
Après un démarrage majoritairement consacré aux universités, nous enchaînons notre deuxième journée au Devoxx France 2019. Plus d’université mais des conférences, tools-in-action et hands on labs à foison, suivi d’un Meet and Greet en début de soirée. Débrief complet des principaux talks que nous avons suivi.
Les talks de cette seconde journée
Mob Programming : je ne développerai plus jamais seul
Speakers : Alexandre Victoor et Johan Rouve
Devoxx est très riche en conférences sur les frameworks et outils, mais on y parle également de pratiques de développement !
Ce talk a été l’occasion pour Alexandre et Johan de faire un retour d’expérience sur le mob programming dans leur équipe de 5/6 développeurs. Cette pratique qui s’est installée naturellement dans l’équipe.
Concrètement, qu’est ce que c’est le mob programming ?
All the brilliant people working on the same thing, at the same time, in the same space, on the same computerWoody Zuill, créateur du mob programming
- un driver aux commandes, qui tape sans trop réfléchir
- plusieurs navigateurs, qui réfléchissent à la solution la plus pertinente pour implémenter la fonctionnalité, débattent, …
- Quels sont les bénéfices ?
Le principal avantage est sans doute le partage des connaissances et une montée en compétence de l’ensemble de l’équipe.
- Est-ce qu’on perd en productivité quand on est 5 à travailler sur la même feature ?
Pas nécessairement puisque les points de blocage rencontrés individuellement, voire parfois en pair-programming, trouvent plus facilement une issue.
- Quels sont les effets inattendus rencontrés après quelques mois de pratique ?
Certains participants un peu introvertis pourraient se replier davantage sur eux-même, en particulier si d’autres participants monopolisent l’attention. Il est essentiel d’observer le comportement de chacun, et solliciter chaque membre de l’équipe.
- De quoi a-t-on besoin pour mettre en place cette pratique ?
Côté organisation, on a simplement besoin d’un timekeeper (ce qui n’est pas difficile à mettre en oeuvre). Cependant le mob programming n’est efficace que si les participants savent travailler en équipe, souhaitent participer au mob (qui ne doit être vu comme une contrainte), et si la qualité de code est considérée comme point essentiel par l’équipe.
Du réactif au service du pneu connecté
Speakers : Fabien Pomerol et Julien Ponge
Fabien Pomerol et Julien Ponge nous parlent d’un de leur projet : la collecte d’informations issues de capteurs embarqués dans les pneus Michelin. Au delà de la récupération de ces données en RFID et de leur affichage sur la console des véhicules, l’objectif était de mettre en place une architecture réactive à base de microservices en Vertx.
L’ensemble du système a été non seulement décrit, mais chaque entité a fait l’objet d’un petit live coding durant lequel une ré-implémentation triviale a été effectuée (le but étant d’illustrer concrètement chaque concepts).
Ainsi nous avons pu voir comment les messages étaient échangés entre services via Kafka ou appel Http, mais aussi la communication entre verticles d’un même service via Event Bus.
Les speakers nous ont également parlé de Reactive Programing et ont illustré leur propos avec une démonstration du couplage RxJava / Vertx. La démo qui aura retenu le plus notre attention est sans conteste la mise en place d’une communication back / front avec l’Event Bus Vertx, permettant de mettre à jour en temps réel une page web affichant les données d’une centaine de capteurs.
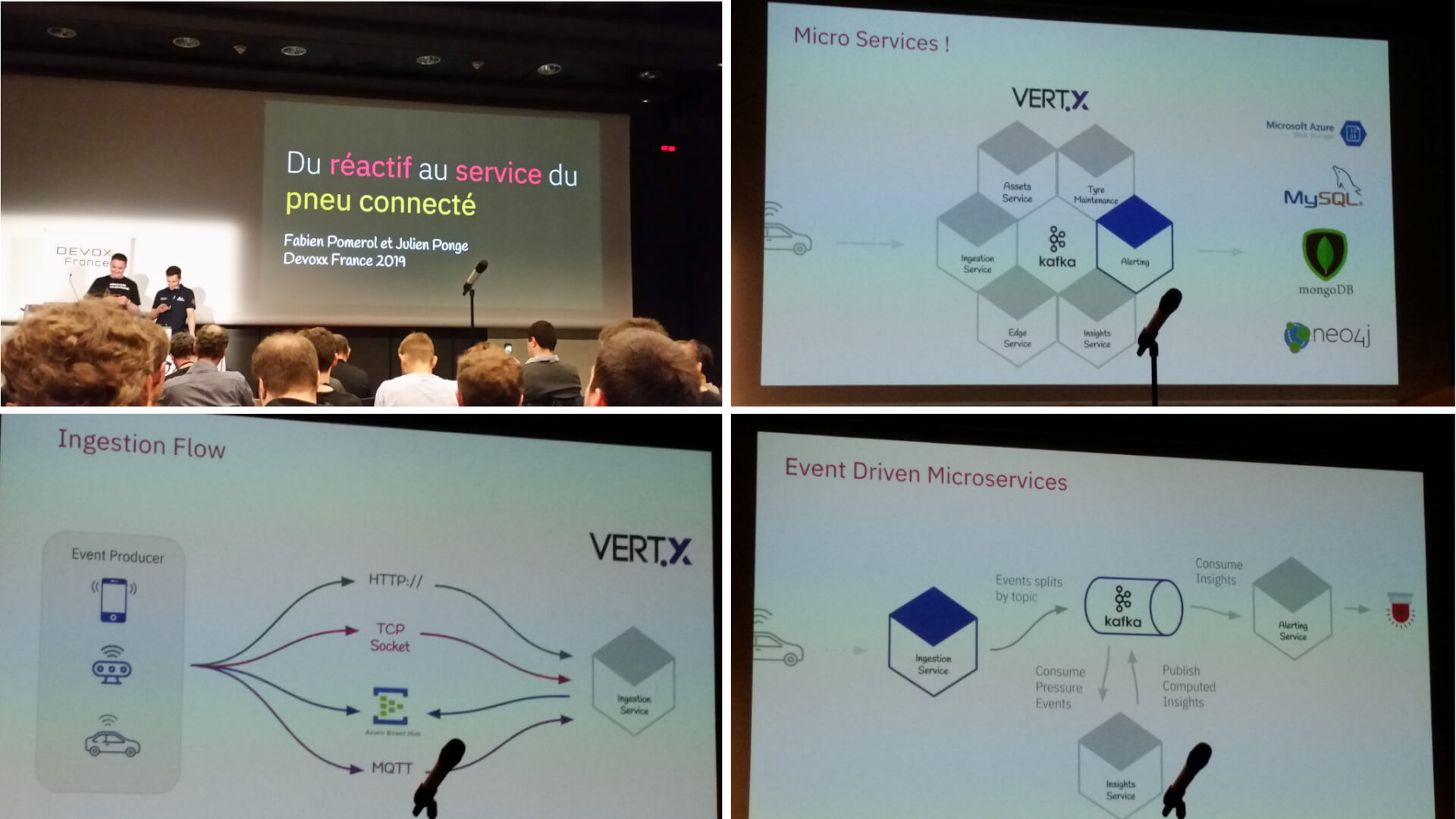
Fabien Pomerol termine le talk en donnant ses impressions sur Vertx, et qu’en somme ce toolkit offre de très bonnes performances mais que la courbe d’apprentissage est parfois importante.
Un retour d’expérience comme on les aime !
JUnit : il serait temps de passer la 5ème !
Speakers : Juliette de Rancourt et Julien Topçu
JUnit 4 a 13 ans, et pourtant, c’est la version majeure utilisée par une très grande majorité des développeurs Java ! Alors qu’est-ce qui nous empêche de passer à la nouvelle version, sortie il y a 1 an et demi ?
L’équipe JUnit a totalement restructuré sa librairie, la migration vers cette “nouvelle” version ne se fait donc pas uniquement en changeant le numéro de version dans votre outil de gestion de dépendance favori. Cependant, ça reste quand même très simple, et cette nouvelle version vient avec des nouveauté assez intéressantes :
- la nouvelle manière de faire des tests paramétrés, qui est bien plus simple que dans JUnit 4
- les nouvelles assertions, non bloquantes, qui permettent de savoir si plusieurs asserts sont en erreur (même si on continuera à utiliser AssertJ, soyons honnêtes)
- la possibilité de nommer ses tests, ou bien de donner une stratégie de nommage (remplacer les underscores par des espaces par exemple)
- la possibilité d’avoir des inner-class (nested) qui permettent d’avoir de définir un état particulier dans lequel les tests s’exécutent
@DataJpaTest
@ExtendWith(SpringExtension.class)
@InjectBookmark
class BookmarkRepositoryTest {
@Autowired
private JpaBookmarkRepository jpaBookmarkRepository;
private BookmarkRepository bookmarkRepository;
@BeforeEach
void set_up() {
bookmarkRepository = new BookmarkRepository(jpaBookmarkRepository);
}
@Test
@DisplayName("Should save a bookmark")
void should_save_bookmark(@Video Bookmark bookmark) {
Bookmark saved = bookmarkRepository.save(bookmark);
assertThat(saved).isEqualTo(bookmark);
}
@Nested
@DisplayName("When a bookmark is saved")
class WhenBookmarkIsSaved {
private Bookmark savedBookmark;
@BeforeEach
void set_up(@Random Bookmark bookmark) {
jpaBookmarkRepository.save(BookmarkEntity.from(bookmark));
savedBookmark = bookmark;
}
@Test
@DisplayName("it's not possible to save it again")
void should_not_save_an_already_existent_bookmark() {
assertThrows(
AlreadyBookmarkedException.class,
() -> bookmarkRepository.save(savedBookmark),
savedBookmark.getUrl() + " is already bookmarked"
);
}
// ...
}
}
- l’ajout de parameter resolver, qui permettent d’injecter des données en entrée du test à l’aide d’une annotation créée par vos soins, ce qui rendra l’initialisation des données de test moins laborieuse
@Test
@DisplayName("Should save a bookmark")
void should_save_bookmark(@Video Bookmark bookmark) {
Bookmark saved = bookmarkRepository.save(bookmark);
assertThat(saved).isEqualTo(bookmark);
}
public class BookmarkParameterResolver implements ParameterResolver {
@Override
public boolean supportsParameter(ParameterContext parameterContext, ExtensionContext extensionContext) throws ParameterResolutionException {
return parameterContext.getParameter().getType() == Bookmark.class;
}
@Override
public Object resolveParameter(ParameterContext parameterContext, ExtensionContext extensionContext) throws ParameterResolutionException {
if (parameterContext.isAnnotated(Video.class)) {
return Bookmark.create("http://www.youtube.com/watch?v=ABCD", "Cool video", emptySet());
}
return Bookmark.create("http://www.google.com", "Default bookmark", emptySet());
}
}
Le code utilisé pour le live coding de ce tools-in-action est disponible ici : https://gitlab.com/crafts-records/remember-me
APIs, Microservices et Service Mesh
Speaker : Joel Gauci
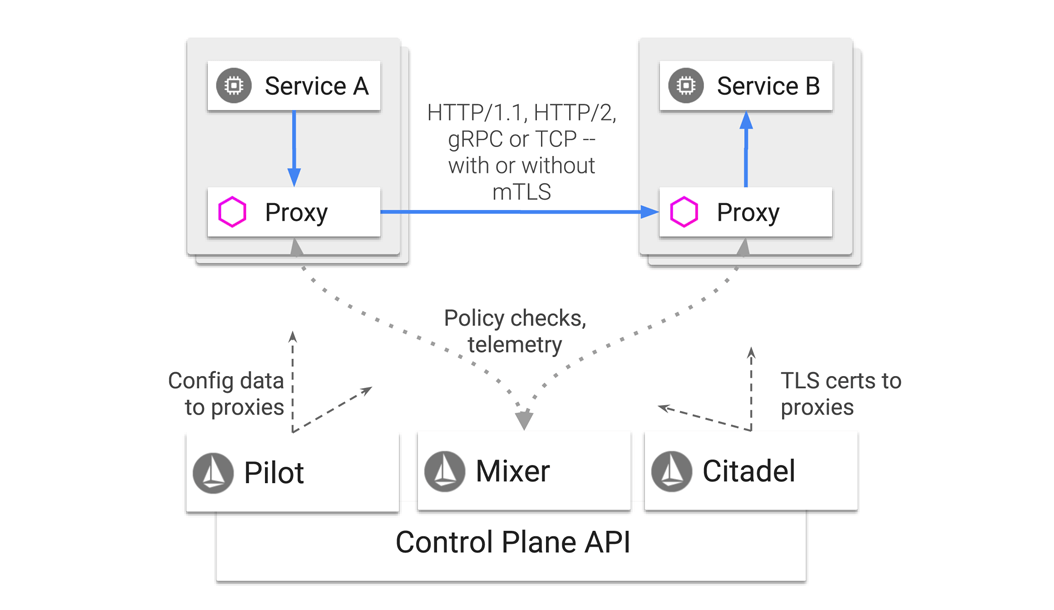
APIs, Service Mesh, API Management, Microservices… il est vrai qu’on peut parfois s’y perdre. Rien de tel qu’un bon talk pour redonner quelques définitions et rappeler le rôle de l’API Management et du Service Mesh. Joel Gauci nous a donné une conférence de qualité et nous a tout d’abord présenté Istio et comment l’intégrer dans une application existante. Les mécanismes internes d’Istio ont été détaillés :
- de quelle façon les sidecar proxy sont ajoutés a chaque Pod contenant nos microservices.
- comment le Mixer assure la télémétrie
- le fonctionnement de Citadel, et la gestion de la sécurité
- comment mettre en place des règles de sécurités (ex : un microservice A pouvant contacter un microservice B mais pas C)
- comment gérer le trafic entre microservices (ex : 80 % des requêtes de A sont routées vers B, et 20 % vers C)
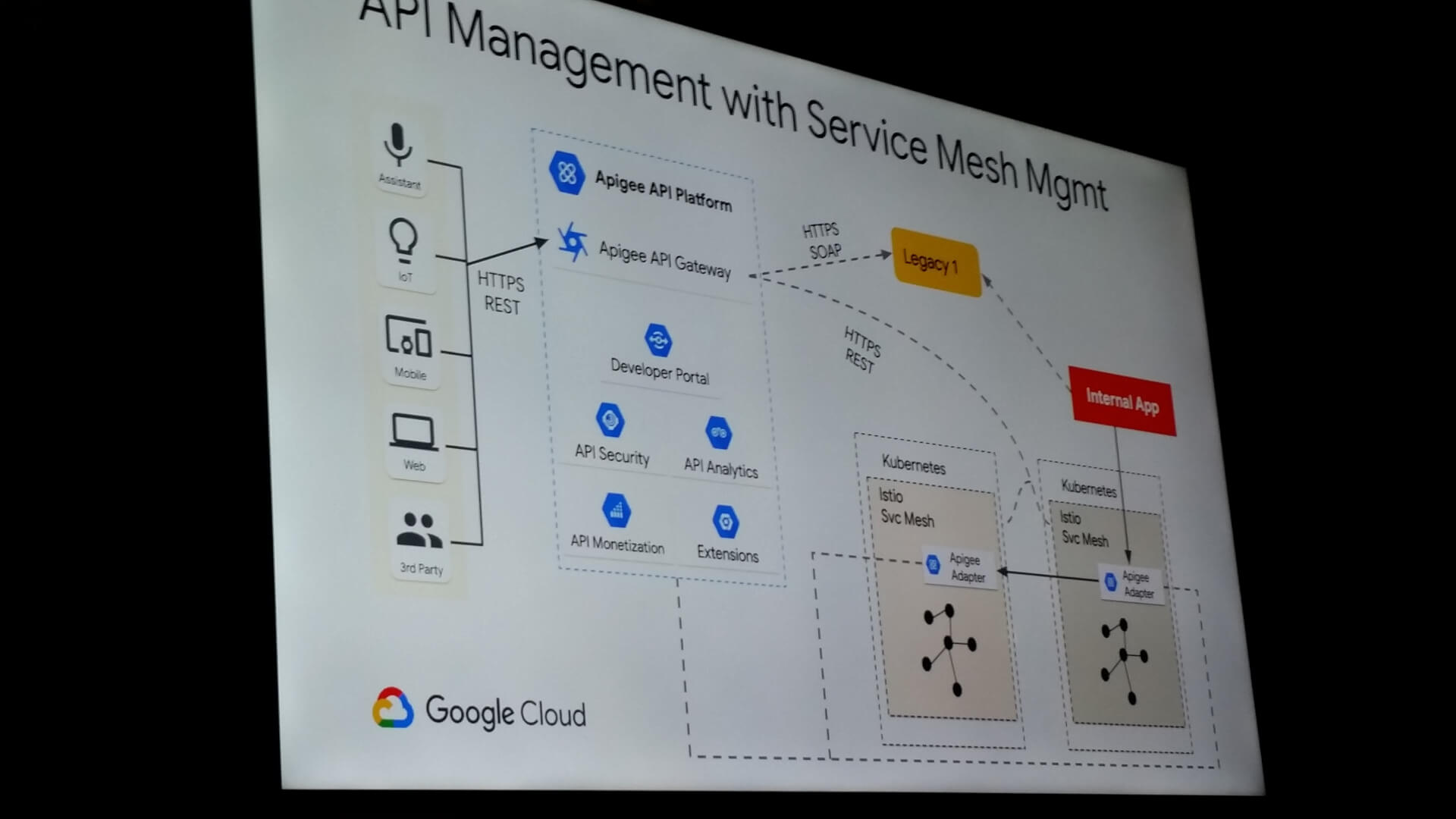
Durant le second tiers de la conférence, notre speaker nous a rappelé le rôle de l’API Management et présenté la solution Apigee, simplifiant la gestion des APIs évoluant dans des univers multi-cloud ou cloud hybride.

Le speaker conclura pas une démonstration rapide, mettant en évidence que l’association API Management et Service Mesh est tout à fait possible. L’idée est ici de garder le meilleur des deux mondes :
- observabilité et portail avec Apigee.
- application de politiques de trafic et sécurité entre micro-services avec Istio.
D’une architecture N-Tiers à une architecture Clean Hexagonale
Speakeuse : Céline Gilet
Afin de répondre à la forte demande de participation aux hands-on, Devoxx a mis en place un système de ticket à récupérer 30 minutes en avance pour limiter les frustrations de ceux qui font la queue pour participer à ces sessions (limitées en place) sans avoir de place.
Nous avons réussi à nous procurer un de ces précieux sésames et à participer au hands-on organisé par Céline Gilet.
L’objectif : refactorer une application legacy, en séparant la technique du métier, et ajouter un niveau d’abstraction vis à vis des composants techniques.
Présentation de l’application
Cette application (https://github.com/celinegilet/happy-town), dont le métier semble très simple, consiste à envoyer deux mails à la date anniversaire d’arrivée d’un habitant dans la ville Happy Town :
- le premier pour inviter l’habitant à récupérer un cadeau qui lui est destiné (ce cadeau étant déterminé de manière aléatoire, en prenant en compte l’âge du bénéficiaire)
- le second pour fournir au service cadeau de la mairie le récapitulatif des cadeaux attribués aujourd’hui
Notre application interagit donc avec :
- une base de données (en lecture et écriture)
- un serveur d’envoi de mail
- un fichier listant les cadeaux selon les tranches d’âge
Et son traitement peut être déclenché par :
- une commande lancée par le terminal
- une API
- une tâche automatique pour que les envois soient fait quotidiennement
Constat
Un bref audit du code nous montre rapidement que le code est mal découpé, que le modèle d’architecture n-tiers (controller, service, repository), tel qu’il a été utilisé ici, entraîne un fort couplage entre le métier et les frameworks. Il suffit de regarder le code de HappyTownService.java pour s’en rendre compte.
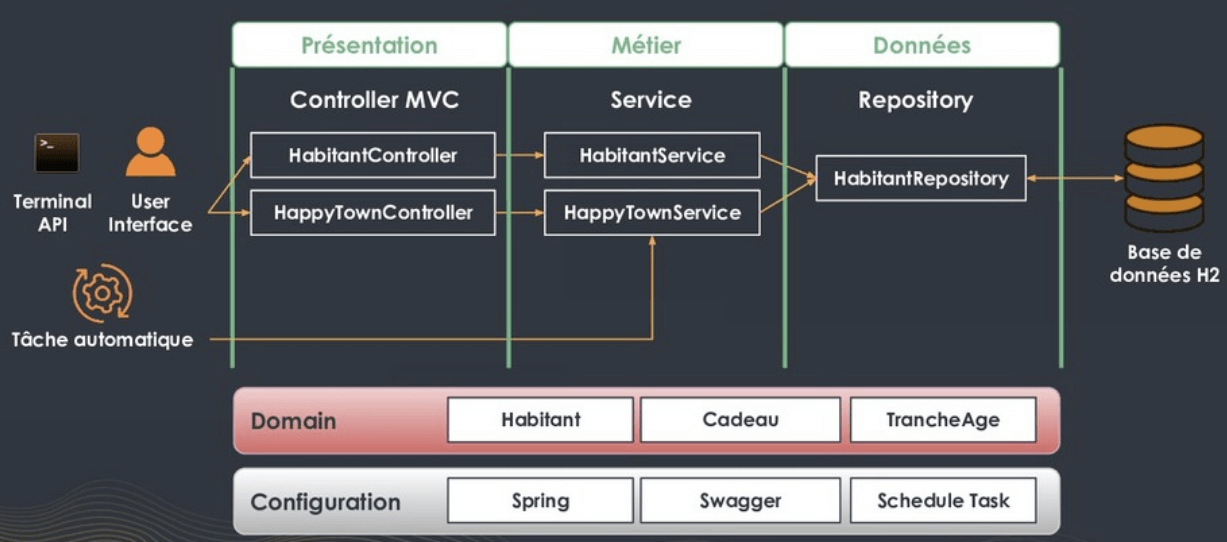
- le code métier est noyé dans les problématiques techniques
- les classes métiers (Habitant, Cadeau, TrancheAge) sont également les représentations de stockage (Entity) et d’API (DTO)
- la rédaction de test est compliquée par ce manque de découpage
- le code est très fortement couplé aux composants techniques (mail et système de fichiers)
- …
Solutions
La mise en place d’une clean architecture (modèle créé par Uncle Bob) permet de régler les problèmes mentionnés ci-dessus. Ce modèle d’architecture permet d’avoir une approche orientée use case métier, et de découper le métier de la technique. Rendant le tout bien plus lisible, maintenable et évolutif.

Ce modèle d’architecture remet au centre les classes représentant le métier (on utilise un langage orienté objet, autant suivre ce paradigme) et les use cases.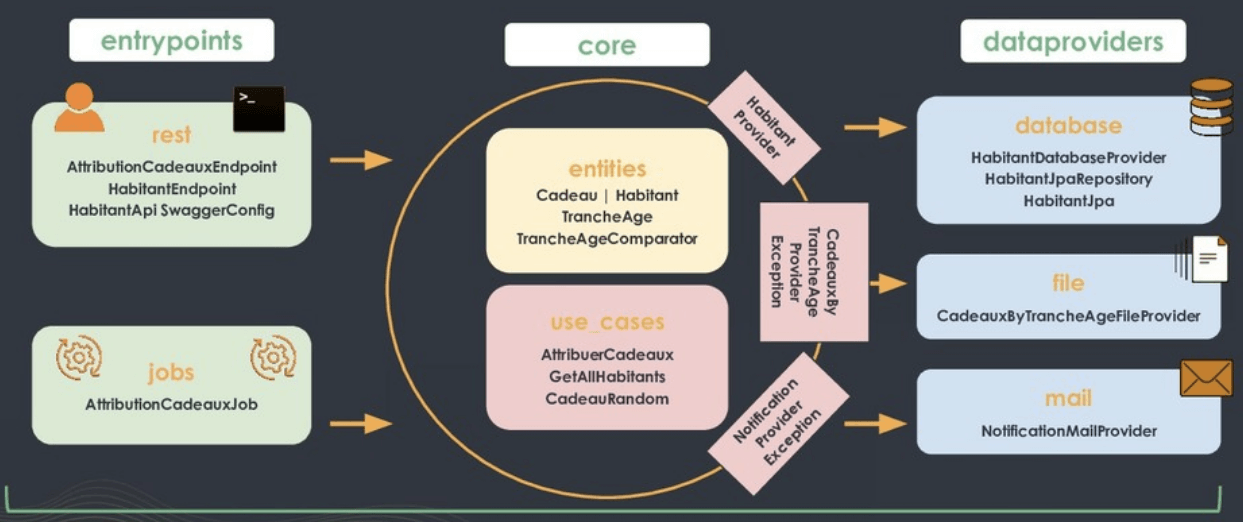 Autour du “core”, nous avons des :
Autour du “core”, nous avons des :
- entrypoints : qui déclenchent les uses cases, et exposent les entités au monde extérieur (en redéfinissant leur format en fonction des besoins)
- dataproviders : qui fournissent les informations nécessaires au déroulement des cas d’utilisations
L’architecture hexagonale (modèle créé par Alistair Cockburn), est extrêmement proche de la clean architecture. Elle utilise un vocabulaire et une organisation de la base de code légèrement différente.
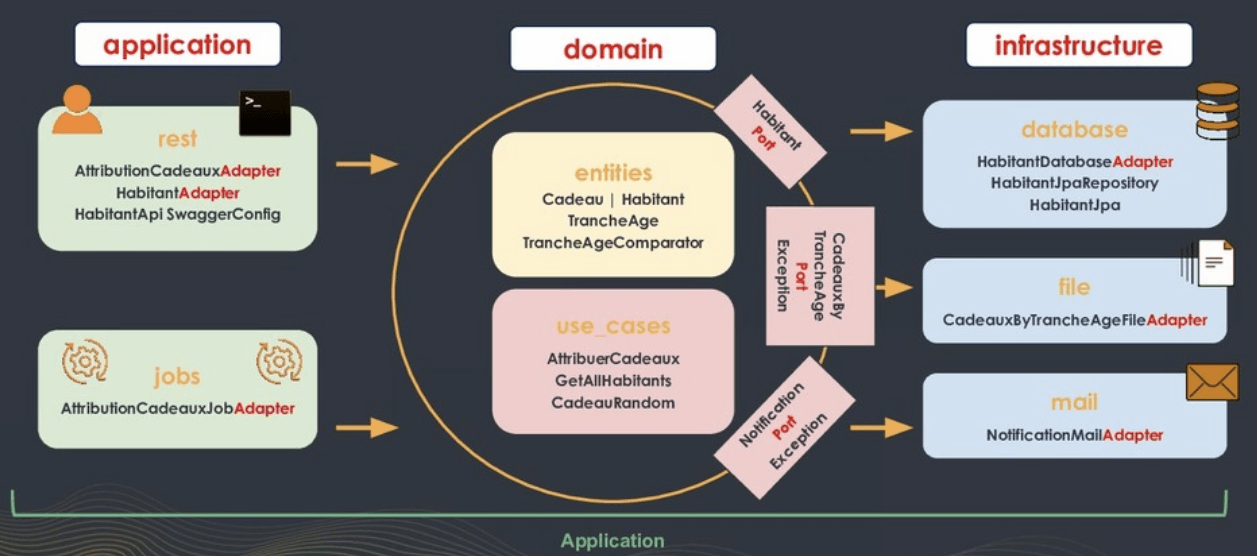 On parle ici d’application, de domain et d’infrastructure, mais surtout de Port & Adapters (qui était le nom original de cette architecture).
On parle ici d’application, de domain et d’infrastructure, mais surtout de Port & Adapters (qui était le nom original de cette architecture).
Ce hands-on a été l’occasion de mettre en application ces concepts en étant guidé par Céline, qui a réussi à nous faire basculer d’une architecture n-tiers à une clean architecture en 8 étapes.
Si le sujet vous intéresse, je vous encourage à suivre les instructions de l’atelier via les slides (https://speakerdeck.com/celinegilet/dune-architecture-n-tiers-a-une-architecture-clean-hexagonale), et à faire étape par étape les modifications sur le code, en partant de la branche start (https://github.com/celinegilet/happy-town), en vous aidant éventuellement de la solution proposée sur la branche cleanArchi (https://github.com/celinegilet/happy-town/commits/cleanArchi).
Premier pas avec un microcontrôleur et Google Cloud Iot Core
Speaker : Gautier Mechling
On observe depuis quelques années la multiplication des cartes à base de microcontrôleur, celles ci allant du simple Arduino aux cartes plus musclées comme ODROID ou Raspberry. Bien que les prix à l’unité restent abordables (de 10 à 15 euros pour un Arduino Uno), cela augmente rapidement lorsqu’on prévoit de créer une série de capteurs. L’encombrement de telles cartes est également un facteur a prendre en compte. C’est ainsi que sont apparues des modèles comme ESP 8266 et ESP 32. Très petits, ils sont commercialisés pour environ 5 euros et permettent de développer en C/C++, Python, JS, ou encore Lua.

C’est en partant de ces petits modules que Gautier Mechling nous a présenté Cloud IoT Core, la solution de Google ayant pour double rôle de simplifier la gestion des objets connectés et de rediriger les données vers les services disponibles dans GCP.
Hormis la présentation des caractéristiques techniques de ces cartes, notre speaker à principalement axé sa présentation autour d’un cas concret : la création d’un capteur de température et sa connexion à la GCP.
L’ensemble des relevés étaient publiés dans Firebase (via PubSub) et afficher dans Grafana. Le plus impressionnant dans cette présentation fut sans doute la rapidité avec laquelle il a été possible d’arriver a un produit fini. Gautier nous parlera également de Aisler pour prototyper nos composants à moindre coût.
Malgré le léger stress de notre speaker, nous avons assisté a une bonne présentation portant sur un sujet très original.
Applications web efficaces avec Spring Boot 2
Speakers : Brian Clozel et Stéphane Nicoll
Prenez une application basée sur Spring Boot MVC, ajoutez-y de la programmation réactive, améliorez la scalabilité et elle devient plus efficace. C’est ce qu’ont démontré Stéphane et Brian lors de ce talk. Ils ont commencé par nous parler de Spring Initializr, que tout le monde connaît, pour générer un projet par le biais du site ou d’un IDE. Lors de cette opération des données sont stockées dans un index, ce qui permet de disposer de statistiques sur les différents choix réalisés lors de la création comme :
- le langage
- la version de Spring Boot
- l’outil de build
- les dépendances sélectionnées, etc
La présentation est basée sur une application de type dashboard qui récupère des données dans l’index et les affiche, les informations sont :
- les événements survenus
- les statistiques sur les projets crées (nombre de projets en fonction de la version de Spring Boot)
- les données utilisateur (reverse DNS).
Stéphane commence par ajouter la dépendance à Spring WebFlux qui permet un support à la programmation réactive, puis des modifications sont apportées à un composant permettant de récupérer les différents flux de données (événements, statistiques, connexion). En remplaçant la classe RestTemplate par l’interface WebClient les appels seront asynchrones et non bloquants. L’instance de WebClient permet de disposer de la réponse complète (avec status, header) ou juste le contenu du body.
Les méthodes doivent être aussi modifiées pour retourner des types réactifs, pour cela Spring s’appuie sur le projet Reactor qui fourni deux types asynchrones :
- Mono<T> : utilisé pour 0 ou 1 éléments
- Flux<T> : utilisé pour 0 ou n éléments (collections)
Ensuite Stéphane a modifié le service qui produira des données sous la forme d’une classe Mono<T>, il a retiré le “calling block” (blocage dû au synchronisme) présent sur chaque appel au composant consommant les données de l’index. Ces changements permettent de paralléliser les tâches et les données seront agrégées sous la forme d’un tuple3 (voir projet Reactor) grâce à la méthode zip de la classe Mono mais uniquement quand celles-ci seront intégralement reçues.
C’est ce parallélisme qui permet d’optimiser les performances de l’application en cas de latence d’un des appels.
Les données présentes dans le tuple sont utilisées dans un objet Java qui sera retourné au contrôleur qui pourra les exposer.
C’est dans le contrôleur que désormais doit être réalisé le “calling block”.
Une fois ce travail d’optimisation réalisé et que tout était toujours opérationnel, Stéphane et Brian, expliquent qu’il ne suffit pas de savoir si le service fonctionne correctement (via Spring Boot Actuator) mais qu’il faudrait disposer de métriques pour savoir, par exemple, si des latences existent. Pour cela ils vont s’appuyer sur le projet Micrometer qui permet facilement de disposer d’informations sur l’état d’un service au travers d’un outil de monitoring, ici c’est Prometheus qui est choisi (en ajoutant la dépendance micrometer-registry-prometheus) mais d’autres choix sont possibles comme Dynatrace, Elastic, etc.
Ainsi avec Prometheus, diverses données sont consultables sur l’état des services de l’application et les métriques collectés sont affichés sous forme d’un dashboard créé avec Grafana, en personnalisant les graphiques on peut connaître le temps moyen de latence par service, identifier un problème et apporter les corrections nécessaires.
Pour monitorer plusieurs applications, il est possible avec Micrometer de définir un tag pour chacune d’entre elles.
La présentation se termine par un exemple d’extraction d’une information, en appliquant un filtre au header des requêtes par l’intermédiaire de l’instance de WebClient et la donnée recueillie sert a créer un métrique qui peut être affiché par le dashboard de Kibana.
Ce talk est une bonne introduction à la programmation réactive et au monitoring d’une application.
S’il te plait… dessine moi un vrai test d’intégration
Speaker : Yvonnick Esnault
Au travers des différentes conférences données lors de ce salon, on peut se rendre compte que les tests (sous toutes leurs formes) sont un vaste sujet et il est intéressant de découvrir comment certaines sociétés avec des besoins spécifiques ont développé leur solution. Dans ce talk présenté par Yvonnick, développeur au sein du CDS (Continuous Delivery Service) d’OVH, fait une démonstration d’une solution utilisée au sein des équipes de développement.
Il nous présente un projet open source du nom de Venom qui permet de réaliser des tests d’intégration, cette application a été développée en Go.
name: MyTestSuiteTmpl
vars:
api.foo: 'http://api/foo'
second: 'venomWithTmpl'
testcases:
- name: testA
steps:
- type: exec
script: echo '{{.api.foo}}'
assertions:
- result.code ShouldEqual 0
- result.systemout ShouldEqual http://api/foo
- name: testB
steps:
- type: exec
script: echo 'XXX{{.testA.result.systemout}}YYY'
assertions:
- result.code ShouldEqual 0
- result.systemout ShouldEqual XXXhttp://api/fooYYY
L’application a besoin d’un fichier yaml qui constitue une “TestSuite” dans laquelle sont crées des “TestCase” où sont décrites différentes “Step” au sein de ces étapes on réalise les opérations et les assertions, des variables globales peuvent être instanciées et d’autres sont intégrées pour disposer de la date, du numéro de l’étape, etc. Il existe également une option permettant de définir un contexte pour disposer d’un ensemble de variable tout au long de l’exécution des différentes étapes. Concernant les assertions la liste est assez conséquente (voir le dépôt) et couvre tous les cas d’usage.
L’exécution est réalisée en ligne de commande ce qui permet une intégration facile au sein de la chaîne de CI/CD, les résultats sont compréhensibles par les outils xUnit. De plus comme les tests sont sous forme de fichier Yaml, il est aisé de les intégrer dans le versionning des projets.
Yvonnick montre le fonctionnement de Venom en s’appuyant sur une application basique pour laquelle il doit vérifier les cas d’usage suivant :
- Inscription sur une application
- Vérifier le mail envoyé par l’application
- Le mail contient une URL, ouvrir cette URL pour valider l’inscription
- S’authentifier avec le nouveau compte créé
- Naviguer sur l’application Web
- Vérifier en DB, ou sur votre API que les données sont cohérentes
Afin de réaliser chaque opération, il est nécessaire de faire appel à des “Executors” : par défaut dans une “Step” il est du type “exec” (permettant d’utiliser des scripts). Il s’agit ici d’un exemple, mais sachez qu’il en existe d’autres pour interagir avec un navigateur, exécuter des requêtes HTTP, interroger un serveur IMAP ou SMTP, ou encore lire un fichier. En cas de besoin particulier, Yvonnick précise qu’il est facile de réaliser une implémentation : il suffit de lire les indication données sur le dépôt de l’application. Et pourquoi pas proposer une pull request !
La prise en main de Venom semble facile, les scénarios sont rapidement écrits, leur compréhension aisée et ils s’exécutent rapidement. Bref cette présentation nous a permis de découvrir une nouvelle solution pour mettre en place des tests d’intégration sans avoir à utiliser un énorme écosystème.
Bilan de la journée
Une nouvelle journée passionnante qui s’est terminée par un Meet and Greet avec les autres conférenciers, occasion pour nous d’échanger autour d’une bière et de quelques planches de charcuteries. La troisième et dernière partie de notre suite d’articles consacré au Devoxx France 2019 est pour bientôt 😉
Liens utiles
- Debrief de notre première journée au Devoxx France 2019 – https://blog.ineat-group.com/2019/04/devoxx-france-2019-jour-1/
- Debrief de notre seconde journée au Devoxx France 2019 (vous le consultez actuellement)
- Debrief de notre troisième journée au Devoxx France 2019 – https://blog.ineat-group.com/2019/05/devoxx-france-2019-jour-3/
- Documentation officielle de Vertx – https://vertx.io/docs/
- Les slides de la présentation intitulée “Du réactif au service du pneu connecté” – https://speakerdeck.com/jponge/du-reactif-au-service-du-pneu-connecte
- Documentation officielle de Istio – https://istio.io/docs/
- Apigee Adapter pour Istio – https://docs.apigee.com/api-platform/istio-adapter/concepts
- Tutoriel sur l’intégration d’un ESP à Cloud IoT Core – http://nilhcem.com/iot/cloud-iot-core-with-the-esp32-and-arduino
- Documentation de WebFlux – https://www.baeldung.com/spring-webflux
- Documentation WebClient – https://www.baeldung.com/spring-5-webclient
- Project reactor – https://projectreactor.io/
- Projet Micrometer – https://micrometer.io/
- Projet Prometheus – https://prometheus.io/
- Projet Grafana – https://grafana.com/
- Dépôt de Venom – https://github.com/ovh/venom
