
Régulièrement, nous apprenons dans la presse que telle ou telle grande entreprise a subi un piratage informatique, donnant accès aux attaquants à toutes les données de leurs utilisateurs.
Plus grave, dans certains cas, ces données sont utilisées par les attaquants pour se faire passer pour les victimes et obtenir des services en leur nom, les laissant bien souvent redevable pour le service fourni.
Une centralisation de ces identités crée donc un point unique de défaillance, mais peut aussi engendrer un usage abusif de toutes ces informations par l’entité qui les détient (toute ressemblance avec un quelconque réseau social est purement volontaire).
Dans la vie quotidienne, il est parfois nécessaire de démontrer son identité ou un élément qui nous est propre, tel que l’adresse de notre domicile, les diplômes que nous possédons …
Ces éléments sont parfois fournis sous forme physique, avec un document papier, parfois sous format électronique, en envoyant un email ou en remplissant un formulaire en ligne.
2 problèmes se posent alors :
- Il est nécessaire à une personne d’effectuer le travail de collecte et de traitement de l’information (lecture du document ou du mail, déclenchement d’une action suite à l’acquisition de ces informations …)
- Les données ainsi obtenues ne sont pas forcément mises à jour. Il est difficile de savoir si un justificatif de domicile imprimé il y a plusieurs mois est toujours valable.
De ces constats, l’idée de Self-Sovereign Identity (SSI) émerge.
Il s’agit de remettre l’utilisateur au centre du système. Il reste maître de ses données, qui ne sont stockées nulle part ailleurs que dans un périmètre lui appartenant (smartphone, PC …).
Des émetteurs lui fournissent ses éléments d’identité, chacun selon son domaine d’activité, et créent des preuves de la validité de ces éléments. Lorsqu’il veut accéder à un service, il présente les éléments requis. Le fournisseur du service peut aller vérifier la validité des informations présentées en consultant les preuves.
Et tout peut se faire automatiquement, sans intervention humaine, sans délai. La création, la suppression, la mise à jour peuvent être déclenchées automatiquement ou sur demande. L’information est immédiatement et automatiquement mise à disposition de qui en a besoin.
L’utilisateur garde le contrôle de tout ce processus. Rien le concernant ne transite sans son accord.
Les différents acteurs, les émetteurs, les utilisateurs et les vérificateurs (fournisseurs de service soumis à condition) possèdent des éléments cryptographiques propres assurant qu’ils sont bien à l’origine de telle demande ou telle information.
Tous sont regroupés en réseau, interconnectés, sur un pied d’égalité. Il n’existe aucune autorité centrale qui regroupe toutes les informations et par qui tout le monde passe. Ainsi, pas de point de défaillance unique et pas de butin alléchant pour les pirates en recherche d’identités à usurper.
Dans cet environnement décentralisé, la blockchain a trouvé une place de choix. Quelques concepts clés viennent s’y greffer.
Identifiant décentralisé (Decentralized Identifier : DID)
Il s’agit d’associer un identifiant unique (token) à chaque donnée personnelle. Ainsi, la donnée est masquée et reste dans la sphère privée de l’utilisateur. 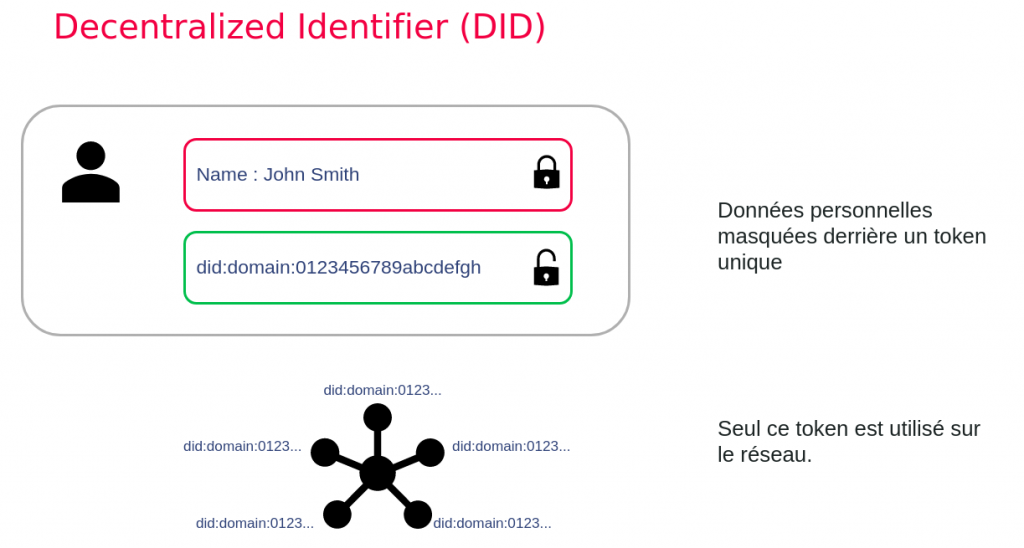
Le réseau n’a connaissance que de cet identifiant et pas des données masquées.
Les tokens DID ont un format particulier, qui permet de préciser quel est leur domaine d’émission. On peut ainsi faire cohabiter sur un même réseau plusieurs sources de données.
Verifiable credentials
Le concept de Verifiable Credentials, qui est aussi un standard W3C, consiste à garantir à un fournisseur de service la validité d’une information, émise par une source de confiance.

Un émetteur (par exemple, un gouvernement qui émet des titres d’identité à ses citoyens) fourni les éléments d’identité à ses utilisateurs.
Parallèlement à ça, il crée des preuves de ces éléments (une empreinte cryptographique par exemple). Cette preuve est stockée dans un registre. Il peut également y enregistrer la révocation de ces informations.
L’utilisateur s’inscrit dans le registre, pour associer ses informations aux preuves qu’il contient.
Lorsqu’il souhaite bénéficier d’un service, il présente ses informations. Le fournisseur du service peut alors comparer ce qu’on lui présente avec les preuves présentes dans le registre. Il peut ainsi être sûr que les éléments que l’utilisateur produit sont encore valide et ont été émis par une entité de confiance.
Bien entendu, tout ceci n’est possible que si les utilisateurs, les émetteurs et les validateurs (fournisseurs de service) font partie d’un même réseau de confiance, où les preuves sont stockées de façon sécurisée et immuables. (N’a-t-on pas parlé de blockchain un peu plus haut ? 🙂)
La preuve à divulgation nulle de connaissance (Zero Knowledge Proof, ZKP)
La preuve à divulgation nulle de connaissance découle directement des Verifiable Credentials.
Le concept est simple : prouver un fait, sans dévoiler l’information à l’origine de ce fait.
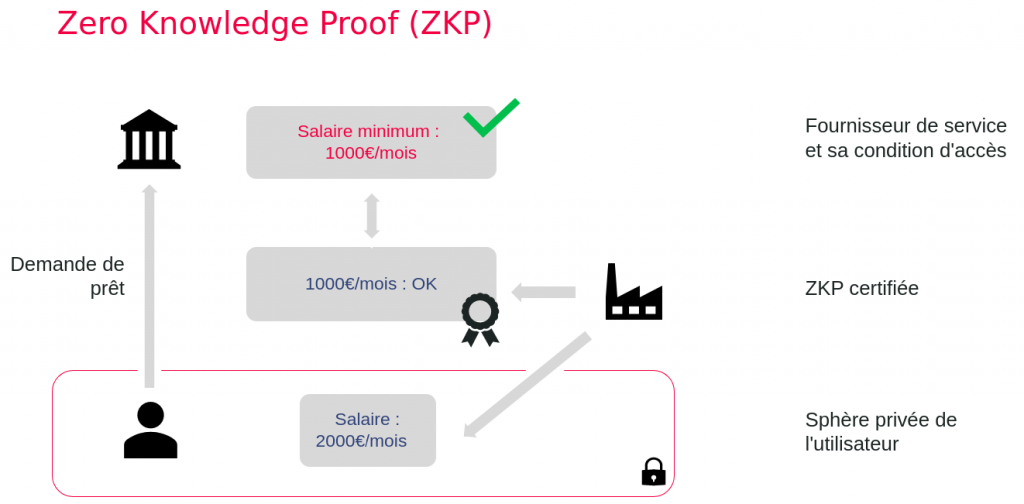
Par exemple, un utilisateur souhaite obtenir un prêt à la banque. La banque pose une condition : gagner un salaire minimum de 1000€ par mois.
L’utilisateur gagne 2000€ par mois, donc il répond à la condition. Cependant, il ne souhaite pas communiquer son salaire à la banque. Comment prouver qu’il remplit bien la condition ?
C’est là que la ZKP entre en action. L’employeur de l’utilisateur va émettre une ZKP validant la condition que le salaire est supérieur à 1000€, sans rien dévoiler de plus. La banque va avoir accès à cette preuve, et pourra donc traiter le dossier.
Là encore, le fonctionnement en réseau de confiance est nécessaire.
RGPD ?
Une interrogation qui revient souvent sur le sujet et sa compatibilité avec RGPD. En effet, comment conjuguer le fait de pouvoir assurer une destruction des données personnelles d’un utilisateur lorsqu’elles ne sont plus utiles ou que l’utilisateur le souhaite, avec la blockchain, qui par définition stocke ses données de façon immuable ?
La réponse à cette question est extrêmement simple : aucune donnée personnelle n’est stockée dans la blockchain.
On n’y trouve alors que des empreintes cryptographiques, des informations sur les formats de données, etc.
Ainsi, les données personnelles ne sont ni stockées à vie, ni partagées avec les autres membres. Et elles restent même en possession de leur propriétaire uniquement.
Et concrètement ?
On trouve plusieurs implémentations de ces concepts.
Sovrin a mis en place un réseau d’identités décentralisées sur internet. Ils ont créé leur propre blockchain afin de proposer ce service, public, ouvert à tous.
Leur produit a ensuite été intégré au projet Hyperledger sous le nom d’Hyperledger Indy.
Un cas d’utilisation notable : la province canadienne de Colombie Britannique a mis en œuvre Indy afin de réduire la lourdeur de ses procédures administratives. La première étape de ce projet a été déployée en Janvier 2019 et concerne l’enregistrement des organisations commerciales. Il leur permet de certifier la possession de licences, permis et autres accréditations.
Indy est une blockchain à destination de consortiums. Les consensus sont plutôt de type collaboratif. Le service ne repose sur aucune cryptomonnaie.
Sur le même principe que Sovrin, Civic développe un service d’identités décentralisées, mais celui-ci est basé sur Ethereum. Le service est public, tout utilisateur, émetteur ou vérificateur peut le rejoindre. Mais en contrepartie, les transactions sont payantes, une cryptomonnaie joue le rôle de carburant au sein du réseau, pour monétiser les échanges. Les utilisateurs peuvent ainsi monnayer l’accès à leurs informations, et les émetteurs, leur service d’émission.
Il existe également un projet similaire avec uPort.
Début mai 2019, Microsoft a annoncé travailler sur le projet ION (Identity Overlay Network). Un système de gestion des identités basé sur la blockchain Bitcoin.
Toutes ces initiatives sont portées par des organisations membres de la DIF (Decentralized Identity Foundation), une fondation créée pour développer le concept d’identités décentralisées, regrouper les projets et établir des standards.
De son côté, sur le même modèle que celui qu’il a su imposer pour les smart contracts avec son standard ERC-20, Ethereum est en train de travailler à la définition d’un protocole de gestion des identités, le standard ERC-725.
Le sujet est donc pris très au sérieux et suivi par un grand nombre d’acteurs.
Il peut intéresser les entreprises qui souhaitent constituer un écosystème avec leurs partenaires, où il sera nécessaire de gérer de façon simple et automatique les accès et autorisations d’une multitude d’utilisateurs à des services appartenant à des organisations différentes, mais sans dévoiler trop d’informations aux organisations auxquelles un utilisateur n’appartient pas.
Dans une optique de fonctionnement public et à plus grande échelle, il intéressera aussi les partisans d’un web décentralisé, avec l’utilisateur remis au centre des préoccupations et maître de ses données. Bref, la vision du web à ses origines.
Affaire à suivre !
Liens :
DID : https://w3c-ccg.github.io/did-spec/
Verifiable Credentials : https://www.w3.org/TR/verifiable-claims-data-model/
Sovrin : https://sovrin.org/
Hyperledger Indy : https://www.hyperledger.org/projects/hyperledger-indy
Etude de cas Colombie Britannique : https://www.hyperledger.org/resources/publications/orgbook-case-study
Decentralized Identity Foundation : https://identity.foundation/
Standard ERC-725 : https://erc725alliance.org/
Article précédent sur les blockchains : https://blog.ineat-group.com/2018/11/la-blockchain-non-des-blockchains/

1 Comment
Comments are closed.