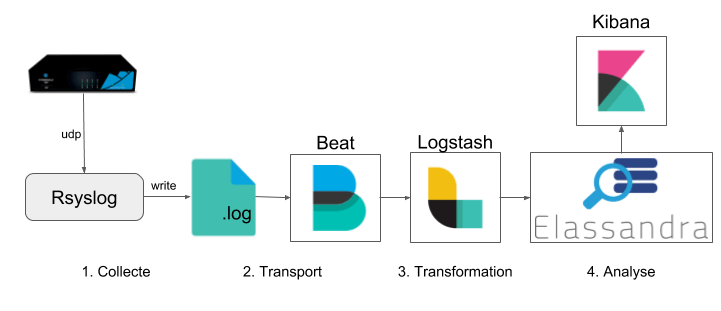
Vos applications et middlewares produisent continuellement de précieux logs qui sont en général écrits dans des fichiers, éparpillés dans votre SI. Il est essentiel pour mener des analyses approfondies de les collecter et de les centraliser dans un système comme Elassandra – une distribution améliorée de Elasticsearch.
Si la centralisation des logs applicatifs est largement documentée et donc rapide à mettre en place, celle des équipements réseaux l’est beaucoup moins. Pour remédier à ce manque, nous allons voir étape par étape comment tirer profit des logs générés par votre pare-feu pour monitorer le trafic réseau de votre entreprise.
Vue d’ensemble
La solution que nous allons présenter est basée sur ELK. La suite de cet article assume que vous soyez déjà familier avec cette technologie.
La procédure suivante a été testée sur un pare-feu de la marque Stormshield, mais devrait fonctionner avec tous les modèles capables d’envoyer leurs journaux via le protocole Syslog.
Étape 1 : Collecte des logs du pare-feu
À première vue, le pare-feu ressemble à une boite noire, pas très bavarde.

Heureusement, son interface de configuration permet d’activer l’envoi de traces réseaux vers un serveur distant, via le protocole Syslog.
Nous créons une VM ou un conteneur Linux qui va réceptionner les traces envoyées par le pare-feu et les persister dans un fichier en attendant de les traiter plus sérieusement. Pour cela nous installons Rsyslog :
# RedHat yum install rsyslog # Debian apt-get install rsyslog # Alpine apk add rsyslog
et nous le configurons de la façon suivante :
# /etc/syslog-ng/conf.d/stormshield.conf
source stormshield {
udp(port(514));
};
destination hosts {
file("https://d3uyj2gj5wa63n.cloudfront.net/var/log/remote/firewall/traces.log" owner(root)
group(root) perm(0600) dir_perm(0700) create_dirs(yes));
};
log { source(stormshield); destination(hosts); }
Après démarrage de Rsyslog, si tout est bien configuré, le fichier /var/log/remote/firewall/traces.log contiendra les logs du pare-feu. La suite de la procédure ne consiste plus qu’en la configuration d’un pipeline ELK, classique.
Étape 2 : Transport et transformation avec Filebeat et Logstash
Nous utilisons le couple Filebeat / Logstash pour transformer les logs et les transporter vers notre cluster Elassandra (ou Elasticsearch).
La configuration de Filebeat est très simple :
# /etc/filebeat/filebeat.yml
filebeat.prospectors:
- input_type: log
paths:
- /var/log/remote/firewall/traces.log
fields:
logstash_dest: firewall
fields_under_root: true
output.logstash:
hosts: ["localhost:5044"]
La configuration de Logstash est plus complexe car les traces obscures arrivant du pare-feu doivent être transformées en documents JSON intelligibles, enrichis d’informations utiles comme la géolocalisation des adresses IP.
Le fichier Logstash suivant est valide pour les pare-feux de la marque Stormshield qui envoient leurs traces au format WELF (WebTrends Enhanced Log file Format). Dans le cas où votre pare-feu n’utilise pas le même format, vous allez devoir écrire votre propre script Logstash.
input {
beats {
port => 5044
}
}
filter {
# extract the timestamp
grok {
match => {
"message" => "%{MONTH}%{SPACE}%{MONTHDAY}%{SPACE}%{HOUR}:%{MINUTE}:%{SECOND}%{SPACE}%{IPV4:fw_ip}%{SPACE}%{NUMBER}%{SPACE}%{TIMESTAMP_ISO8601:timestamp_match}"
}
}
date {
match => [ "timestamp_match", "ISO8601"]
remove_field => "timestamp_match"
}
# extract key=values pairs
kv {
trim_key => "\s"
value_split => "="
# remove unwanted fields
# caution: " " before "id" is not a space but byte-mark-order character
remove_field => ["id", "message", "startime", "time", "host", "source", "type", "input_type" ]
}
# split the CPU values if logtype is "monitor"
if [logtype] == "monitor" {
mutate {
split => { "CPU" => "," }
add_field => { "[cpu][kernel]" => "%{[CPU][0]}" }
add_field => { "[cpu][user]" => "%{[CPU][1]}" }
add_field => { "[cpu][interupt]" => "%{[CPU][2]}" }
}
mutate {
convert => {
"[cpu][user]" => "float"
"[cpu][kernel]" => "float"
"[cpu][interupt]" => "float"
}
}
}
# add a label for priorities
translate {
field => "pri"
destination => "pri_label"
dictionary => [
"0", "emergency",
"1", "alert",
"2", "critical",
"3", "error",
"4", "warning",
"5", "notice",
"6", "information",
"7", "debug"
]
}
# add a label for classifications
translate {
field => "classification"
destination => "classification"
dictionary => [
"0", "application",
"1", "malware",
"2", "protection"
]
override => true
}
# convert types
mutate {
convert => {
"dstport" => "integer"
"srcport" => "integer"
"origdstport" => "integer"
"modsrcport" => "integer"
"pri" => "integer"
"ipv" => "integer"
"slotlevel" => "integer"
"rcvd" => "integer"
"sent" => "integer"
"ruleid" => "integer"
"duration" => "float"
}
}
# geolocalize IP addresses SRC
if "" in [src] {
cidr {
address => [ "%{[src]}" ]
network => [ "0.0.0.0/32", "10.0.0.0/8", "172.16.0.0/12", "192.168.0.0/16", "fc00::/7", "127.0.0.0/8", "::1/128","169.254.0.0/16", "fe80::/10","224.0.0.0/4", "ff00::/8","255.255.255.255/32" ]
add_tag => "src_private"
}
if "src_private" not in [tags] {
geoip {
add_tag => "src_geoip"
source => "src"
target => "tmp_geoip"
add_field => { "src_location" => "%{[tmp_geoip][location][lon]}" }
add_field => { "src_location" => "%{[tmp_geoip][location][lat]}" }
}
mutate {
convert => { "src_location" => "float" }
}
mutate {
remove_field => "tmp_geoip"
}
}
}
# geolocalize IP addresses DST
if "" in [dst] {
cidr {
address => [ "%{[dst]}" ]
network => [ "0.0.0.0/32", "10.0.0.0/8", "172.16.0.0/12", "192.168.0.0/16", "fc00::/7", "127.0.0.0/8", "::1/128","169.254.0.0/16", "fe80::/10","224.0.0.0/4", "ff00::/8","255.255.255.255/32" ]
add_tag => "dst_private"
}
if "dst_private" not in [tags] {
geoip {
add_tag => "dst_geoip"
source => "dst"
target => "tmp_geoip"
add_field => { "dst_location" => "%{[tmp_geoip][location][lon]}" }
add_field => { "dst_location" => "%{[tmp_geoip][location][lat]}" }
}
mutate {
convert => { "dst_location" => "float" }
}
mutate {
remove_field => "tmp_geoip"
}
}
}
# geolocalize IP addresses ORIGDST
if "" in [origdst] {
cidr {
address => [ "%{[origdst]}" ]
network => [ "0.0.0.0/32", "10.0.0.0/8", "172.16.0.0/12", "192.168.0.0/16", "fc00::/7", "127.0.0.0/8", "::1/128","169.254.0.0/16", "fe80::/10","224.0.0.0/4", "ff00::/8","255.255.255.255/32" ]
add_tag => "origdst_private"
}
if "origdst_private" not in [tags] {
geoip {
add_tag => "origdst_geoip"
source => "origdst"
target => "tmp_geoip"
add_field => { "origdst_location" => "%{[tmp_geoip][location][lon]}" }
add_field => { "origdst_location" => "%{[tmp_geoip][location][lat]}" }
}
mutate {
convert => { "origdst_location" => "float" }
}
mutate {
remove_field => "tmp_geoip"
}
}
}
# geolocalize IP addresses MODSRC
if "" in [modsrc] {
cidr {
address => [ "%{[modsrc]}" ]
network => [ "0.0.0.0/32", "10.0.0.0/8", "172.16.0.0/12", "192.168.0.0/16", "fc00::/7", "127.0.0.0/8", "::1/128","169.254.0.0/16", "fe80::/10","224.0.0.0/4", "ff00::/8","255.255.255.255/32" ]
add_tag => "modsrc_private"
}
if "modsrc_private" not in [tags] {
geoip {
add_tag => "modsrc_geoip"
source => "modsrc"
target => "tmp_geoip"
add_field => { "modsrc_location" => "%{[tmp_geoip][location][lon]}" }
add_field => { "modsrc_location" => "%{[tmp_geoip][location][lat]}" }
}
mutate {
convert => { "modsrc_location" => "float" }
}
mutate {
remove_field => "tmp_geoip"
}
}
}
}
output {
elasticsearch {
hosts => ["localhost:9200"]
manage_template => true
index => "firewall_%{logtype}_%{+YYYY_MM}"
document_type => "logs"
}
stdout { codec => rubydebug }
}
Revenons sur la géolocalisation des adresses IP :
if "" in [src] {
cidr {
address => [ "%{[src]}" ]
network => [ "0.0.0.0/32", "10.0.0.0/8", "172.16.0.0/12", "192.168.0.0/16", "fc00::/7", "127.0.0.0/8", "::1/128","169.254.0.0/16", "fe80::/10","224.0.0.0/4", "ff00::/8","255.255.255.255/32" ]
add_tag => "src_private"
}
if "src_private" not in [tags] {
geoip {
add_tag => "src_geoip"
source => "src"
target => "tmp_geoip"
add_field => { "src_location" => "%{[tmp_geoip][location][lon]}" }
add_field => { "src_location" => "%{[tmp_geoip][location][lat]}" }
}
mutate {
convert => { "src_location" => "float" }
}
mutate {
remove_field => "tmp_geoip"
}
}
}
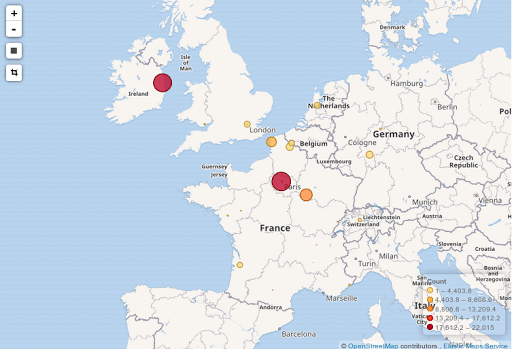
Les adresses IP internes sont exclues avec le filtre cidr, le reste est géolocalisé en utilisant le plugin Geoip filter qui interroge la base Geolite2 embarquée localement. Cette opération est répétée pour les 4 champs des adresses IP : src, dst, modsrc et, origdst.
Ne démarrez pas Logstash tout de suite, il faut d’abord préparer notre instance Elassandra.
Étape 3 : Configuration des indexes Elassandra
La différence entre Elasticsearch et Elassandra réside principalement dans la façon dont les données sont distribuées. Un cluster Elassandra fonctionne en mode peer-to-peer : tous les replicas peuvent enregistrer les écritures, éliminant ainsi le single-point-of-write de Elasticsearch. Par ailleurs, Elassandra économise de l’espace de stockage en utilisant un format binaire plus compressé pour la sérialisation des données sources.
Dans la configuration Logstash, nous avons indiqué le nom de l’index à utiliser : firewall_%{logtype}_%{+YYYY_MM}. C’est un pattern, cela signifie qu’un nouvel index sera créé chaque mois.
Le typage des champs Elasticsearch est inféré automatiquement à l’insertion du premier document. Néanmoins, nous aimerions être certains que les adresses IP et les coordonnées GPS soient reconnues comme telles. Nous allons donc définir un mapping par défaut pour tous nos futurs indexes.
Nous utilisons pour cela l’API template d’Elasticsearch :
curl -X PUT -H Content-Type:application/json localhost:9200/_template/firewall -d'
{
"template": "firewall_*",
"version": 50001,
"settings": {
"index.refresh_interval": "5s"
},
"mappings": {
"_default_": {
"properties": {
"src_location": {
"type": "geo_point"
},
"dst_location": {
"type": "geo_point"
},
"origdst_location": {
"type": "geo_point"
},
"modsrc_location": {
"type": "geo_point"
},
"src": {
"type": "ip"
},
"dst": {
"type": "ip"
},
"origdst": {
"type": "ip"
},
"modsrc": {
"type": "ip"
}
}
}
}
}'
La ligne "index.refresh_interval": "5s" permet d’économiser des ressources en diminuant le délai de rafraîchissement des indexes (par défaut 1 seconde).
Tous les composants – Rsyslog, Filebeat, Logstash et Elassandra – peuvent maintenant être démarrés.
Étape 4 : Visualisation avec Kibana
Il nous reste la partie la plus amusante : concevoir des visualisations et analyser les données avec Kibana.
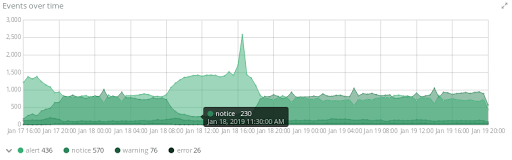
À titre d’exemple voici quelques visualisations que l’on peut assembler pour créer un dashboard interactif :
- L’évolution du trafic par rapport au temps
- La répartition géographique des adresses IP externes
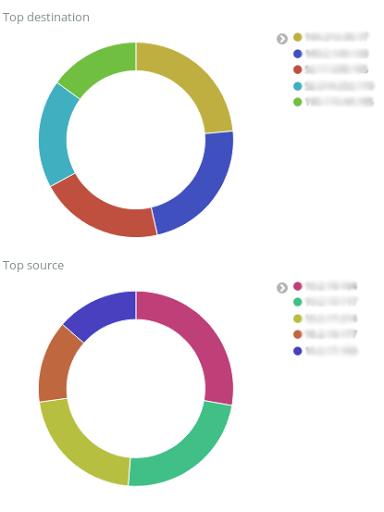
- Le top 5 des adresses IP sources et destinataires
- Le nombre d’adresses IP détectées par VLAN
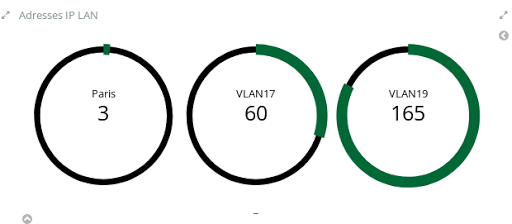
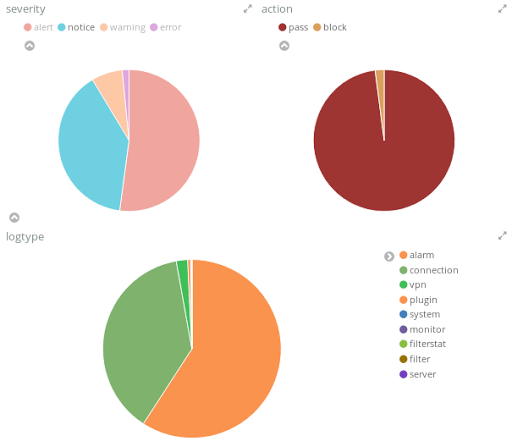
- La répartition des types d’événements
Haute disponibilité
Elassandra est un fork d’Elasticsearch modifié pour fonctionner à l’intérieur de Cassandra, le moteur NoSQL massivement distribué utilisé par Netflix, Uber ou encore Spotify.
Nous avons déployé Elassandra sur 2 serveurs, en prenant soin d’avoir un facteur de réplication cassandra à 2 (chaque noeud héberge 100% des données). Avec un Elasticsearch standard, le risque de ce genre de configuration à 2 nœuds est d’avoir un split brain, c’est à dire que les 2 nœuds Elasticsearch perdant temporairement la connectivité, se mettent à écrire chacun de leur coté des données dans les mêmes shards. Après l’incident, comme il est impossible de fusionner les documents des shards Elasticsearch ayant divergé, cela conduit à une perte de données. Dans le cas d’Elassandra, Cassandra rejoue les hint handoff, c’est à dire les données mises en attente durant 3h à destination de l’autre noeud. Si l’incident a duré plus de 3h, un cassandra repair resynchronisera les deux noeuds, et dans les deux cas, on ne pert pas de logs !
Conclusion
La suite ELK est aussi bien adaptée à la centralisation des logs applicatifs que des traces réseaux, moyennant l’intégration d’un serveur Syslog et le développement de scripts Logstash spécifiques.
Une fois les logs centralisées dans Elassandra, Kibana nous permet de construire des tableaux de bord interactifs pour faire du monitoring ou du troubleshooting. Il est également possible d’utiliser des outils comme Elastalert pour détecter des comportements anormaux (pannes, attaques DDOS, localisations suspectes, etc) et envoyer des alertes automatiquement.
Par ailleurs, pour sécuriser l’accès à ces logs, nous avons déployé le plugin Elassandra Enterprise qui assure le chiffrement TLS des connexions, l’authentification et la traçabilité des accès Elasticsearch. Pour nos administrateurs, l’utilisation de Kibana requière alors une authentification Cassandra pour accéder aux indexes Elasticsearch.

