionnel clairement identifié. Celui-ci peut être très difficile à évaluer, notamment car nous réfléchissons trop souvent en entités techniques. Par exemple, en essayant d’extraire une entité du monolithe puis en l’affectant à un microservice en particulier, on se rend vite compte que de cette entité peut dépendre de nombreux autres microservices. Ceux-ci ne sont alors plus indépendants fonctionnellement, ce qui est contraire à la définition d’une architecture en microservices.
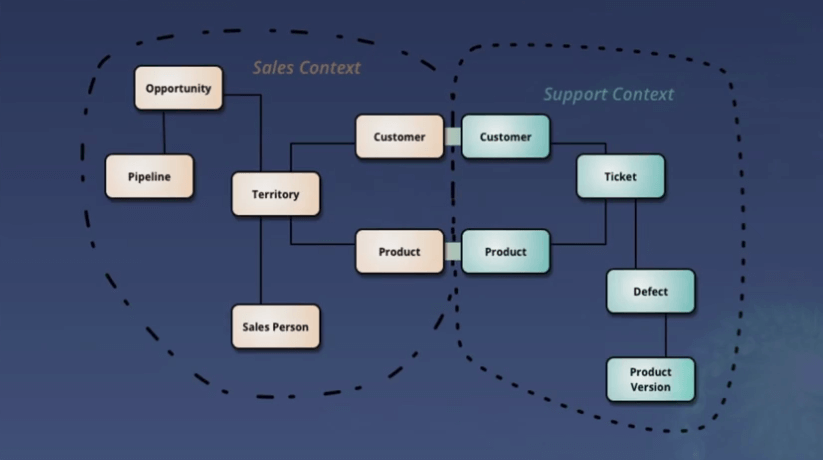
Ici, si le microservice “Sales” est amené à modifier un client, il devra y avoir une répercussion sur le microservice “Support” pour conserver une cohérence dans les données.
Le migroservice
La transformation en microservices n’est pas chose aisée et lorsqu’on l’entreprend, il arrive souvent qu’on n’y parvienne pas tout de suite. On peut alors se retrouver devant ce que François Teychené nomme des migroservices et qu’il définit ainsi :
Toute application qui s’inscrit dans une démarche microservices sans avoir les moyens de réaliser totalement la transformation.
En d’autres termes, on accepte le coût technique et la difficulté de mise en œuvre du microservice et on sait qu’on n’a pas les moyens en temps ou en budget pour obtenir une architecture parfaite. L’idée est alors de viser un intermédiaire dans la réalisation qui permettra d’apprendre des choses, d’avoir une amélioration par rapport au monolithe, tout en essayant d’anticiper au maximum les problématiques auxquelles on sera confronté.
Quelques clés
Plusieurs clés pour réussir une transformation en microservices
- Pré-requis
- Changement de mindset
- Définition de périmètres fonctionnels et non techniques.
- Domain Driven Design.
- Éviter un split reflétant les structures organisationnelles (Melvin Conway).
- Connaissance des technos transverses
- Bruit par rapport au monolithe (montée en compétences nécessaire).
- Coûts importants de mise en œuvre.
- À croiser avec le besoin fonctionnel (une bonne implémentation technique ne suffit pas !).
- Changement de mindset
- Points de vigilence
- Anticipation des comportements (fonctionnels) en cas d’erreurs propres aux microservices (ex : réseau)
- Le fait de scaler une application qui a de l’état peut poser problème.
- Anticiper au maximum logging et monitoring (plus compliqués en microservices).
- Prévoir une automatisation intégrale des chaînes de développement/déploiement.
En conclusion
On pourra retenir de ce talk ce que sont et ne sont pas les microservices et migroservices. En substance les microservices :
- ne sont pas un simple choix architectural
- nécessitent un investissement important qui peut rapporter beaucoup
- requièrent un changement de mindset fonctionnel
- exigent l’ajout de contraintes techniques

Les migroservices quant à eux :
- sont souvent la conséquence de problématiques mal anticipées
- ne sont pas un problème (mais une étape intermédiaire)
- il faut capitaliser sur leur implémentation
- permettront de parvenir aux microservices (technique + fonctionnel)
Bilan de cette troisième édition
Que retenir de ce Devfest 2019 ? Tout simplement qu’il s’agissait une nouvelle fois d’un très bon millésime. L’organisation et la logistique étaient bien réglées, les conférences variées et de qualité. On regrettera juste la disparition des codelabs. Mais la multitude de goodies distribués sur les stands nous ferons vite oublier ce petit bémol.
Soyez assurés que nous seront présents (et sponsor) pour l’édition 2020 ! Vivement, donc.

