Chaque année, Alfresco organise un événement où l’ensemble de la communauté Alfresco est conviée : développeurs, administrateurs, partenaires, clients… En 2013, le format de cette conférence est passée du DevCon, assez orienté développement, au Summit, qui était plus ouvert, avec des sessions à l’intention des personnes plus fonctionnels, des clients, et des commerciaux afin de mieux mettre en avant les produits Alfresco.

INEAT Conseil, Gold Partner Alfresco, s’est donc rendu fort logiquement avec deux de ses consultants, ainsi qu’un des associés, à l’Alfresco Summit de Barcelone, du 04 au 07 Novembre.
Après une année 2013 plutôt décevante, marquée par le dur passage au Cloud et la sortie poussive de la version 4.2, les attentes étaient grandes. Nous présentons donc notre compte rendu de l’événement. Le contenu étant extrêmement dense, nous ne nous sommes focalisés que sur les points nous paraissant les plus intéressants.
Ce qu’on retient en quelques mots
Nous sommes repartis du Summit totalement reboostés par le discours et les nouveautés présentés cette année. La prestation de John Newton a été particulièrement appréciée, en nous donnant des perspectives d’avenir très intéressantes. Il a été rassurant de constater qu’Alfresco a bien compris que ses clients ne seraient pas tous amenés à aller sur le Cloud, et que les efforts serait autant fournis sur l’édition On-Premise que sur le Cloud (avec la partie de synchronisation).
News et nouveautés sur la Roadmap et produits
- Alfresco a profité de l’évènement pour communiquer à grande échelle sur les produits de l’année : Evidement, Alfresco 4.2 tout juste sorti, mais également la partie mobilité (SDK iOS et Android), le client de synchronisation (encore à l’état de test et très largement perfectible à l’heure actuelle), Alfresco Workdesk (Parfait pour le Case Management, mais au mode de licencing particulier) et sa plateforme hybride avec la synchronisation On-Premise / Cloud (Pour les workflows, la publication de documents hors du SI d’entreprise)
- Amazon AWS : Alfresco a clairement mis en avant son partenariat avec Amazon et la plateforme AWS (Amazon Web Services). Luis Sala nous a décomposé la structure AWS :
- EC2 : Mise en place d’instances virtuelles et de serveurs sur demande
- S3 : Service de stockage (10 cents par gigabit)
- RDS : Relational Database services
- VPC : Contrôle du réseau
Cet ensemble de composants Amazon permet à partir d’un fichier template, disponible sur Github, de monter en 5 minutes une instance Alfresco en cluster avec répartition de charge et gestion du failover. Cela permet aux partenaires de se focaliser sur les customisations et les développements nécessaires, et aux clients de s’assurer d’avoir une structure totalement scalable et modulable à souhait.
- Test-Drive : Cette plateforme basée sur Amazon permettra à des partenaires Alfresco de pouvoir mettre à la disposition des clients, dans un laps de temps limité, une interface Alfresco permettant de faire des « showcases » sur des produits ou addon développé. Typiquement, il est envisagé de mettre à disposition notre futur module de numérisation avancée dans Share ainsi que notre connecteur intelligent Documentum/Alfresco sur ce genre de plateforme afin de le démocratiser au plus grand nombre.
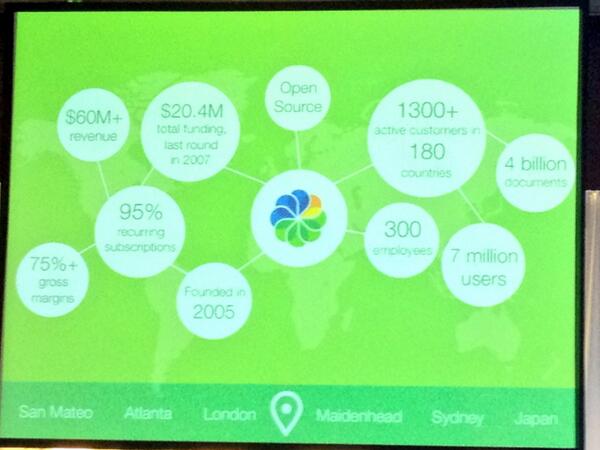
News et nouveautés sur l’administration
Comparativement aux années précédentes, on remarque la plus grande présence de sessions orientées administration. Alfresco s’attaquant à des volumétries importantes (de données, d’utilisateur et d’injections), la nécessité de pouvoir garantir un socle optimisé, sous contrôle et scalable est une vraie priorité afin de pouvoir justifier la comparaison avec les historiques du marché (Filenet, Documentum, OpenText…).
Une des sessions particulièrement riche a été celle de monitoring et d’inspection d’une instance Alfresco, puisque cela a permis de donner des outils à chaque niveau de l’architecture Alfresco :
- Pour la base de données : Utilisation du script innop ou mytop afin de récupérer des informations comme par exemple le nombre de tables impliquées dans une requêtes, ou le traitement d’une requête particulière. Jdbcspy ou log4jdbc sont des librairies à utiliser au niveau du driver de base de données d’Alfresco (fonctionnement comme un proxy) permettant de savoir par exemple le temps d’exécution nécessaire à une requête.
- Pour les index : Utilisation de Luke. A toujours utiliser sur une copie des index car il peut bloquer les éléments ou écrire. Luke permet d’apprendre les mots les plus communs, le nombre de documents total, et donc de savoir s’ils peuvent être optimisés, comment sont « tokenisées » les propriétés, quelles propriétés sont stockées etc. On peut enfin exécuter des requêtes directement au repository afin d’évaluer l’efficacité d’une requête. Il est packagé comme un fichier JAR. Il est également possible d’utiliser Checkindex pour étudier la santé des index, et voir les erreurs. Attention : il prend énormément de temps pour les indexs larges et n’est pas bon pour solutionner les corruptions d’indexes.
- Pour la partie JVM (JMX). Plusieurs solutions sont possibles : jconsole, splunk (via le plugin JMX d’Alfresco), solcarwinds, wily introscopte. Ils permettent tous de voir les personnes connectées, les nombre d’authentification ou les pools de base de données utilisés. Ils ne sont en tout cas pas représentatifs pour une utilisation d’Alfresco en backend en cas d’utilisation d’un utilisateur de service. En cas de contraintes réseaux fortes, il est recommandé d’utiliser JPS, jstacks (génération de fichiers de connections), jvmtop (fonctionne comme innop), hotthreads (utilise JMX)
- Pour Solr : utilisation des informations du sous-système directement depuis la console JMX.
- Gestion du cache : le cache est très important sur les performances, surtout pour lire les informations des nœuds Alfresco. Toutes les sous-requêtes intermédiaires sont traitées dans le cache. Il est recommandé d’utiliser EHCacheTracerJob (dump dans des fichiers de logs, mais uniquement sur un nœud, donc pas de résultats sur un cluster complet).
- Partie Web : Utilisation de Charles et Fiddler (agit comme un proxy HTTP). Le premier est payant (mais utilisable pour 30 minutes), le second est gratuit.
Pour réaliser des benchmark sur l’utilisation d’Alfresco Share, une alternative très intéressante à JMeter nous a été proposée. Il s’agit du project Webdrone, utilisé afin de mimer les interactions des utilisateurs sur Share. Il s’agit une simple librairie, incorporé à Selenium comme un webdriver. Contrairement à JMeter, sa configuration est bien plus simple et se base sur les interactions visibles de l’utilisateur.
Enfin, nous avons particulièrement apprécié la session dédiée à l’optimisation de SolR car nous avons eu beaucoup de bons conseils à mettre en pratique, parmi lesquels :
- La réduction des caches
- Gestion approprié des paramètres suivants : ramBufferSizeMB, MergeFactor (petit pour les recherches, grands pour les indexations), queryCaches, la fréquence d’indexation
- La réflexion sur des contraintes techniques telles que l’utilisation de SSL, d’indexation FT, d’archivage des indexs
- La nécessité de bien paramétré la transformation de contenus afin de ne pas avoir de goulot d’étranglement côté repository (mise en place de timeouts)
- Eviter l’utilisation de requête de type path
- Séparer la recherche de l’indexation
- Ne pas utiliser inutilement de grande valeur de heap memory
- Pensez à utiliser solRCloud pour déporter votre indexation en la rendant plus facilement scalable et performante
- Utiliser SolrMeter pour tester

News et nouveautés au niveau développement
- CMIS
INEAT Conseil utilise assez intensivement le protocole CMIS dans ses connecteurs (de dématérialisation, application iOS mobile Alfresco…). Il a donc été bon de nous rendre à la session d’introduction à CMIS par Jeff Potts. CMIS est une norme assez en vogue en ce moment puisqu’il s’agit d’un protocole d’échange documentaire normé, permettant de s’affranchir théoriquement de la solution ECM. Nous mettrons plutôt en avant les points d’attention lié à ce protocole :
- L’URL d’accès via CMIS est dépendant des versions d’Alfresco
- Les identifiants des objets CMIS sont opaques : mieux vaut pas ne pas les regarder car ils sont aléatoires
- Les requêtes CMIS sont uniquement en read-only
- CMIS 1.0 ne connait pas les aspects : Il faut dans ce cas utiliser l’extension AlfrescObjectFactoryImp qui permet de récupérer des objets Alfresco et non de simple de documents, et donc d’utiliser les aspects.
- CMIS ne sait pas ce qu’est une relation parent/enfant, à part pour un dossier contenant des documents
- CMIS ne travaille qu’avec des instances ou des extensions de documents et de dossiers
- Pas de support Atom CMIS sur la version 4.2.
- CMIS gère la lecture des ACLs, mais ne peut pas casser l’héritage comme il est possible via Share (sinon, utiliser un webscript pour le faire malheureusement).
- CMIS ne gère pas les groupes et utilisateurs, juste des documents et des dossiers
- Pas de possibilité de créer des types de documents à la volée. Pour le faire, il faut utiliser des APIs
- CMIS ne fonctionne pas avec les catégories et tags (sinon, utilisation de webscripts)
- Attentions aux solutions soit disant CMIS compliant. Car tout n’est pas supporté.
Un point très positif : Alfresco s’oriente plutôt vers la configuration plutôt que le développement. Cela s’est démontré au travers du module de workflow kickStart par exemple. On peut facilement reprocher à Alfresco de nécessiter assez rapidement des opérations techniques, qu’une personne fonctionnelle ne pourrait pas faire, pour des choses assez simples comme la création de formulaires.
Une des grandes avancées est focalisée sur le développement sous Alfresco Share. Chaque année les développeurs se plaignaient de la complexité à développer sous Alfresco Share. Désormais la grande nouveauté de ces sessions techniques est la présentation d’Alfresco Share Page et de Widget Library par Dave Draper. Les customisations de pages deviennent de plus en plus simples et facilement deployées/implémentées. On découvre une nouvelle façon de créer des objets via des widgets (ce qui nous rappelle la révolution de l’année dernière sur les développements de dashlets). Donc un widget n’est autre qu’un module composé de fichiers javascript, html, css, i18n.
widget = javascript + html + css + i18n
Les exemples de création de Menu/Sous-Menus, présentés via des démos illustrent la parfaite simplicité à développer des widgets sous Share. Cependant la bonne nouvelle est Alfresco Share Page, une interface intuitive permettant de créer dynamiquement des pages par drag and drop, sans redémarrer votre service Alfresco. En effet, depuis l’entrepôt (Data Dictionnay/SharedRessources), il serait possible de déployer vos pages. Donc avec cette nouveauté, il sera plus simple de comprendre le framework et le concept de développement de Surf.
Workflow Activiti & Kickstart : C’est LA session technique qu’il ne fallait pas rater. Contrairement au plugin Activiti Designer, KickStart permet de créer/générer d’un seul coup (model, process definition, context, formulaire de workflow …) depuis Eclipse des workflows. Frederik Heremans nous a totalement bluffé lors des phases de démonstrations live. La version bêta de ce module peut être testé sous Eclipse Juno, alors que la version finale supportera les versions Juno et Kepler.
Et INEAT dans tout ça ?
Nous n’avons pas seulement été spectateurs puisque nous avons participé à une session de présentation au Alfresco Lightning Show. Nous y avons présenté en cinq minutes chrono notre toute nouvelle application mobile Alfresco basée sur le SDK iOS d’Alfresco.

