Cet article est la seconde partie de : Concourse CI : partie 1 – Les fondamentaux.
Dans cette partie nous allons mettre en place un pipeline visant a builder une application simpliste. Le projet qui servira de base pour cette mise en pratique est une simple TodoList.
PREREQUIS
Pour suivre ce tutoriel il est nécessaire d’installer les outils suivant :
docker (version utilisée : 18.05)
docker-compose (version utilisée : 1.21.2)
jdk (version utilisée : 8)
Le projet est composé de deux parties :
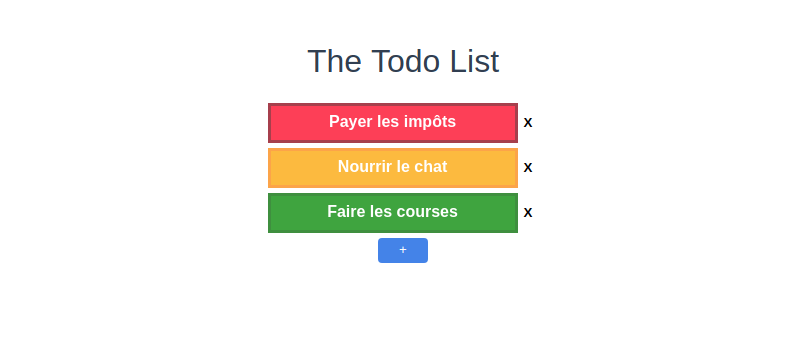
- Le front, développé avec VueJs, permet de lister l’ensemble des tâches composant la TodoList. L’ ajout d’une nouvelle “Todo” se fait via le bouton
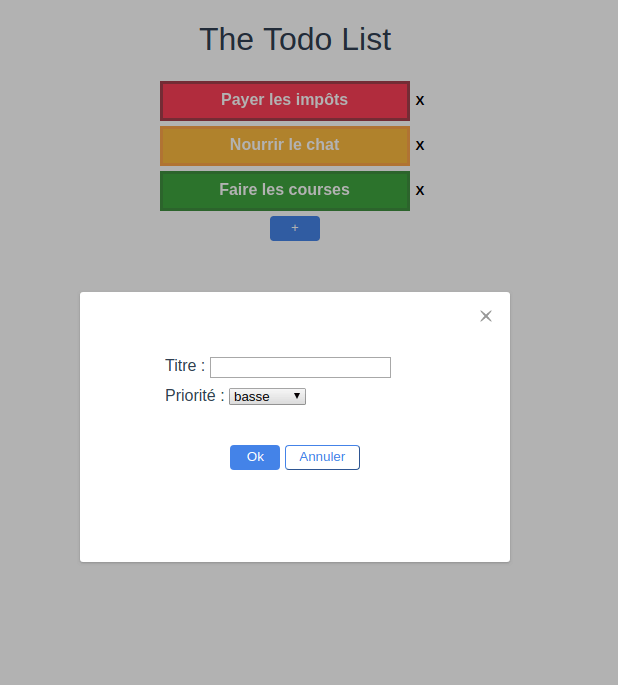
 . Lors d’un clic, il affichera une modale permettant de renseigner le titre et la priorité de la Todo. C’est cette priorité qui permet d’afficher une Todo en rouge (priorité 3, haute), orange (priorité 2, moyenne), vert (priorité 1, basse). Chaque Todo dispose d’un bouton
. Lors d’un clic, il affichera une modale permettant de renseigner le titre et la priorité de la Todo. C’est cette priorité qui permet d’afficher une Todo en rouge (priorité 3, haute), orange (priorité 2, moyenne), vert (priorité 1, basse). Chaque Todo dispose d’un bouton  permettant de supprimer une Todo. Le front sera buildé et mis à disposition sous la forme d’une image Docker.
permettant de supprimer une Todo. Le front sera buildé et mis à disposition sous la forme d’une image Docker.
- Le back, quant à lui, a été développé en Java avec Vertx. Le projet est constitué de deux modules :
- Le premier est “utilitaire” et contient les classes permettant l’accès aux données (stockées dans une base H2 exposée par un conteneur tier).
- Le second module contient l’API REST qui permet l’ajout d’une Todo, la suppression, le listing… Ce module utilise les “Utils” du premier module et sera également packagé sous la forme d’une image Docker (et poussé sur Nexus).
D’ordinaire je détaille le code source, mais le but ici n’est pas de faire une démonstration de VueJs ou de Vertx, mais bel et bien d’illustrer le fonctionnement de Concourse CI. Vous trouverez le code source des applications aux liens suivants :
- https://github.com/mderacc/concourse-demo-todo-app-front – Partie front
- https://github.com/mderacc/concourse-demo-todo-app-back – Partie back
Nous allons dans un premier temps mettre en place une première version du pipeline permettant de builder et packager les deux applications. Nous verrons ensuite comment optimiser et épurer le contenu du fichier Yaml. Les plus motivés pourront également faire évoluer le pipeline afin de packager en Jar le module “Utils” de la partie back et le mettre à disposition sur Nexus. Ainsi, si nous souhaitons profiter des fonctionnalités offertes par ce module sur nos futurs projets nous n’aurons qu’une dépendance à ajouter au pom.xml.
Mise en place de l’usine de build
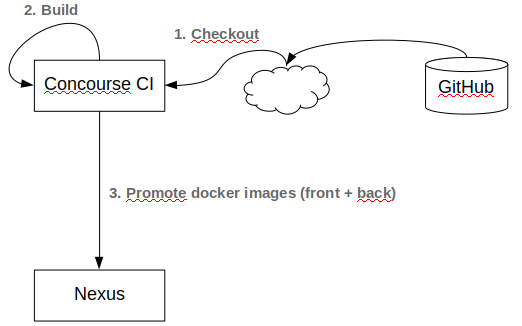
Avant de nous lancer dans la création de notre pipeline, il est nécessaire d’installer les différentes entités composant notre petite infrastructure. Nous disposons d’un repository GitHub sur lequel se trouve le code de notre application “TodoList”. Pas d’installation nécessaire côté SCM. Nous aurons cependant besoins d’une registry sur laquelle référencer les images docker qui seront produites par notre pipeline. Divers solutions existent, mon choix s’est porté sur Nexus 3 qui a l’avantage de fournir gratuitement une registry pour image Docker (contrairement à Jfrog Artifactory par exemple). Etant ici dans un contexte de démonstration, nous utiliserons une image docker permettant de démarrer un serveur Nexus facilement :
$ docker pull sonatype/nexus3 $ mkdir /some/dir/nexus-data && chown -R 200 /some/dir/nexus-data $ docker run -d -p 8081:8081 --name nexus -v /some/dir/nexus-data:/sonatype-work sonatype/nexus3
Les trois lignes précédentes permettent de récupérer l’image nécessaire à la création de notre conteneur Nexus, de créer un répertoire qui sera ensuite monté en tant que volume lors de la création du conteneur (Nexus y stockera ses données). De cette façon, si le conteneur doit être redémarré, les données ne seront pas perdues.
De la même façon nous utiliserons Docker pour instancier Concourse. Pivotal met à disposition un fichier docker-compose facilitant cette opération :
$ wget https://concourse-ci.org/docker-compose.yml $ docker-compose up -d
Notre Nexus est désormais disponible à l’adresse http://127.0.0.1:8081 (les identifiants par défaut sont admin / admin123).
De même nous pouvons nous connecter à Concourse via http://127.0.0.1:8080/.
Nous obtenons l’infrastructure suivante :
Un premier pipeline
Pour que notre pipeline fonctionne, nous avons besoin de récupérer un certain nombre de données (notamment le code source des applications). On commence donc par définir quelques resources :
resources:
- name: todo-front-resource
type: git
source:
branch: master
uri: https://github.com/mderacc/concourse-demo-todo-app-front
- name: nexus-docker-repo-front
type: docker-image
source:
repository: todo-front:8181/todo-front
- name: nexus-docker-repo-back
type: docker-image
source:
repository: todo-back:8282/todo-back
- name: todo-back-resource
type: git
source:
branch: master
uri: https://github.com/mderacc/concourse-demo-todo-app-back
Quatre resources seront utiles. todo-front-resource et todo-back-resource permettront de récupérer le code source du front et du back depuis Github. Les paramètres branch et uri sont présents afin de spécifier la branche à récupérer (ici master) et l’adresse du repository.
Les deux autres resources (nexus-docker-repo-front et nexus-docker-repo-back) ne seront pas utilisées pour faire un checkout mais pour pousser les images construites par notre pipeline sur Nexus (deux registries ont été créées à cet effet en suivant cette documentation : https://blog.sonatype.com/using-nexus-3-as-your-repository-part-3-docker-images).
On poursuit en créant le job à proprement parlé :
jobs:
- name: main-job
plan:
- get: todo-front-resource
trigger: true
- task: build-task-front
config:
platform: linux
image_resource:
type: docker-image
source:
repository: node
inputs:
- name: todo-front-resource
outputs:
- name: todo-front-build-output
run:
path: sh
args:
- -exc
- |
cd todo-front-resource
npm install
npm run build
cp -r dist ../todo-front-build-output
cp Dockerfile ../todo-front-build-output
echo "Front : build task completed"
- put: nexus-docker-repo-front
params: {build: todo-front-build-output}
Ici on définit un plan qui commencera par récupérer les sources du front via get. Le mot clé trigger permet de spécifier que la récupération du code source et le lancement du job devront s’exécuter automatiquement lors de la modification de la ressource todo-front-resource (comprenez, à chaque commit sur le repository hébergeant les sources du front).
La première tâche build-task-front a pour but de builder le front. Elle a besoin pour cela d’accéder au code source (précédemment récupéré), on précise donc que cette task prend en inputs todo-front-resource. L’image_resource est la partie principale de la définition de la tâche, elle permet de spécifier quel type d’image docker utilise pour exécuter cette tâche. Dans notre cas, nous utiliserons une image node, puisque le front est construit avec npm. Le résultat de ce build devra être “sauvegardé” dans les outputs, pour que les autres steps puissent l’utiliser notamment lors de la construction de l’image docker (souvenez vous de ce qui a été dit précédemment, les tasks sont exécutées dans des conteneurs docker et sont donc stateless !).
La dernière partie de cette tâche comporte toutes les actions à exécuter afin de construire le front. Il s’agit ici de lignes de script sh directement écrites dans le pipeline. Pour plus de lisibilité, nous aurions pu les écrire dans un fichier à part et le lier à notre pipeline avec l’instruction path (suivi du chemin vers notre fichier sh).
Ces lignes permettent la construction de l’application VueJs, et copient le résultat dans todo-front-build-output. De la même manière le Dockerfile, permettant de construire l’image, sera déposé dans ce répertoire.
La dernière étape est un put sur nexus-docker-repo-front, prenant en paramètre todo-front-build-output (le répertoire dans lequel les outputs ont été sauvegardé). Cette step est en quelque sorte un alias pour notre pipeline, puisqu’elle va à la fois générer l’image à partir du Dockerfile (qui a été copié dans todo-front-build-output), et la déposer dans notre registry (accessible via la ressource nexus-docker-repo-front).
La construction du front est maintenant spécifiée. Nous ajoutons le code suivant au job main-job :
- get: todo-back-resource
trigger: true
- task: build-task-back
config:
platform: linux
image_resource:
type: docker-image
source:
repository: maven
inputs:
- name: todo-back-resource
outputs:
- name: todo-back-build-output
run:
path: sh
args:
- -exc
- |
cd todo-back-resource
mvn install
cp todoappback/target/back-1.0-SNAPSHOT-fat.jar ../todo-back-build-output
cp todoappback/Dockerfile ../todo-back-build-output
- put: nexus-docker-repo-back
params: {build: todo-back-build-output}
Cette partie fera sensiblement la même chose que la précédente. Une des principales différence réside dans l’image utilisée. Ici une image maven est employée puisque le back est codé en Java et le Jar généré avec Maven.
Nous pouvons a présent lancer notre pipeline. On commence par le référencer dans Concourse :
sudo fly -t todo-target set-pipeline -p todo-list-pipeline -c pipeline.yml
L’option -t est utilisée pour spécifier la target, le -p pour préciser le nom du pipeline qui sera créé et le -c le fichier a utiliser pour créer ce pipeline.
Cette commande permet de faire deux choses :
- Si le pipeline n’existe pas dans Concourse alors celui-ci est automatiquement créé ;
- Si le pipeline existe déjà, la commande aura pour effet de le mettre à jour (les changements réalisés sur le fichier Yaml seront importés dans Concourse).
Un petit tour sur l’IHM nous permet de valider le fait que notre pipeline a bien été importé :
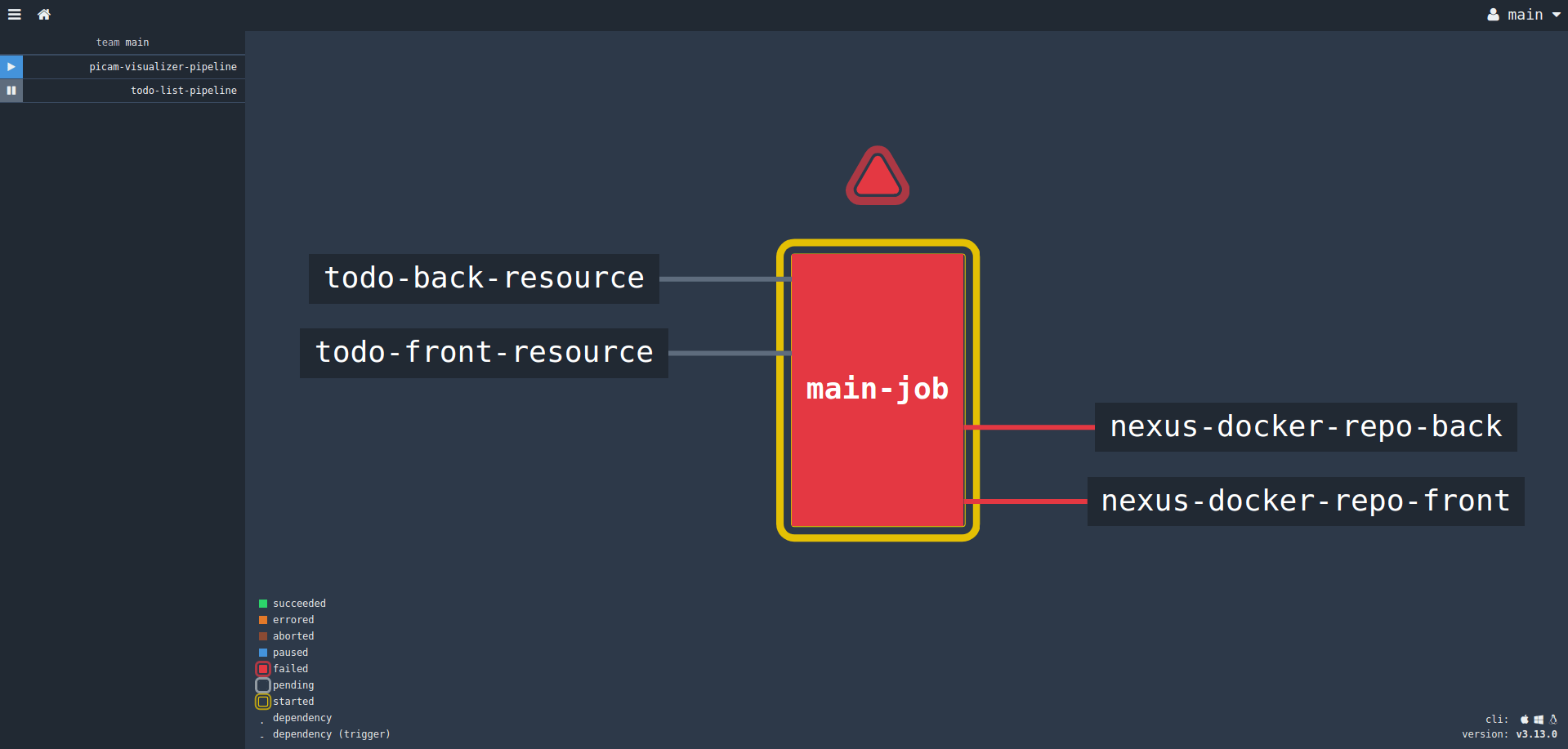
Exécutons manuellement le pipeline :
fly -t todo-target trigger-job -j todo-list-pipeline/main-job
En cliquant sur le pipeline dans l’IHM il est possible de contrôler l’exécution et visualiser les logs :
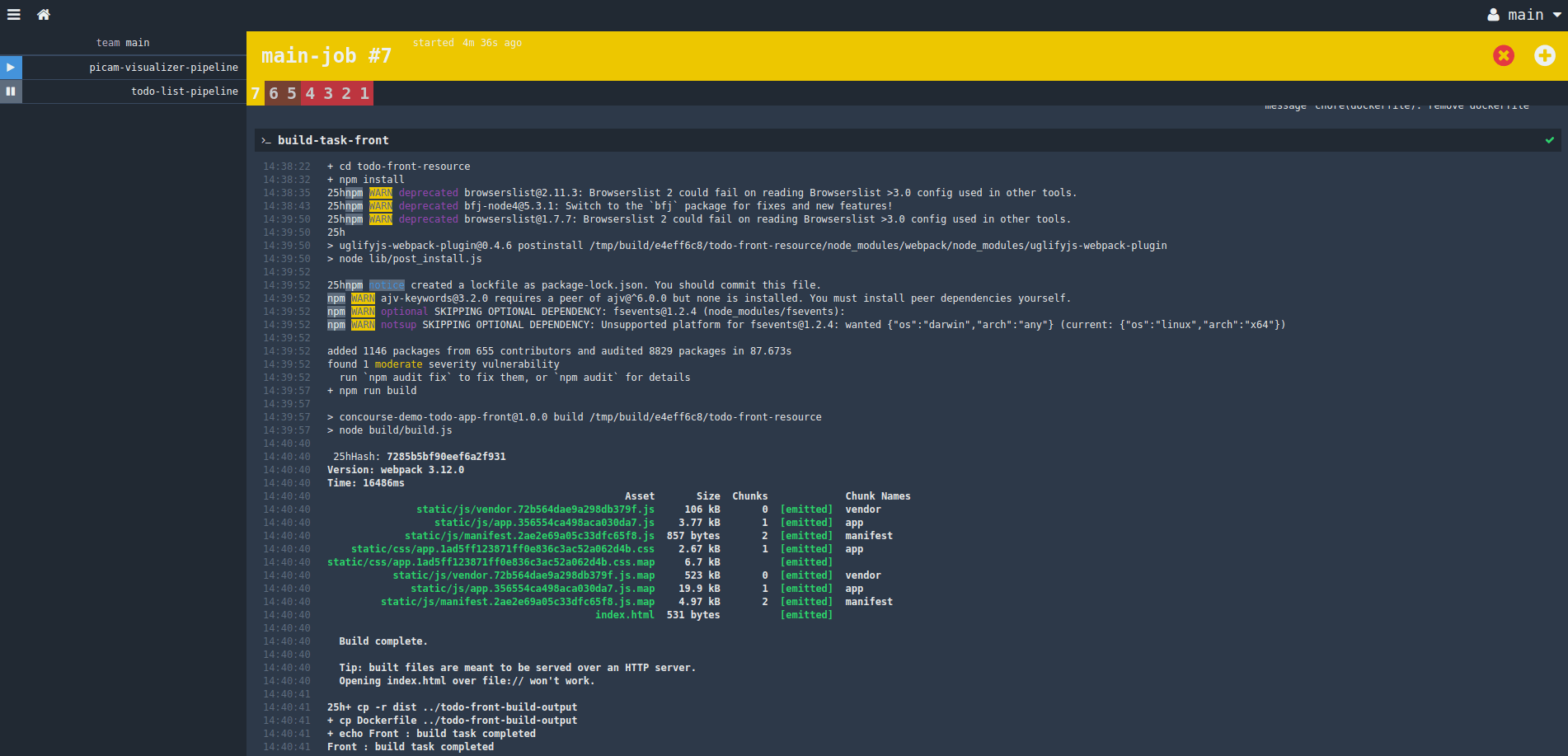
Lors du premier lancement de Concourse, il est nécessaire de créer une target :
fly --target todo-target login --concourse-url http://127.0.0.1:8080 fly --target todo-target sync
Optimisation du pipeline
La seconde version de notre pipeline sera une optimisation de la première. En effet dans la partie précédente on s’aperçoit vite que les constructions du back et du front ne sont pas liées et que par conséquent il serait tout à fait possible de les paralléliser. Concourse fournit pour cela le mot clé aggregate qui permet d’exécuter plusieurs steps en parallèle. Si une des steps échoue, alors le résultat de l’aggregate est en erreur et par conséquent le pipeline échouera également.
En utilisant ce nouveau mot clé notre job ressemble donc à ceci (on en profite pour ré-agencer les steps entre elles) :
jobs:
- name: main-job
plan:
- aggregate:
- get: todo-back-resource
trigger: true
- get: todo-front-resource
trigger: true
- aggregate :
- task: build-task-front
config:
platform: linux
image_resource:
type: docker-image
source:
repository: node
inputs:
- name: todo-front-resource
outputs:
- name: todo-front-build-output
run:
path: sh
args:
- -exc
- |
cd todo-front-resource
npm install
npm run build
cp -r dist ../todo-front-build-output
cp Dockerfile ../todo-front-build-output
echo "Front : build task completed"
- task: build-task-back
config:
platform: linux
image_resource:
type: docker-image
source:
repository: maven
inputs:
- name: todo-back-resource
outputs:
- name: todo-back-build-output
run:
path: sh
args:
- -exc
- |
cd todo-back-resource
mvn install
cp -r todoappback/target/back-1.0-SNAPSHOT-fat.jar ../todo-back-build-output
cp todoappback/Dockerfile ../todo-back-build-output
- put: nexus-docker-repo-front
params:
build: todo-front-build-output
- put: nexus-docker-repo-back
params:
build: todo-back-build-output
La récupération des codes source et les builds seront effectués parallèlement.
Découpons notre pipeline
La syntaxe et les mots clés utilisés dans notre fichier Yaml ne sont pas particulièrement difficile à assimiler, néanmoins, découper notre fichier est une bonne pratique et en facilite la lisibilité. On peut imaginer avoir un fichier principal, faisant appel à d’autres fichiers dans lesquels nous aurions nos définitions des task, resources, etc.
Dans notre exemple, nous allons placer la définition des tasks dans deux fichiers (un pour la partie front et l’autre pour le back) et les placer dans un répertoire “tasks”. La troisième version de notre pipeline ressemblerait donc à ceci :
resources:
- name: todo-front-resource
type: git
source:
branch: master
uri: https://github.com/mderacc/concourse-demo-todo-app-front
- name: nexus-docker-repo-front
type: docker-image
source:
repository: todo-front:8181/todo-front
- name: nexus-docker-repo-back
type: docker-image
source:
repository: todo-back:8282/todo-back
- name: todo-back-resource
type: git
source:
branch: master
uri: https://github.com/mderacc/concourse-demo-todo-app-back
- name: todo-app-pipeline
type: git
source:
branch: master
uri: https://github.com/mderacc/concourse-demo-todo-app-pipeline
jobs:
- name: main-job
plan:
- aggregate:
- get: todo-back-resource
trigger: true
- get: todo-front-resource
trigger: true
- get: todo-app-pipeline
- aggregate :
- task: build-task-front
file: todo-app-pipeline/tasks/task-build-front.yml
- task: build-task-back
file: todo-app-pipeline/tasks/task-build-back.yml
params:
PACKAGE_NAME: back-1.0-SNAPSHOT-fat.jar
- put: nexus-docker-repo-front
params:
build: todo-front-build-output
- put: nexus-docker-repo-back
params:
build: todo-back-build-output
Ici nous ajoutons une nouvelle ressource (todo-app-pipeline) qui permettra de récupérer le répertoire “tasks” depuis un repository git. On remarque que le corps des différentes tasks a été remplacé par un lien vers un fichier de définition Yaml. La lecture est désormais beaucoup plus simple !
Autre point intéressant : il est possible de passer des paramètres à nos fichiers de tasks. C’est ce qui a été effectué avec le mot clé params sur la task build-task-back. On affecte à la variable PACKAGE_NAME le nom du jar qui sera généré.
Dans le fichier task-build-back.yml, nous accéderons à cette valeur via $PACKAGE_NAME.
L’intérêt principal d’employer des paramètres est que nos tâches ne seront plus fortement liées à un pipeline mais réutilisables sur différent projets.
En conclusion
Le pipeline que nous avons construit est simple et peut aisément être optimisé. Nous aurions également pu le découper différemment, avec un job pour le traitement complet du back, un autre job pour le build/promote du front, et ajouter la ligne passed: [‘job-back’] à la step get: todo-front-ressource. De cette façon, le build du front ne se ferait qu’après l’exécution du job chargé du build de la partie back (et uniquement si celui-ci réussi).
Malgré un modèle et des notions très simples, Concourse est un outil puissant qui permet de monter des pipelines complexes en peu de temps. Un point important, et qui n’a pas été précisé dans l’article, est que Concourse est très bien documenté. Sachez que le web regorge d’exemples de pipelines, et si vous souhaitez tester la solution vous trouverez facilement votre bonheur.
Quelques liens pouvant apporter des compléments d’informations :
- Concourse CI, partie 1 : https://blog.ineat-group.com/2018/08/concourse-ci-partie-1-les-fondamentaux/
- Code source de la TodoList (front) : https://github.com/mderacc/concourse-demo-todo-app-front
- Code source de la TodoList (back) : https://github.com/mderacc/concourse-demo-todo-app-back
- Code source des pipelines : https://github.com/mderacc/concourse-demo-todo-app-pipeline
- Site proposant quelques tutos bien fait sur Concourse ci : https://concoursetutorial.com