
Cette année Reactive programming, Cloud Native, Bootiful testing, Continuous deployment … étaient les thèmes de ce Spring One Tour qui s’est déroulé les 4 et 5 décembre à Paris.
Fan de goodies, j’étais un peu déçu que les partenaires Gold (Redis Labs, Solaceo et Contrast) installés dans le hall d’accueil ne proposent pas grand chose.
Tant pis me suis-je dis et j’ai pris tranquillement le bon petit déjeuner proposé histoire d’être en forme pour attaquer cette première journée qui à la lecture du programme allait être très riche en apprentissage pour ma part.
Une fois goinfré, il était temps de rejoindre la salle de conférence, où Mark Heckler nous attendait déjà pour parler de Reactive Programming avec Spring boot 2 et Kotlin. A la suite de ce monsieur se sont succédés Josh Long, Mario Gray, Jon Schneider, et bien d’autres pour éclairer l’auditoire sur divers thèmes.
Laissez moi vous raconter un peu ce que j’ai retenu de ce Spring One Tour 2018.
– Jour 1 –
Reactive Spring with Spring Boot 2.0
In a nutshell reactive programming is about non-blocking, event-driven applications that scale with a small number of threads with backpressure as a key ingredient that aims to ensure producers do not overhelm consumers
– Rossen Stoyanchev, project reactor team –
Voici comment Marck Heckler a ouvert la présentation autour de la programmation reactive avec Spring boot 2.
Il a ensuite présenté les 4 interfaces qui composent les reactive streams, à savoir :
- Publisher<T> qui est un producteur de données
- Subscriber<T> qui consomme les données produites
- Subscription ne peut être utilisé qu’une fois par un Subscriber. Il représente le cycle de vie one-to-one d’un Subscriber s’abonnant à un Publisher
- Processor<T, R> est un type plutôt hybride car c’est une combinaison de Publisher et Subscriber.
Qu’est ce que le projet Reactor?
C’est tout simplement une implémentation des reactive streams par Pivotal.
La librairie offre deux API composables qui sont Mono (0 | 1) et Flux (N).
Mono émet 0 ou 1 élément tandis que Flux en émet N.
La suite de la présentation a été une démo plutôt intéressante en kotlin pour présenter les fonctionnalités de Reactor.
Quelques ressources pour en savoir plus sur Reactor et les reactive streams:
Cloud-Native Spring
Josh Long, Spring Developer Advocate, quant à lui s’est penché sur comment spring cloud prend en charge le développement de microservices modernes. Ce passionné n’a que très peu utilisé de slides et a surtout fait une démo dans laquelle il montre comment créer un système “reactive”.
J’ai retrouvé pour vous le même talk ici.
Bootiful Testing
Avec le TDD (Test Driven Development) on serait presque à un clic de déployer notre code en Prod selon Mario Gray. Il nous fournit des horizons imminents que nous pouvons rencontrer et mesurer. Il donne aux développeurs la confiance nécessaire pour aller plus vite tout en sachant que ce qu’ils cassent sera réparé et amélioré.
Comment testons-nous nos composants? Que se passe-t-il lorsque nous passons aux systèmes distribués et commençons à introduire des endpoints?
À quel moment de petits tests unitaires en cours de processus sont devenus des tests d’intégration distribués? Comment vous assurez-vous que le contrat entre les endpoints fonctionne tout en conservant la boucle de feedback rapide des tests unitaires?
Ce sont autant de questions que le présentateur a élucidé à travers une démo encore marqué par la programmation réactive.
Problème du TDD:
- Ne pas tester du code trivial (getters/setters)
- Vous ne pouvez pas écrire des tests qui vont couvrir le code que d’autres personnes vont écrire plus tard.
- Soyez négatif – dans vos tests – il peut être puissant de tester les entrants positifs et négatifs.
Régles du TDD:
- Vous n’êtes pas autorisé à écrire un code qui va aller en production à moins que ce soit pour faire passer un test unitaire en échec.
- Vous n’êtes pas autorisé à écrire plus d’un test unitaire que ce qui est suffisant pour le mettre en échec; les erreurs de compilation étant des échecs de tests unitaires.
- Vous n’êtes pas autorisé à écrire un code de production que ce qui est suffisant pour faire passer le seul test en échec.
Vous pourrez mieux comprendre ces problèmes posés ainsi que les règles associées en allant visiter les liens suivants:
Continuous Deployment to the Cloud
Jon Schneider a introduit son talk par une diapo qui dit:
Spinnaker is an OSS multi-cloud continuous delivery platform
Ce qui signifie que Spinnaker est une plateforme open source et multi-cloud de déploiement continue.
Il est multi-cloud car il permet un déploiement entre plusieurs fournisseurs cloud comme AWS EC2, Kubernetes, Google Cloud Platform, Google Kubernetes Engine, Microsoft Azure, et j’en passe.
Il présente un panneau de configuration centré sur l’application.
Ressources: https://www.spinnaker.io/
Open Space
L’open space est une sorte de talk improvisé où les participants proposent des sujets qu’ils souhaitent voir aborder avec quand même une proposition des organisateurs.
C’est cette formule qui a animé l’après midi. On y retrouve les mêmes intervenants de la matinée, l’occasion de poser un certain nombre de questions que l’on n’ose pas forcément poser devant une grande assemblée en conférence par exemple.
J’ai eu l’occasion d’entendre parler de RSocket, encore un bébé de Netflix, qui est un protocol binaire à utiliser sur les transports de flux d’octets tels que TCP, Websocket et Aeron. Il est plutôt adapté et surtout intéressant pour les communications applications mobile vers serveur car il gère et remonte la configuration backpressure le long du pipeline d’appel.
Pour en savoir plus, n’hésitez à aller ici.
RxJava ou Reactor proposent tous les deux, des opérateurs pour changer les lieux d’exécution ou d’écoute d’autres opérateurs. Ces opérateurs sont subscribeOn, publishOn pour Reactor ; observeOn et subscribeOn pour RxJava. Ils spécifient les types de Scheduler (io, single, newThread, compute, parallel etc.) que les prochains opérateurs devront utiliser pour s’exécuter.
Sachant que chaque opérateur qu’il soit de reactor ou rxJava semble utiliser le scheduler adéquat, pourquoi avoir besoin de changer parfois leurs comportements? Du moins le thread dans lequel ils doivent s’exécuter?
C’est une question que j’ai posée lors de cet open space et la réponse qu’on m’a donné est toute simple. Ces opérateurs sont utiles et leurs utilisations dépendront toujours des opérations que nous effectuons.
Exemple:
Par défaut RxJava est single-thread ce qui implique qu’un observable et la chaîne d’opérateurs que nous pouvons lui appliquer informeront ses observers sur le même thread sur lequel sa méthode subscribe () est appelée. Si nous souhaitons limiter le nombre de threads lancés en parallèle selon la capacité de note CPU, il est adéquat de changer le comportement de nos opérateurs en leur demandant d’utiliser le Scheduler compute.
J’en ai donc déduit qu’il est important de bien comprendre la nature de nos calculs/opérations pour bien utiliser les différents opérateurs qu’offrent les deux librairies.
Tenez, c’est cadeau 🙂
– https://www.baeldung.com/rxjava-schedulers
– https://projectreactor.io/docs/core/release/reference/
– https://www.aanandshekharroy.com/articles/2018-01/rxjava-schedulers
Bon aller je vais dormir, demain est un autre jour … J’ai trop réfléchi pour aujourd’hui …
– Jour 2 –
Cette journée a été plutôt marqué par le mot cloud. En gros c’était le moment de parler de PCF (Pivotal Cloud Foundry) et de Spring Cloud.
Spring Cloud Gateway
Quels sont les responsabilités d’une Gateway?
- Routing
- Security
- Monitoring
- Canarying – comprendre ce que ce que c’est
- Monolith Strangling – use case
- Resiliency
Spring Cloud Gateway Fundations a introduit le Reactive Gateway dont le principe est expliqué ci-dessous:

– Comprendre le Flow d’un Gateway –

Predicates: Path, Host, Date/Time, Method, Headers, Query Params, Cookies, etc.
Pre-filters: Headers, Path, Rate limiting, Cookies, Hystrix, etc.
Global Filters: Netty Router,Web Sockets, Load Balancer, Metrics
Post-Filters: Cookies, Headers, Status, etc.
Un Gateway peut être embarqué dans une application quand la latence est essentielle ou quand il y a un contrôle d’accès détaillé pour un service de paiement à l’utilisation.
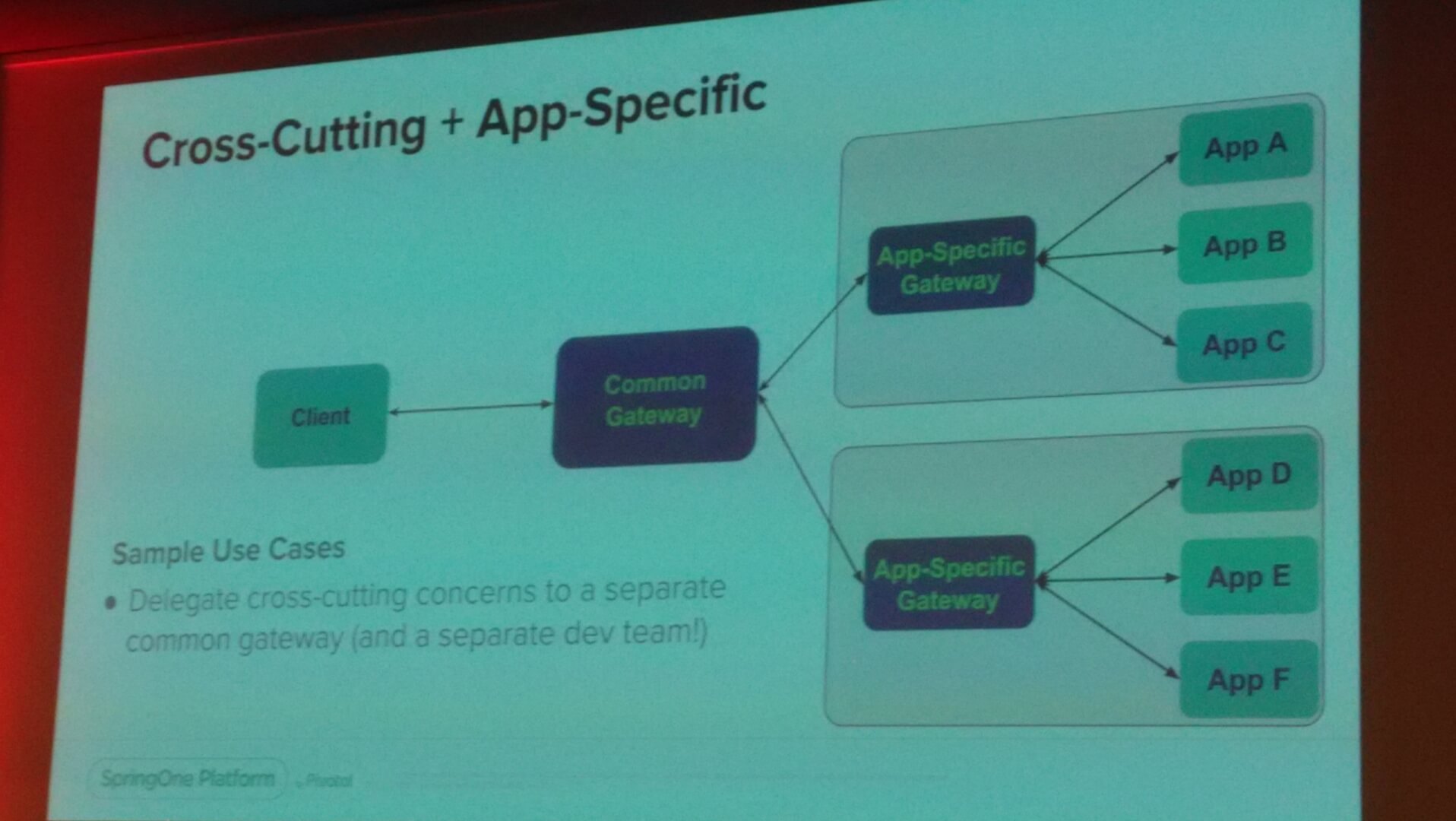
Il peut être aussi utilisé en façade pour prévenir les accès directs aux applications, mais aussi pour les cas de Cross-Cutting concerns (préoccupations transversales), pour présenter une API commune à des clients, et pour protéger des clients lors de refactoring d’applications (Monolith -> Mircoservices)
On peut encore trouver un cas d’utilisation qui est d’avoir une Gateway commune et d’autres qui seront spécifiques aux applications.
An Introduction to Project riff, a FaaS Built on Top of Knative
Kubernetes est devenu en quelques temps l’orchestrateur de conteneurs privilégié des entreprises. Plusieurs outils ou plateformes l’utilise donc pour fournir un ensemble de services.
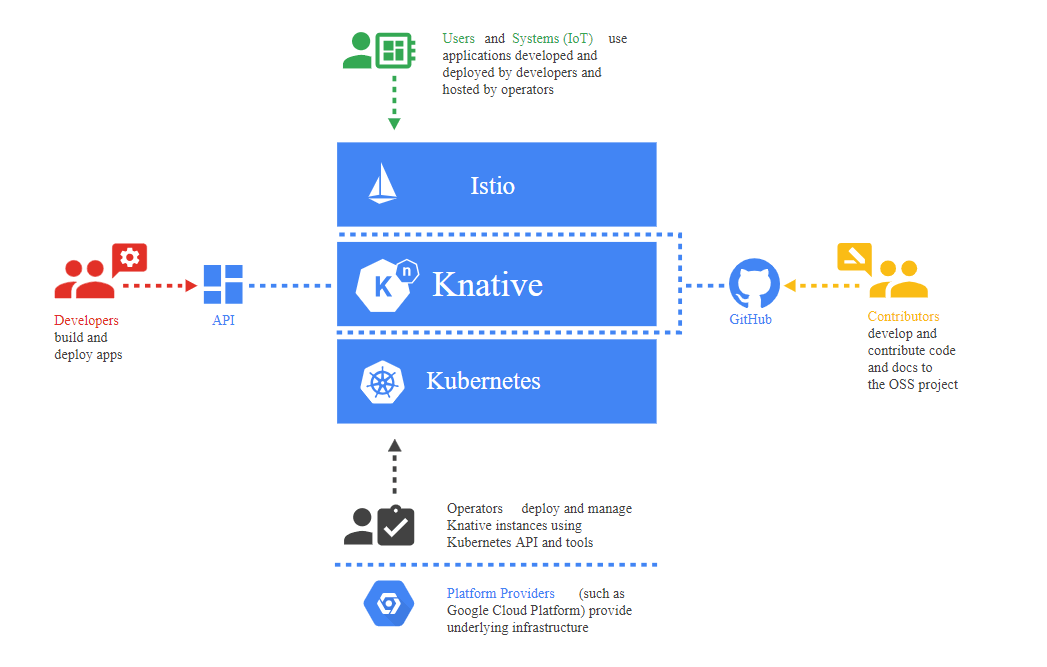
C’est le cas de Knative qui est un projet débuté par Google au début de l’année 2018 et est considéré comme une plateforme de plateformes. Les contributeurs majeurs sont Pivotal, Redhat et IBM.
Prononcé kay-nay-tiv, il étend Kubernetes pour codifier les bonnes pratiques et se concentrer sur la résolution de nombreuses tâches banales mais difficiles comme:
- Orchestrer les workflows source-to-URL dans Kubernetes
- Router et manager le trafic avec le déploiement Blue/Green
- Le scaling automatique et le dimensionnement des charges de travail à la demande.
- Relier les services qui sont lancés aux écosystèmes de monitoring.
Les composants de Knative sont:
- Serving – Modèle de calcul basé sur les requêtes pouvant aller jusqu’à zéro.
- Build – Orchestration du build source-to-container
- Eventing – Gestion et livraison des événements.
Audience:
Le serverless, permet de builder et d’exécuter des applications et des services sans se soucier des serveurs. On entend souvent parler des fonctions quand on parle de serverless et la contribution de Pivotal au mouvement des fonctions est riff, un projet open-source, récemment dévoilé sur la plate-forme SpringOne.
Riff est un FAAS au dessus de Knative.
- FAAS (Function as a service) basé sur les événements – Expérience d’opinion construite sur Knative, Istio et Kubernetes
- Les fonctions utilisent l’inversion de contrôle – Pas de serveurs, de ports ou HTTP, juste de la logique
- Choix du langage d’exécution – Java/Spring, Javascript/Node, …
Riff sur Knative, voici ce que ça donne:

Le sujet Riff pourrait faire l’objet d’un article complet. Donc je vous invite à aller sur les liens suivants pour en savoir plus:
- https://content.pivotal.io/slides/an-introduction-to-project-riff-a-faas-built-on-top-of-knative-eric-bottard
- https://m.chmarny.com/build-deploy-manage-modern-serverless-workloads-using-knative-on-kubernetes-180c1a55e1b5
- https://projectriff.io/
- https://cloud.google.com/knative/
- https://github.com/knative/docs/
Spring Boot & Spring Cloud on Pivotal Application Service
Ce talk a été plutôt une vue d’ensemble de ce qu’on peut faire sur Pivotal Cloud Foundry.
Je vous laisse regarder la présentation ici si le sujet vous intéresse.
Using Spinnaker to Create a Development Workflow on Kubernetes
Ce talk a essayé de mettre en valeur la puissance de Spinnaker dans une démo qui a plutôt séduit l’auditoire.
Voici quelques liens pour se lancer … :
- https://cloud.google.com/solutions/continuous-delivery-spinnaker-kubernetes-engine
- https://content.pivotal.io/blog/deploying-software-on-pks-creating-a-continuous-delivery-pipeline-with-spinnaker
Evolving to Cloud-Native
Chaque organisation a au moins une ou deux phalanges dans le cloud et cela modifie de manière compréhensible la manière dont nous concevons nos systèmes. Mais votre portefeuille d’applications regorge de systèmes «patrimoniaux» qui remontent à l’époque antérieure à tout.
Ce talk proposé par Nathaniel Schutta a exploré les stratégies, les outils et les techniques que nous pouvons appliquer au fur et à mesure que nous évoluons vers le cloud natif.
C’est par ici pour les slides.
Flight of the Flux: A Look at Reactor’s Execution Model
Le principe du reactive est rien ne se passe jusqu’à ce qu’on l’on souscrive, temps d’assemblage vs temps d’exécution.
Cold ou Hot sequences, Concurrent agnostic, Schedulers, PublishOn vs SubscribeOn, l’opérateur Fusion, Simon Baslé a tenu à faire le point sur ces différentes questions.
Une séquence est dite Cold, lorsqu’elle émet les mêmes données pour chaque abonné c’est à dire qu’elle recommence à zéro pour chaque abonné. Par exemple, si la source encapsule un appel HTTP, une nouvelle requête HTTP est effectuée pour chaque abonnement.
Une séquence est dite Hot quand elle commence à émettre des données dès qu’il y a une souscription. Elle ne recommence pas à zéro pour chaque abonné. Certains flux réactifs à chaud peuvent mettre en cache ou rejouer l’historique des émissions totalement ou partiellement. D’un point de vue général, une séquence dynamique peut même émettre lorsqu’aucun abonné n’écoute (une exception à la règle “rien ne se passe avant de s’abonner”).
Les opérateurs PublishOn et SubscribeOn:
publishOn s’applique de la même manière que tout autre opérateur, au centre de la chaîne d’abonnés. Il prend des signaux en amont et les rejoue en aval lors de l’exécution du rappel sur un opérateur à partir du scheduler associé. Par conséquent, le lieu d’exécution des opérateurs suivants est affecté (jusqu’à ce qu’un autre publishOn soit chaîné).
- change le contexte d’exécution en un thread choisi par le scheduler
- selon la spécification, onNext arrive en séquence, donc cela utilise un seul thread
- à moins qu’ils ne travaillent sur un scheduler spécifique, les opérateurs, après publication, continuent l’exécution sur le même thread.
subscribeOn quant à lui, s’applique au processus d’abonnement, lorsque cette chaîne en arrière est construite. En conséquence, quel que soit le lieu où vous placez le subscribeOn dans la chaîne, cela affecte toujours le contexte de l’émission source. Toutefois, cela n’affecte pas le comportement des appels ultérieurs à publishOn. Ils changent toujours le contexte d’exécution pour la partie de la chaîne qui les suit.
- change le fil de discussion auquel toute la chaîne d’opérateurs ci-dessus est abonnée
- choisit un thread du scheduler
Liens:
- https://content.pivotal.io/springone-platform-2018/flight-of-the-flux-a-look-at-reactor-execution-model
- https://projectreactor.io/docs/core/release/reference/
- https://www.slideshare.net/SpringCentral/flight-of-the-flux-a-look-at-reactor-execution-model
Cloud Event Driven Architectures with Spring Cloud Stream 2.0
Le cloud est un écosystème qui intègre les plates-formes et les intergiciels dans un environnement d’exécution hybride cohérent (messaging, file system, databases, etc.).
Il sous-traite l’infrastructure au fournisseur de cloud via des connecteurs / services de cloud, fournit un mécanisme permettant aux services d’application (clients) d’interagir avec les services cloud. Il est orienté événement.
Spring cloud stream est un framework permettant de créer des microservices hautement évolutifs, pilotés par des événements et connectés à des systèmes de messagerie partagés.
Il fournit un modèle de programmation flexible basé sur les idiomes et les meilleures pratiques Spring déjà établis et familiers, y compris la prise en charge de la sémantique persistante pub/sub, des groupes de consommateurs et des partitions avec état.
Oleg Zhurakousky à travers ses slides, a tenté de démystifier le framework.
Liens:
- https://cloud.spring.io/spring-cloud-stream/
- https://github.com/spring-cloud/spring-cloud-stream
- https://github.com/spring-cloud/spring-cloud-stream-binder-kafka
Quelles journées, n’est-ce pas?
Spring à travers Pivotal est définitivement un formidable écosystème, toujours à jour avec l’avancée IT et ses nouveautés, dans lequel on trouve un peu de tout: Cloud, Build, Run …
Ces deux journées, très enrichissantes, m’ont donné quelques sujets à creuser (je vous conseille d’ailleurs d’y penser …).
- Mettre Spinnaker en bout de pipeline Jenkins, ça pourrait être intéressant non?
- Utiliser Keycloak pour gérer les autorisations ainsi que l’authentification, ne bloquerait-il pas la chaine du full reactive? Si c’est le cas, que fait-on?
- Si mon client web s’abonne à ma source de donnée reactive, comment gérer le backpressure à ce niveau? RSocket?
Chez INEAT nous vous proposons déjà quelques billets sur des technologies Spring :
- https://blog.ineat-group.com/2018/02/spring-cloud-partie-1-initialisation-du-projet-et-mise-en-place-du-registre-de-services/
- https://blog.ineat-group.com/2018/06/spring-cloud-partie-2-definition-du-point-dentree-et-externalisation-des-configurations/
- https://blog.ineat-group.com/2018/11/securisez-vos-apis-spring-avec-keycloak-5-mise-en-place-dune-authentification-multi-domaines/
Vivement l’année prochaine !
